 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information-based Generalized Category Discovery
Dec 01, 2022
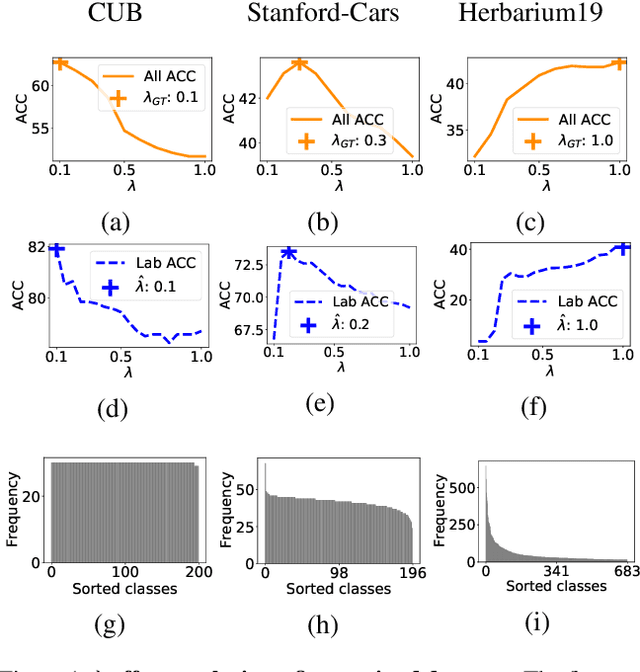


We introduce an information-maximization approach for the Generalized Category Discovery (GCD) problem. Specifically, we explore a parametric family of loss functions evaluating the mutual information between the features and the labels, and find automatically the one that maximizes the predictive performances. Furthermore, we introduce the Elbow Maximum Centroid-Shift (EMaCS) technique, which estimates the number of classes in the unlabeled set. We report comprehensive experiments, which show that our mutual information-based approach (MIB) is both versatile and highly competitive under various GCD scenarios. The gap between the proposed approach and the existing methods is significant, more so when dealing with fine-grained classification problems. Our code: \url{https://github.com/fchiaroni/Mutual-Information-Based-GCD}.
Mutual-Information Based Few-Shot Classification
Jun 23, 2021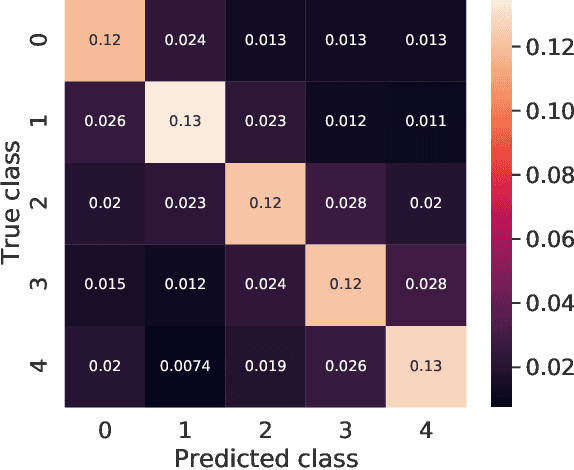
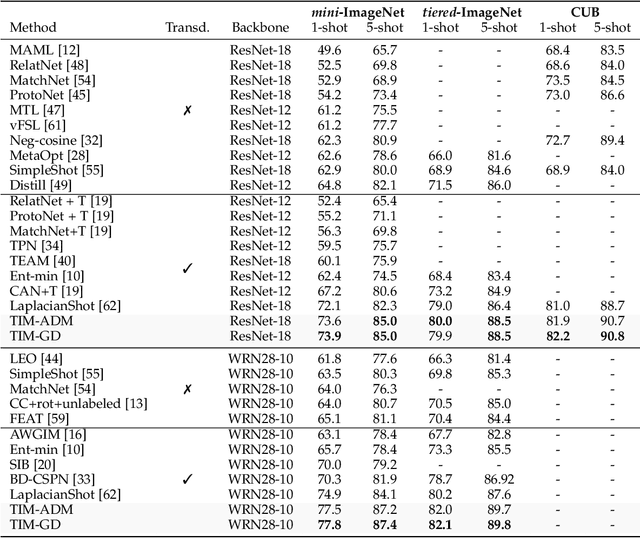
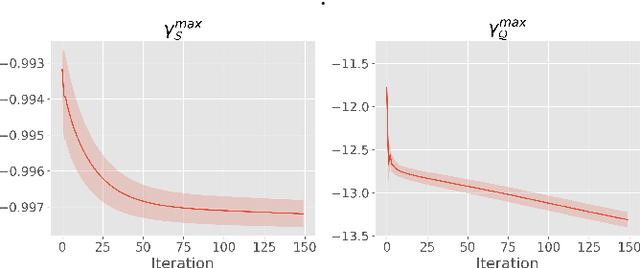

We introduce Transductive Infomation Maximization (TIM) for few-shot learning. Our method maximizes the mutual information between the query features and their label predictions for a given few-shot task, in conjunction with a supervision loss based on the support set. We motivate our transductive loss by deriving a formal relation between the classification accuracy and mutual-information maximization. Furthermore, we propose a new alternating-direction solver, which substantially speeds up transductive inference over gradient-based optimization, while yielding competitive accuracy. We also provide a convergence analysis of our solver based on Zangwill's theory and bound-optimization arguments. TIM inference is modular: it can be used on top of any base-training feature extractor. Following standard transductive few-shot settings, our comprehensive experiments demonstrate that TIM outperforms state-of-the-art methods significantly across various datasets and networks, while used on top of a fixed feature extractor trained with simple cross-entropy on the base classes, without resorting to complex meta-learning schemes. It