 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Security against Data Poisoning: Are We There Yet?
Paper and Code
Apr 12, 2022

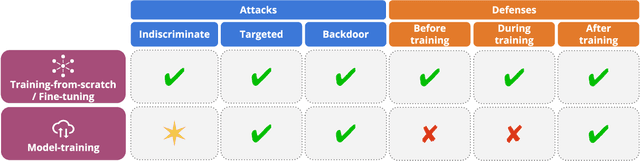
The recent success of machine learning has been fueled by the increasing availability of computing power and large amounts of data in many different applications. However, the trustworthiness of the resulting models can be compromised when such data is maliciously manipulated to mislead the learning process. In this article, we first review poisoning attacks that compromise the training data used to learn machine-learning models, including attacks that aim to reduce the overall performance, manipulate the predictions on specific test samples, and even implant backdoors in the model. We then discuss how to mitigate these attacks before, during, and after model training. We conclude our article by formulating some relevant open challenges which are hindering the development of testing methods and benchmarks suitable for assessing and improving the trustworthiness of machine-learning models against data poisoning attacks.