 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt2LVideos: Exploring Prompts for Understanding Long-Form Multimodal Videos
Mar 11, 2025Learning multimodal video understanding typically relies on datasets comprising video clips paired with manually annotated captions. However, this becomes even more challenging when dealing with long-form videos, lasting from minutes to hours, in educational and news domains due to the need for more annotators with subject expertise. Hence, there arises a need for automated solutions. Recent advancements in Large Language Models (LLMs) promise to capture concise and informative content that allows the comprehension of entire videos by leveraging Automatic Speech Recognition (ASR) and Optical Character Recognition (OCR) technologies. ASR provides textual content from audio, while OCR extracts textual content from specific frames. This paper introduces a dataset comprising long-form lectures and news videos. We present baseline approaches to understand their limitations on this dataset and advocate for exploring prompt engineering techniques to comprehend long-form multimodal video datasets comprehensively.
IPD:An Incremental Prototype based DBSCAN for large-scale data with cluster representatives
Feb 16, 2022
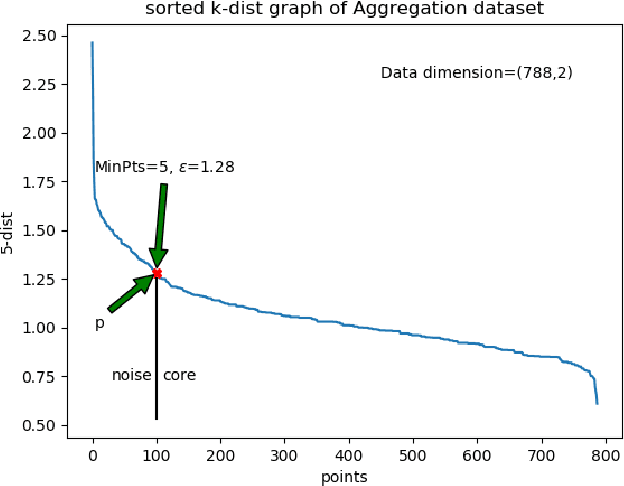
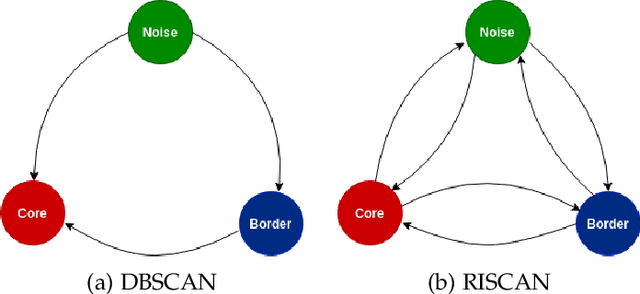
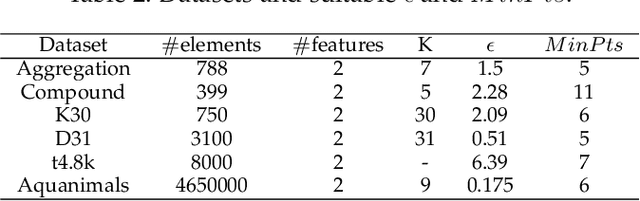
DBSCAN is a fundamental density-based clustering technique that identifies any arbitrary shape of the clusters. However, it becomes infeasible while handling big data. On the other hand, centroid-based clustering is important for detecting patterns in a dataset since unprocessed data points can be labeled to their nearest centroid. However, it can not detect non-spherical clusters. For a large data, it is not feasible to store and compute labels of every samples. These can be done as and when the information is required. The purpose can be accomplished when clustering act as a tool to identify cluster representatives and query is served by assigning cluster labels of nearest representative. In this paper, we propose an Incremental Prototype-based DBSCAN (IPD) algorithm which is designed to identify arbitrary-shaped clusters for large-scale data. Additionally, it chooses a set of representatives for each cluster.
A CNN With Multi-scale Convolution for Hyperspectral Image Classification using Target-Pixel-Orientation scheme
Feb 02, 2020


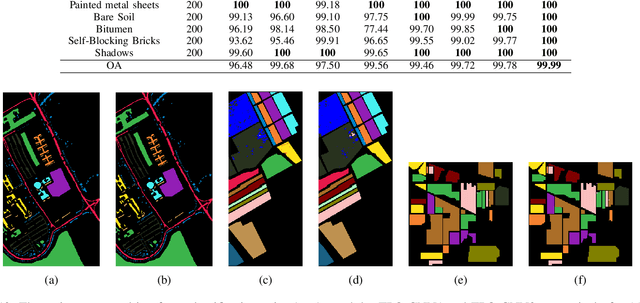
Recently, CNN is a popular choice to handle the hyperspectral image classification challenges. In spite of having such large spectral information in Hyper-Spectral Image(s) (HSI), it creates a curse of dimensionality. Also, large spatial variability of spectral signature adds more difficulty in classification problem. Additionally, training a CNN in the end to end fashion with scarced training examples is another challenging and interesting problem. In this paper, a novel target-patch-orientation method is proposed to train a CNN based network. Also, we have introduced a hybrid of 3D-CNN and 2D-CNN based network architecture to implement band reduction and feature extraction methods, respectively. Experimental results show that our method outperforms the accuracies reported in the existing state of the art methods.
