 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGDEGAN: Gaussian Dynamic Equivariant Graph Attention Network for Ligand Binding Site Prediction
Mar 20, 2026Accurate prediction of binding sites of a given protein, to which ligands can bind, is a critical step in structure-based computational drug discovery. Recently, Equivariant Graph Neural Networks (GNNs) have emerged as a powerful paradigm for binding site identification methods due to the large-scale availability of 3D structures of proteins via protein databases and AlphaFold predictions. The state-of-the-art equivariant GNN methods implement dot product attention, disregarding the variation in the chemical and geometric properties of the neighboring residues. To capture this variation, we propose GDEGAN (Gaussian Dynamic Equivariant Graph Attention Network), which replaces dot-product attention with adaptive kernels that recognize binding sites. The proposed attention mechanism captures variation in neighboring residues using statistics of their characteristic local feature distributions. Our mechanism dynamically computes neighborhood statistics at each layer, using local variance as an adaptive bandwidth parameter with learnable per-head temperatures, enabling each protein region to determine its own context-specific importance. GDEGAN outperforms existing methods with relative improvements of 37-66% in DCC and 7-19% DCA success rates across COACH420, HOLO4k, and PDBBind2020 datasets. These advances have direct application in accelerating protein-ligand docking by identifying potential binding sites for therapeutic target identification.
Directed Graph-alignment Approach for Identification of Gaps in Short Answers
Apr 06, 2025In this paper, we have presented a method for identifying missing items known as gaps in the student answers by comparing them against the corresponding model answer/reference answers, automatically. The gaps can be identified at word, phrase or sentence level. The identified gaps are useful in providing feedback to the students for formative assessment. The problem of gap identification has been modelled as an alignment of a pair of directed graphs representing a student answer and the corresponding model answer for a given question. To validate the proposed approach, the gap annotated student answers considering answers from three widely known datasets in the short answer grading domain, namely, University of North Texas (UNT), SciEntsBank, and Beetle have been developed and this gap annotated student answers' dataset is available at: https://github.com/sahuarchana7/gaps-answers-dataset. Evaluation metrics used in the traditional machine learning tasks have been adopted to evaluate the task of gap identification. Though performance of the proposed approach varies across the datasets and the types of the answers, overall the performance is observed to be promising.
Generation of Highlights from Research Papers Using Pointer-Generator Networks and SciBERT Embeddings
Feb 14, 2023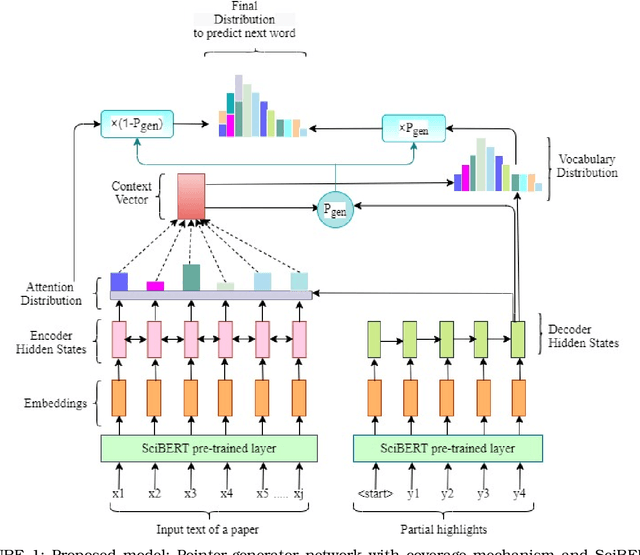
