 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask Adaptive Feature Transformation for One-Shot Learning
Apr 13, 2023We introduce a simple non-linear embedding adaptation layer, which is fine-tuned on top of fixed pre-trained features for one-shot tasks, improving significantly transductive entropy-based inference for low-shot regimes. Our norm-induced transformation could be understood as a re-parametrization of the feature space to disentangle the representations of different classes in a task specific manner. It focuses on the relevant feature dimensions while hindering the effects of non-relevant dimensions that may cause overfitting in a one-shot setting. We also provide an interpretation of our proposed feature transformation in the basic case of few-shot inference with K-means clustering. Furthermore, we give an interesting bound-optimization link between K-means and entropy minimization. This emphasizes why our feature transformation is useful in the context of entropy minimization. We report comprehensive experiments, which show consistent improvements over a variety of one-shot benchmarks, outperforming recent state-of-the-art methods.
Transductive Few-Shot Learning: Clustering is All You Need?
Jun 16, 2021
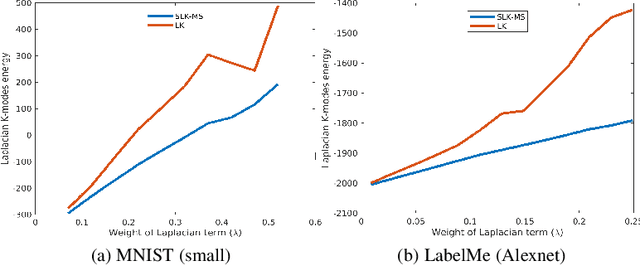
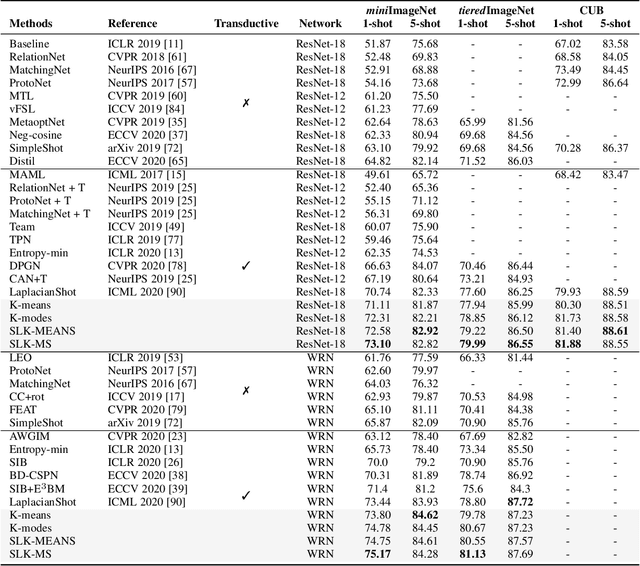
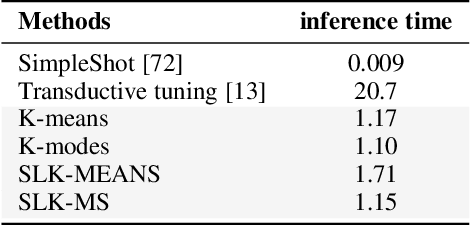
We investigate a general formulation for clustering and transductive few-shot learning, which integrates prototype-based objectives, Laplacian regularization and supervision constraints from a few labeled data points. We propose a concave-convex relaxation of the problem, and derive a computationally efficient block-coordinate bound optimizer, with convergence guarantee. At each iteration,our optimizer computes independent (parallel) updates for each point-to-cluster assignment. Therefore, it could be trivially distributed for large-scale clustering and few-shot tasks. Furthermore, we provides a thorough convergence analysis based on point-to-set maps. Were port comprehensive clustering and few-shot learning experiments over various data sets, showing that our method yields competitive performances, in term of accuracy and optimization quality, while scaling up to large problems. Using standard training on the base classes, without resorting to complex meta-learning and episodic-training strategies, our approach outperforms state-of-the-art few-shot methods by significant margins, across various models, settings and data sets. Surprisingly, we found that even standard clustering procedures (e.g., K-means), which correspond to particular, non-regularized cases of our general model, already achieve competitive performances in comparison to the state-of-the-art in few-shot learning. These surprising results point to the limitations of the current few-shot benchmarks, and question the viability of a large body of convoluted few-shot learning techniques in the recent literature.