consistently brings between 2 % and 5 % improvement in accuracy over the best performing method, not only on all the well-established few-shot benchmarks but also on more challenging scenarios, with random tasks, domain shift and larger numbers of classes, as in the recently introduced META-DATASET. Our code is publicly available at https://github.com/mboudiaf/TIM. We also publicly release a standalone PyTorch implementation of META-DATASET, along with additional benchmarking results, at https://github.com/mboudiaf/pytorch-meta-dataset.
Few-Shot Segmentation Without Meta-Learning: A Good Transductive Inference Is All You Need?
Dec 11, 2020
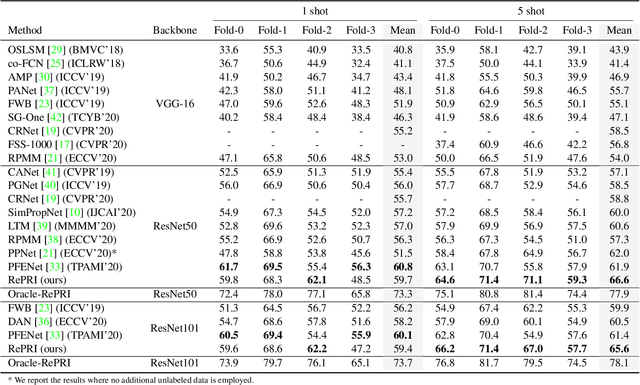
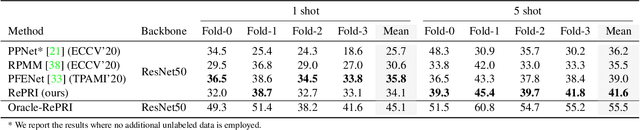
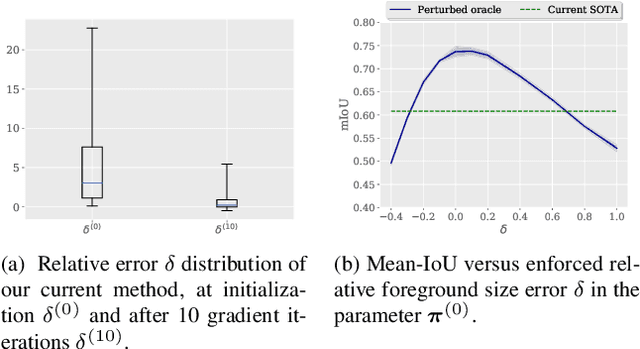
Few-shot segmentation has recently attracted substantial interest, with the popular meta-learning paradigm widely dominating the literature. We show that the way inference is performed for a given few-shot segmentation task has a substantial effect on performances, an aspect that has been overlooked in the literature. We introduce a transductive inference, which leverages the statistics of the unlabeled pixels of a task by optimizing a new loss containing three complementary terms: (i) a standard cross-entropy on the labeled pixels; (ii) the entropy of posteriors on the unlabeled query pixels; and (iii) a global KL-divergence regularizer based on the proportion of the predicted foreground region. Our inference uses a simple linear classifier of the extracted features, has a computational load comparable to inductive inference and can be used on top of any base training. Using standard cross-entropy training on the base classes, our inference yields highly competitive performances on well-known few-shot segmentation benchmarks. On PASCAL-5i, it brings about 5% improvement over the best performing state-of-the-art method in the 5-shot scenario, while being on par in the 1-shot setting. Even more surprisingly, this gap widens as the number of support samples increases, reaching up to 6% in the 10-shot scenario. Furthermore, we introduce a more realistic setting with domain shift, where the base and novel classes are drawn from different datasets. In this setting, we found that our method achieves the best performances.
