 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCNAK : Cluster Number Assisted K-means
Paper and Code
Nov 20, 2019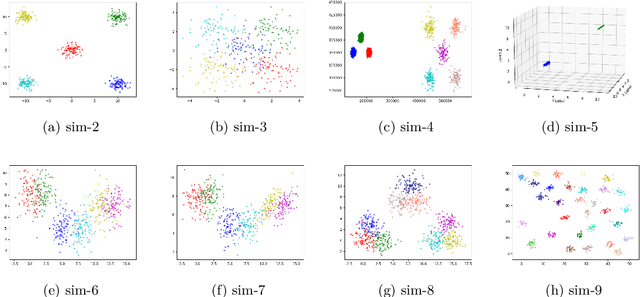
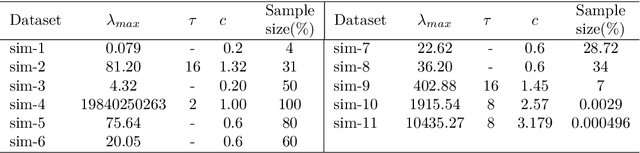
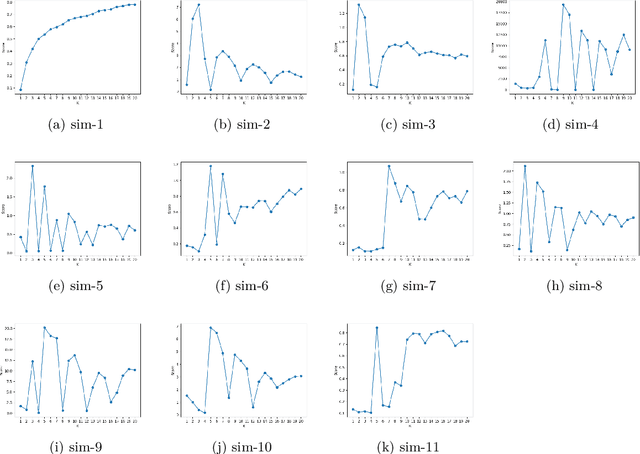
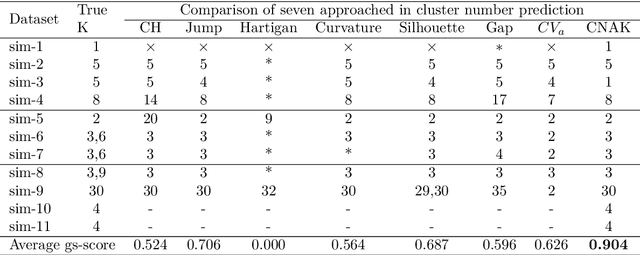
Determining the number of clusters present in a dataset is an important problem in cluster analysis. Conventional clustering techniques generally assume this parameter to be provided up front. %user supplied. %Recently, robustness of any given clustering algorithm is analyzed to measure cluster stability/instability which in turn determines the cluster number. In this paper, we propose a method which analyzes cluster stability for predicting the cluster number. Under the same computational framework, the technique also finds representatives of the clusters. The method is apt for handling big data, as we design the algorithm using \emph{Monte-Carlo} simulation. Also, we explore a few pertinent issues found to be of also clustering. Experiments reveal that the proposed method is capable of identifying a single cluster. It is robust in handling high dimensional dataset and performs reasonably well over datasets having cluster imbalance. Moreover, it can indicate cluster hierarchy, if present. Overall we have observed significant improvement in speed and quality for predicting cluster numbers as well as the composition of clusters in a large dataset.