CNAK : Cluster Number Assisted K-means
Nov 20, 2019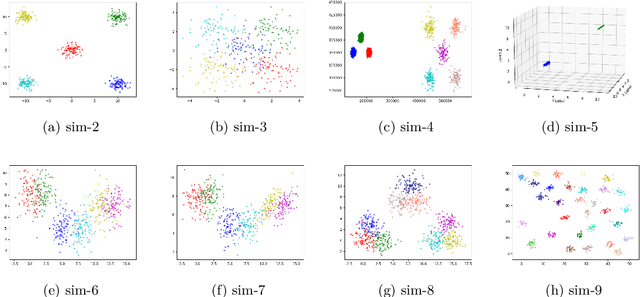
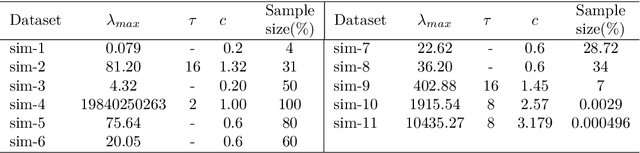
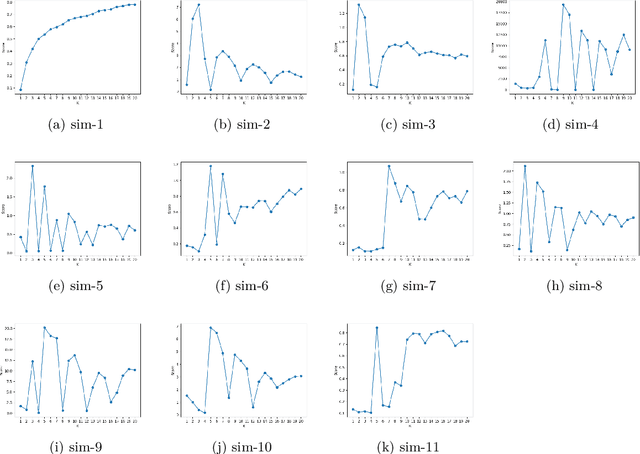
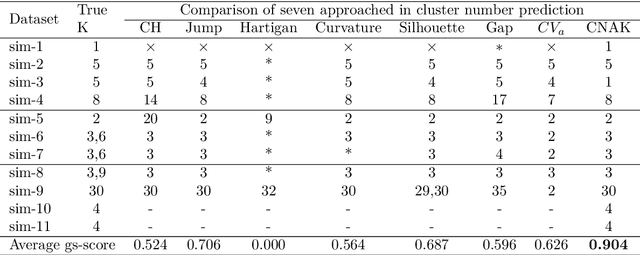
Determining the number of clusters present in a dataset is an important problem in cluster analysis. Conventional clustering techniques generally assume this parameter to be provided up front. %user supplied. %Recently, robustness of any given clustering algorithm is analyzed to measure cluster stability/instability which in turn determines the cluster number. In this paper, we propose a method which analyzes cluster stability for predicting the cluster number. Under the same computational framework, the technique also finds representatives of the clusters. The method is apt for handling big data, as we design the algorithm using \emph{Monte-Carlo} simulation. Also, we explore a few pertinent issues found to be of also clustering. Experiments reveal that the proposed method is capable of identifying a single cluster. It is robust in handling high dimensional dataset and performs reasonably well over datasets having cluster imbalance. Moreover, it can indicate cluster hierarchy, if present. Overall we have observed significant improvement in speed and quality for predicting cluster numbers as well as the composition of clusters in a large dataset.
RECAL: Reuse of Established CNN classifer Apropos unsupervised Learning paradigm
Jun 15, 2019

Recently, clustering with deep network framework has attracted attention of several researchers in the computer vision community. Deep framework gains extensive attention due to its efficiency and scalability towards large-scale and high-dimensional data. In this paper, we transform supervised CNN classifier architecture into an unsupervised clustering model, called RECAL, which jointly learns discriminative embedding subspace and cluster labels. RECAL is made up of feature extraction layers which are convolutional, followed by unsupervised classifier layers which is fully connected. A multinomial logistic regression function (softmax) stacked on top of classifier layers. We train this network using stochastic gradient descent (SGD) optimizer. However, the successful implementation of our model is revolved around the design of loss function. Our loss function uses the heuristics that true partitioning entails lower entropy given that the class distribution is not heavily skewed. This is a trade-off between the situations of "skewed distribution" and "low-entropy". To handle this, we have proposed classification entropy and class entropy which are the two components of our loss function. In this approach, size of the mini-batch should be kept high. Experimental results indicate the consistent and competitive behavior of our model for clustering well-known digit, multi-viewed object and face datasets. Morever, we use this model to generate unsupervised patch segmentation for multi-spectral LISS-IV images. We observe that it is able to distinguish built-up area, wet land, vegetation and waterbody from the underlying scene.