Laplacian Regularized Few-Shot Learning
Jun 28, 2020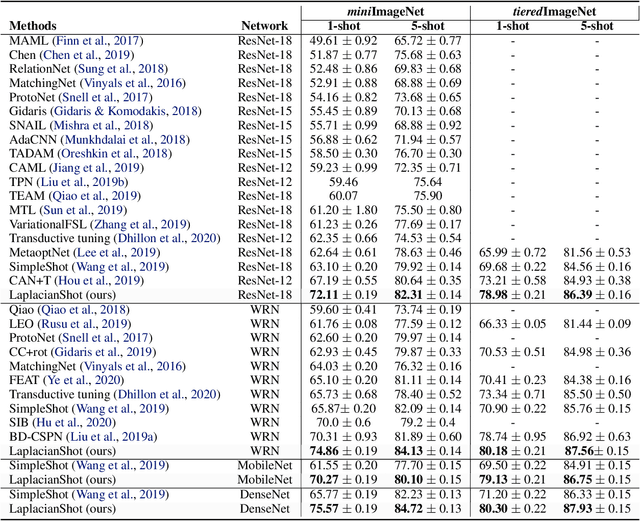
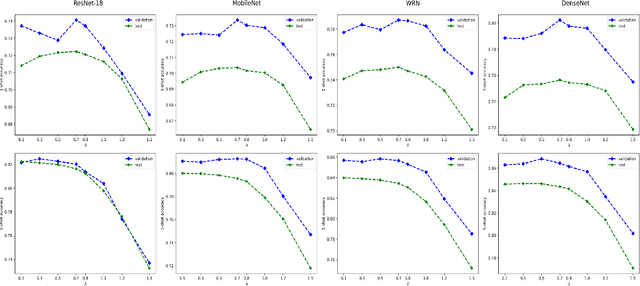
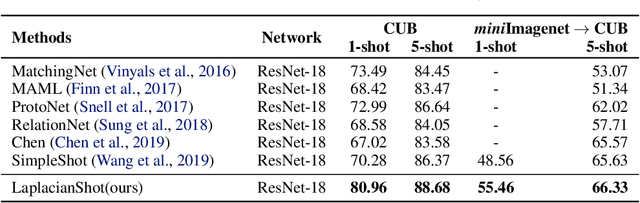
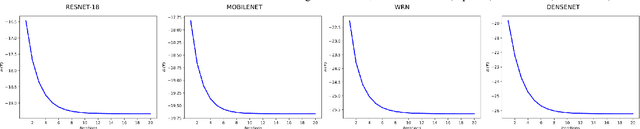
We propose a transductive Laplacian-regularized inference for few-shot tasks. Given any feature embedding learned from the base classes, we minimize a quadratic binary-assignment function containing two terms: (1) a unary term assigning query samples to the nearest class prototype, and (2) a pairwise Laplacian term encouraging nearby query samples to have consistent label assignments. Our transductive inference does not re-train the base model, and can be viewed as a graph clustering of the query set, subject to supervision constraints from the support set. We derive a computationally efficient bound optimizer of a relaxation of our function, which computes independent (parallel) updates for each query sample, while guaranteeing convergence. Following a simple cross-entropy training on the base classes, and without complex meta-learning strategies, we conducted comprehensive experiments over five few-shot learning benchmarks. Our LaplacianShot consistently outperforms state-of-the-art methods by significant margins across different models, settings, and data sets. Furthermore, our transductive inference is very fast, with computational times that are close to inductive inference, and can be used for large-scale few-shot tasks.
