 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-3 Powered Information Extraction for Building Robust Knowledge Bases
Jul 31, 2024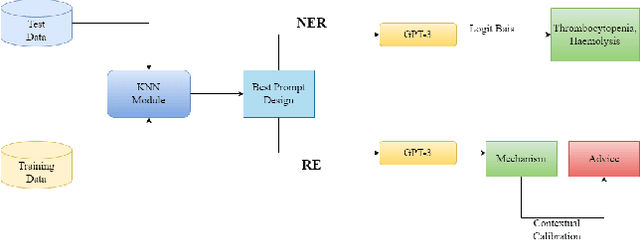
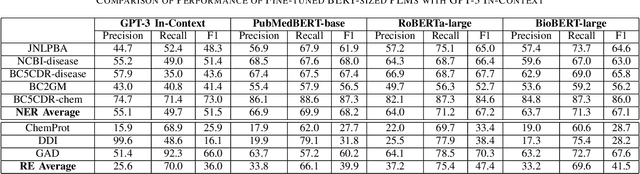
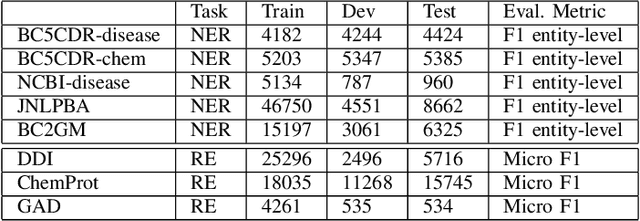
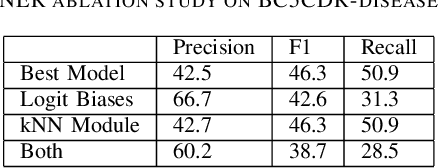
This work uses the state-of-the-art language model GPT-3 to offer a novel method of information extraction for knowledge base development. The suggested method attempts to solve the difficulties associated with obtaining relevant entities and relationships from unstructured text in order to extract structured information. We conduct experiments on a huge corpus of text from diverse fields to assess the performance of our suggested technique. The evaluation measures, which are frequently employed in information extraction tasks, include precision, recall, and F1-score. The findings demonstrate that GPT-3 can be used to efficiently and accurately extract pertinent and correct information from text, hence increasing the precision and productivity of knowledge base creation. We also assess how well our suggested approach performs in comparison to the most advanced information extraction techniques already in use. The findings show that by utilizing only a small number of instances in in-context learning, our suggested strategy yields competitive outcomes with notable savings in terms of data annotation and engineering expense. Additionally, we use our proposed method to retrieve Biomedical information, demonstrating its practicality in a real-world setting. All things considered, our suggested method offers a viable way to overcome the difficulties involved in obtaining structured data from unstructured text in order to create knowledge bases. It can greatly increase the precision and effectiveness of information extraction, which is necessary for many applications including chatbots, recommendation engines, and question-answering systems.