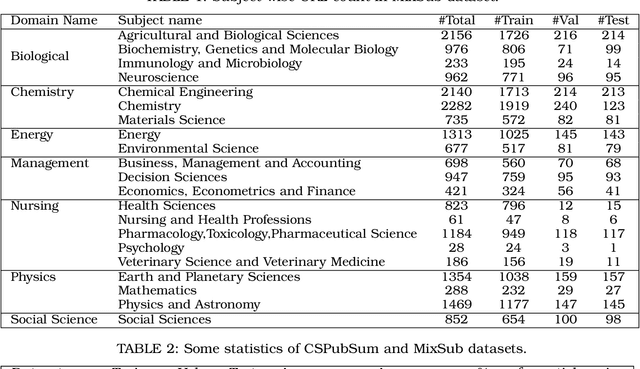

Nowadays many research articles are prefaced with research highlights to summarize the main findings of the paper. Highlights not only help researchers precisely and quickly identify the contributions of a paper, they also enhance the discoverability of the article via search engines. We aim to automatically construct research highlights given certain segments of the research paper. We use a pointer-generator network with coverage mechanism and a contextual embedding layer at the input that encodes the input tokens into SciBERT embeddings. We test our model on a benchmark dataset, CSPubSum and also present MixSub, a new multi-disciplinary corpus of papers for automatic research highlight generation. For both CSPubSum and MixSub, we have observed that the proposed model achieves the best performance compared to related variants and other models proposed in the literature. On the CSPubSum data set, our model achieves the best performance when the input is only the abstract of a paper as opposed to other segments of the paper. It produces ROUGE-1, ROUGE-2 and ROUGE-L F1-scores of 38.26, 14.26 and 35.51, respectively, METEOR F1-score of 32.62, and BERTScore F1 of 86.65 which outperform all other baselines. On the new MixSub data set, where only the abstract is the input, our proposed model (when trained on the whole training corpus without distinguishing between the subject categories) achieves ROUGE-1, ROUGE-2 and ROUGE-L F1-scores of 31.78, 9.76 and 29.3, respectively, METEOR F1-score of 24.00, and BERTScore F1 of 85.25, outperforming other models.
Segmenting Scientific Abstracts into Discourse Categories: A Deep Learning-Based Approach for Sparse Labeled Data
May 27, 2020
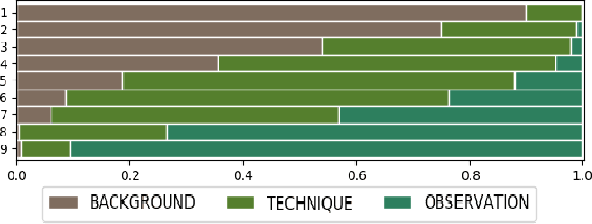
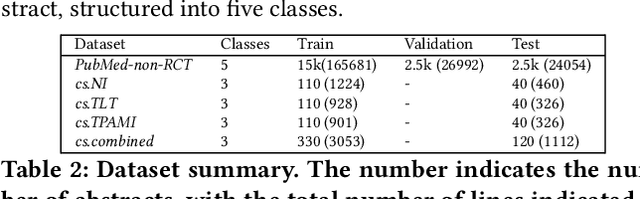
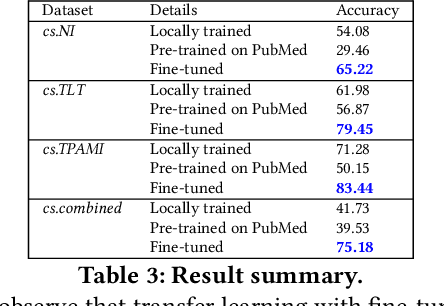
The abstract of a scientific paper distills the contents of the paper into a short paragraph. In the biomedical literature, it is customary to structure an abstract into discourse categories like BACKGROUND, OBJECTIVE, METHOD, RESULT, and CONCLUSION, but this segmentation is uncommon in other fields like computer science. Explicit categories could be helpful for more granular, that is, discourse-level search and recommendation. The sparsity of labeled data makes it challenging to construct supervised machine learning solutions for automatic discourse-level segmentation of abstracts in non-bio domains. In this paper, we address this problem using transfer learning. In particular, we define three discourse categories BACKGROUND, TECHNIQUE, OBSERVATION-for an abstract because these three categories are the most common. We train a deep neural network on structured abstracts from PubMed, then fine-tune it on a small hand-labeled corpus of computer science papers. We observe an accuracy of 75% on the test corpus. We perform an ablation study to highlight the roles of the different parts of the model. Our method appears to be a promising solution to the automatic segmentation of abstracts, where the labeled data is sparse.