Metric learning: cross-entropy vs. pairwise losses
Mar 19, 2020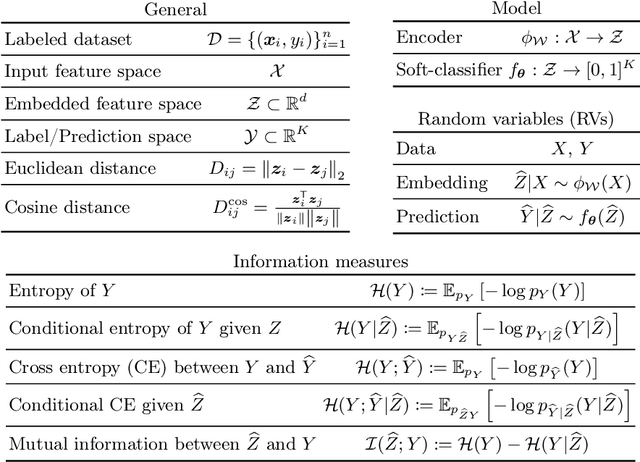
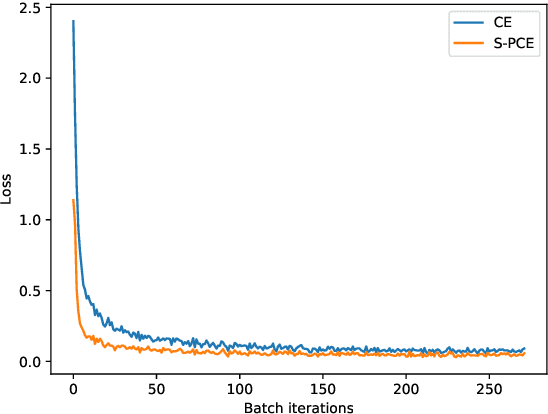


Recently, substantial research efforts in Deep Metric Learning (DML) focused on designing complex pairwise-distance losses and convoluted sample-mining and implementation strategies to ease optimization. The standard cross-entropy loss for classification has been largely overlooked in DML. On the surface, the cross-entropy may seem unrelated and irrelevant to metric learning as it does not explicitly involve pairwise distances. However, we provide a theoretical analysis that links the cross-entropy to several well-known and recent pairwise losses. Our connections are drawn from two different perspectives: one based on an explicit optimization insight; the other on discriminative and generative views of the mutual information between the labels and the learned features. First, we explicitly demonstrate that the cross-entropy is an upper bound on a new pairwise loss, which has a structure similar to various pairwise losses: it minimizes intra-class distances while maximizing inter-class distances. As a result, minimizing the cross-entropy can be seen as an approximate bound-optimization (or Majorize-Minimize) algorithm for minimizing this pairwise loss. Second, we show that, more generally, minimizing the cross-entropy is actually equivalent to maximizing the mutual information, to which we connect several well-known pairwise losses. These findings indicate that the cross-entropy represents a proxy for maximizing the mutual information -- as pairwise losses do -- without the need for complex sample-mining and optimization schemes. Furthermore, we show that various standard pairwise losses can be explicitly related to one another via bound relationships. Our experiments over four standard DML benchmarks (CUB200, Cars-196, Stanford Online Product and In-Shop) strongly support our findings. We consistently obtained state-of-the-art results, outperforming many recent and complex DML methods.
Clustering with Fairness Constraints: A Flexible and Scalable Approach
Jun 19, 2019
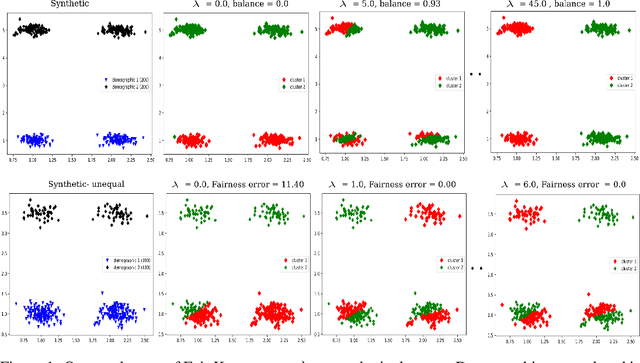
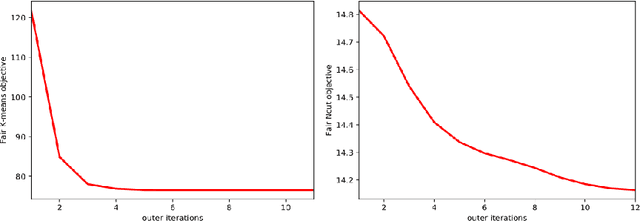
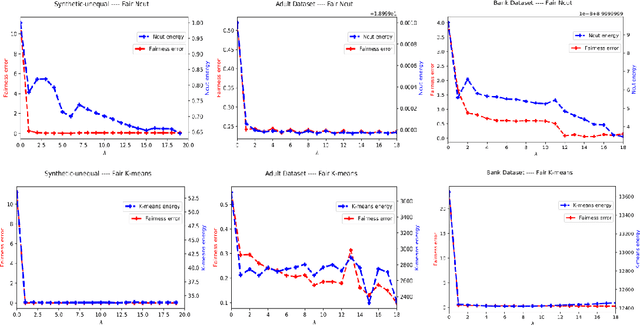
This study investigates a general variational formulation of fair clustering, which can integrate fairness constraints with a large class of clustering objectives. Unlike the existing methods, our formulation can impose any desired (target) demographic proportions within each cluster. Furthermore, it enables to control the trade-off between fairness and the clustering objective. We derive an auxiliary function (tight upper bound) of our KL-based fairness penalty via its concave-convex decomposition and Lipschitz-gradient property. Our upper bound can be optimized jointly with various