 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA self-training framework for glaucoma grading in OCT B-scans
Paper and Code
Nov 23, 2021
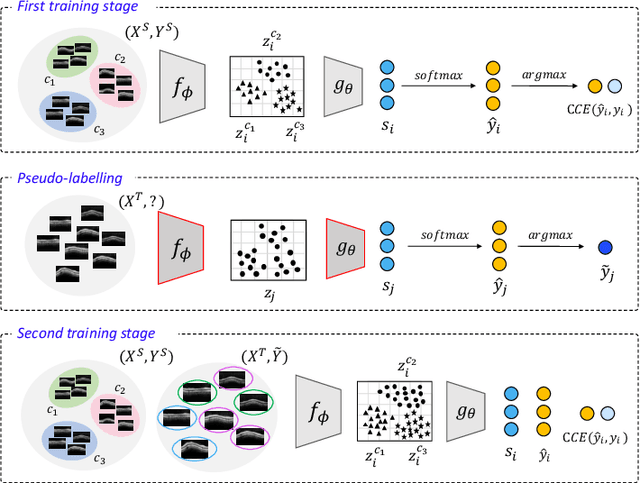
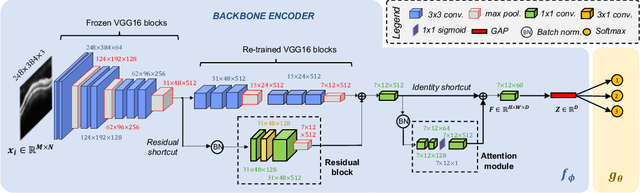
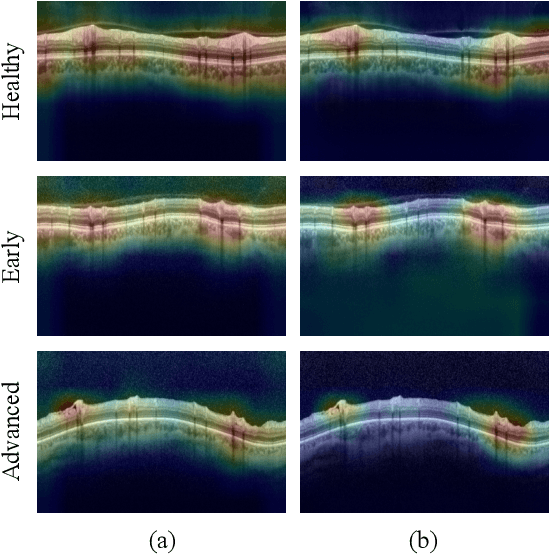
In this paper, we present a self-training-based framework for glaucoma grading using OCT B-scans under the presence of domain shift. Particularly, the proposed two-step learning methodology resorts to pseudo-labels generated during the first step to augment the training dataset on the target domain, which is then used to train the final target model. This allows transferring knowledge-domain from the unlabeled data. Additionally, we propose a novel glaucoma-specific backbone which introduces residual and attention modules via skip-connections to refine the embedding features of the latent space. By doing this, our model is capable of improving state-of-the-art from a quantitative and interpretability perspective. The reported results demonstrate that the proposed learning strategy can boost the performance of the model on the target dataset without incurring in additional annotation steps, by using only labels from the source examples. Our model consistently outperforms the baseline by 1-3% across different metrics and bridges the gap with respect to training the model on the labeled target data.