Transductive Information Maximization For Few-Shot Learning
Oct 05, 2020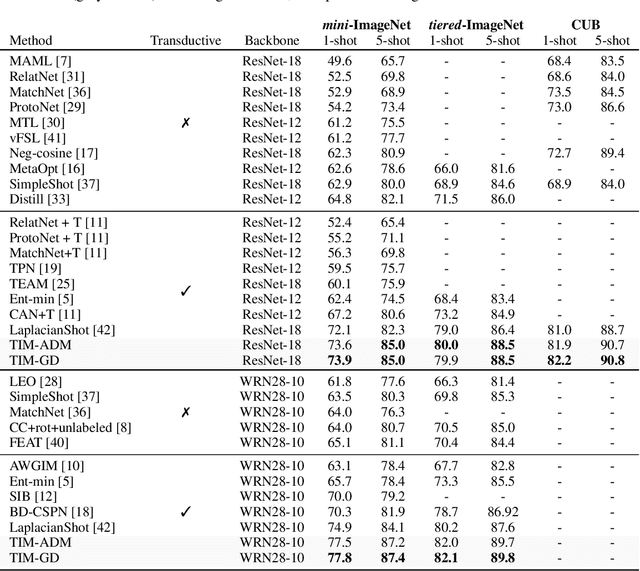
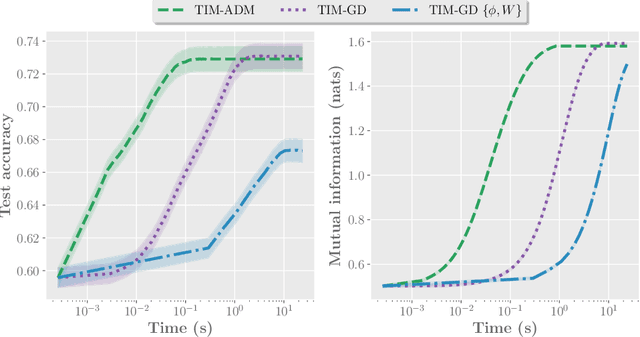
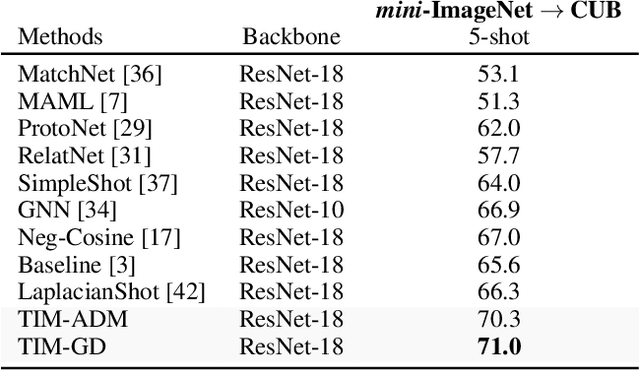
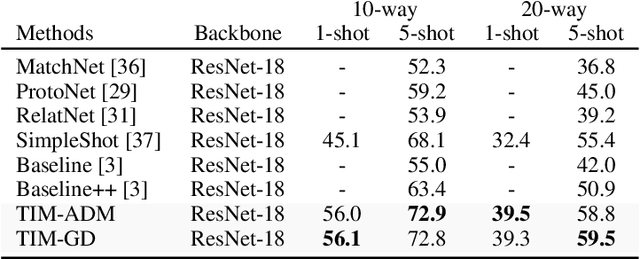
We introduce Transductive Infomation Maximization (TIM) for few-shot learning.Our method maximizes the mutual information between the query features andpredictions of a few-shot task, subject to supervision constraints from the supportset. Furthermore, we propose a new alternating direction solver for our mutual-information loss, which substantially speeds up transductive-inference convergenceover gradient-based optimization, while demonstrating similar accuracy perfor-mance. Following standard few-shot settings, our comprehensive experiments2demonstrate that TIM outperforms state-of-the-art methods significantly acrossall datasets and networks, while using simple cross-entropy training on the baseclasses, without resorting to complex meta-learning schemes. It consistently bringsbetween2%to5%improvement in accuracy over the best performing methods notonly on all the well-established few-shot benchmarks, but also on more challengingscenarios, with domain shifts and larger number of classes.