clustering objectives, including both prototype-based such as K-means and graph-based such as Normalized Cut. Interestingly, at each iteration, our general fair-clustering algorithm performs an independent update for each assignment variable, while guaranteeing convergence. Therefore, it can be easily distributed for large-scale data sets. Such scalability is important as it enables to explore different trade-off levels between fairness and clustering objectives. Unlike existing fairness-constrained spectral clustering, our formulation does not need storing an affinity matrix and computing its eigenvalue decomposition. Moreover, unlike existing prototype-based methods, our experiments reveal that fairness does not come at a significant cost of the clustering objective. In fact, several of our tests showed that our fairness penalty helped to avoid weak local minima of the clustering objective (i.e., with fairness, we obtained better clustering objectives). We demonstrate the flexibility and scalability of our algorithm with comprehensive evaluations over both synthetic and real world data sets, many of which are much larger than those used in recent fair-clustering methods.
Scalable Laplacian K-modes
Oct 31, 2018
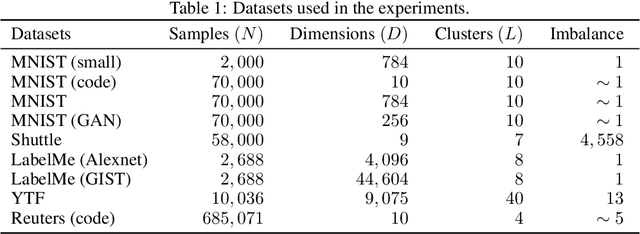
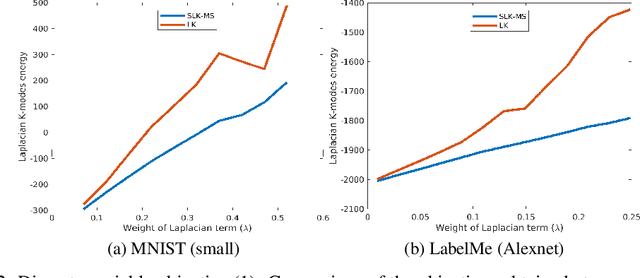
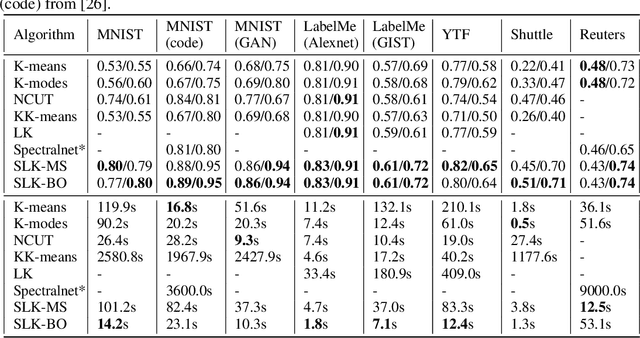
We advocate Laplacian K-modes for joint clustering and density mode finding, and propose a concave-convex relaxation of the problem, which yields a parallel algorithm that scales up to large datasets and high dimensions. We optimize a tight bound (auxiliary function) of our relaxation, which, at each iteration, amounts to computing an independent update for each cluster-assignment variable, with guaranteed convergence. Therefore, our bound optimizer can be trivially distributed for large-scale data sets. Furthermore, we show that the density modes can be obtained as byproducts of the assignment variables via simple maximum-value operations whose additional computational cost is linear in the number of data points. Our formulation does not need storing a full affinity matrix and computing its eigenvalue decomposition, neither does it perform expensive projection steps and Lagrangian-dual inner iterates for the simplex constraints of each point. Furthermore, unlike mean-shift, our density-mode estimation does not require inner-loop gradient-ascent iterates. It has a complexity independent of feature-space dimension, yields modes that are valid data points in the input set and is applicable to discrete domains as well as arbitrary kernels. We report comprehensive experiments over various data sets, which show that our algorithm yields very competitive performances in term of optimization quality (i.e., the value of the discrete-variable objective at convergence) and clustering accuracy.