 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric learning: cross-entropy vs. pairwise losses
Paper and Code
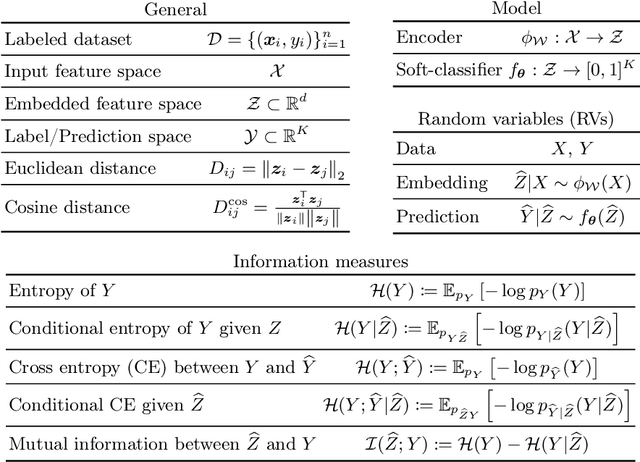
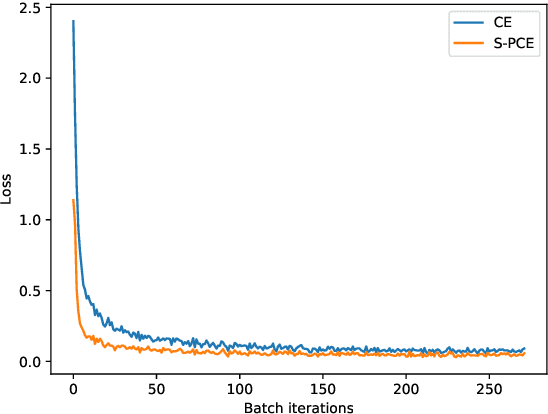


Recently, substantial research efforts in Deep Metric Learning (DML) focused on designing complex pairwise-distance losses and convoluted sample-mining and implementation strategies to ease optimization. The standard cross-entropy loss for classification has been largely overlooked in DML. On the surface, the cross-entropy may seem unrelated and irrelevant to metric learning as it does not explicitly involve pairwise distances. However, we provide a theoretical analysis that links the cross-entropy to several well-known and recent pairwise losses. Our connections are drawn from two different perspectives: one based on an explicit optimization insight; the other on discriminative and generative views of the mutual information between the labels and the learned features. First, we explicitly demonstrate that the cross-entropy is an upper bound on a new pairwise loss, which has a structure similar to various pairwise losses: it minimizes intra-class distances while maximizing inter-class distances. As a result, minimizing the cross-entropy can be seen as an approximate bound-optimization (or Majorize-Minimize) algorithm for minimizing this pairwise loss. Second, we show that, more generally, minimizing the cross-entropy is actually equivalent to maximizing the mutual information, to which we connect several well-known pairwise losses. These findings indicate that the cross-entropy represents a proxy for maximizing the mutual information -- as pairwise losses do -- without the need for complex sample-mining and optimization schemes. Furthermore, we show that various standard pairwise losses can be explicitly related to one another via bound relationships. Our experiments over four standard DML benchmarks (CUB200, Cars-196, Stanford Online Product and In-Shop) strongly support our findings. We consistently obtained state-of-the-art results, outperforming many recent and complex DML methods.