 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Quick Red Fox gets the best Data Driven Classroom Interviews: A manual for an interview app and its associated methodology
Nov 17, 2025

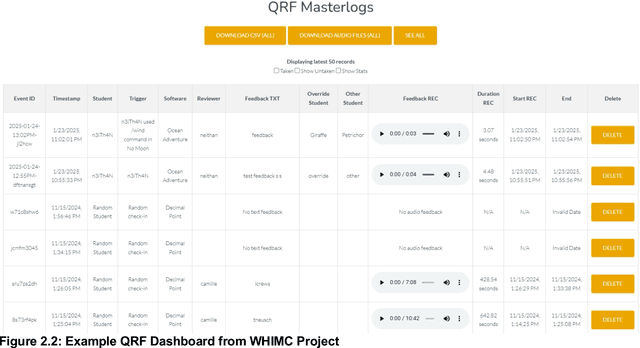

Data Driven Classroom Interviews (DDCIs) are an interviewing technique that is facilitated by recent technological developments in the learning analytics community. DDCIs are short, targeted interviews that allow researchers to contextualize students' interactions with a digital learning environment (e.g., intelligent tutoring systems or educational games) while minimizing the amount of time that the researcher interrupts that learning experience, and focusing researcher time on the events they most want to focus on DDCIs are facilitated by a research tool called the Quick Red Fox (QRF)--an open-source server-client Android app that optimizes researcher time by directing interviewers to users that have just displayed an interesting behavior (previously defined by the research team). QRF integrates with existing student modeling technologies (e.g., behavior-sensing, affect-sensing, detection of self-regulated learning) to alert researchers to key moments in a learner's experience. This manual documents the tech while providing training on the processes involved in developing triggers and interview techniques; it also suggests methods of analyses.
Towards a Unified Framework for Evaluating Explanations
May 22, 2024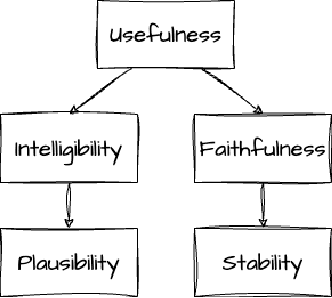
The challenge of creating interpretable models has been taken up by two main research communities: ML researchers primarily focused on lower-level explainability methods that suit the needs of engineers, and HCI researchers who have more heavily emphasized user-centered approaches often based on participatory design methods. This paper reviews how these communities have evaluated interpretability, identifying overlaps and semantic misalignments. We propose moving towards a unified framework of evaluation criteria and lay the groundwork for such a framework by articulating the relationships between existing criteria. We argue that explanations serve as mediators between models and stakeholders, whether for intrinsically interpretable models or opaque black-box models analyzed via post-hoc techniques. We further argue that useful explanations require both faithfulness and intelligibility. Explanation plausibility is a prerequisite for intelligibility, while stability is a prerequisite for explanation faithfulness. We illustrate these criteria, as well as specific evaluation methods, using examples from an ongoing study of an interpretable neural network for predicting a particular learner behavior.
Deep Learning for Educational Data Science
Apr 12, 2024With the ever-growing presence of deep artificial neural networks in every facet of modern life, a growing body of researchers in educational data science -- a field consisting of various interrelated research communities -- have turned their attention to leveraging these powerful algorithms within the domain of education. Use cases range from advanced knowledge tracing models that can leverage open-ended student essays or snippets of code to automatic affect and behavior detectors that can identify when a student is frustrated or aimlessly trying to solve problems unproductively -- and much more. This chapter provides a brief introduction to deep learning, describes some of its advantages and limitations, presents a survey of its many uses in education, and discusses how it may further come to shape the field of educational data science.
Exploring the Potential of Large Language Models in Generating Code-Tracing Questions for Introductory Programming Courses
Oct 23, 2023



In this paper, we explore the application of large language models (LLMs) for generating code-tracing questions in introductory programming courses. We designed targeted prompts for GPT4, guiding it to generate code-tracing questions based on code snippets and descriptions. We established a set of human evaluation metrics to assess the quality of questions produced by the model compared to those created by human experts. Our analysis provides insights into the capabilities and potential of LLMs in generating diverse code-tracing questions. Additionally, we present a unique dataset of human and LLM-generated tracing questions, serving as a valuable resource for both the education and NLP research communities. This work contributes to the ongoing dialogue on the potential uses of LLMs in educational settings.
Sequential pattern mining in educational data: The application context, potential, strengths, and limitations
Feb 03, 2023Increasingly, researchers have suggested the benefits of temporal analysis to improve our understanding of the learning process. Sequential pattern mining (SPM), as a pattern recognition technique, has the potential to reveal the temporal aspects of learning and can be a valuable tool in educational data science. However, its potential is not well understood and exploited. This chapter addresses this gap by reviewing work that utilizes sequential pattern mining in educational contexts. We identify that SPM is suitable for mining learning behaviors, analyzing and enriching educational theories, evaluating the efficacy of instructional interventions, generating features for prediction models, and building educational recommender systems. SPM can contribute to these purposes by discovering similarities and differences in learners' activities and revealing the temporal change in learning behaviors. As a sequential analysis method, SPM can reveal unique insights about learning processes and be powerful for self-regulated learning research. It is more flexible in capturing the relative arrangement of learning events than the other sequential analysis methods. Future research may improve its utility in educational data science by developing tools for counting pattern occurrences as well as identifying and removing unreliable patterns. Future work needs to establish a systematic guideline for data preprocessing, parameter setting, and interpreting sequential patterns.