 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Verifiable Training Using Pairwise Class Similarity
Paper and Code
Dec 14, 2020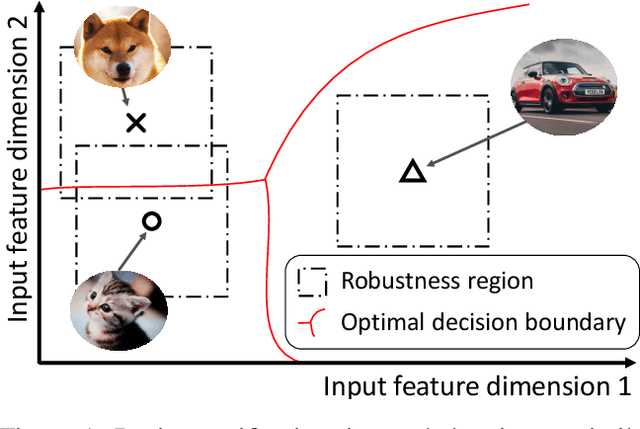
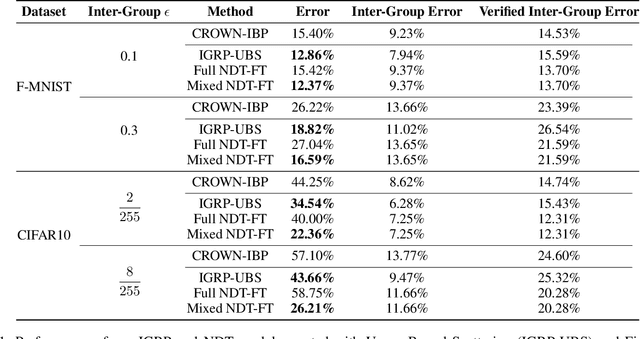
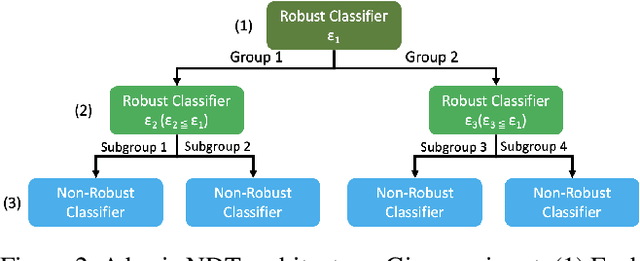
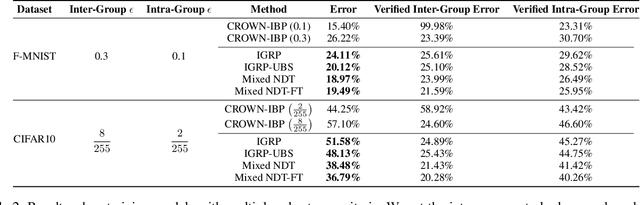
Verifiable training has shown success in creating neural networks that are provably robust to a given amount of noise. However, despite only enforcing a single robustness criterion, its performance scales poorly with dataset complexity. On CIFAR10, a non-robust LeNet model has a 21.63% error rate, while a model created using verifiable training and a L-infinity robustness criterion of 8/255, has an error rate of 57.10%. Upon examination, we find that when labeling visually similar classes, the model's error rate is as high as 61.65%. We attribute the loss in performance to inter-class similarity. Similar classes (i.e., close in the feature space) increase the difficulty of learning a robust model. While it's desirable to train a robust model for a large robustness region, pairwise class similarities limit the potential gains. Also, consideration must be made regarding the relative cost of mistaking similar classes. In security or safety critical tasks, similar classes are likely to belong to the same group, and thus are equally sensitive. In this work, we propose a new approach that utilizes inter-class similarity to improve the performance of verifiable training and create robust models with respect to multiple adversarial criteria. First, we use agglomerate clustering to group similar classes and assign robustness criteria based on the similarity between clusters. Next, we propose two methods to apply our approach: (1) Inter-Group Robustness Prioritization, which uses a custom loss term to create a single model with multiple robustness guarantees and (2) neural decision trees, which trains multiple sub-classifiers with different robustness guarantees and combines them in a decision tree architecture. On Fashion-MNIST and CIFAR10, our approach improves clean performance by 9.63% and 30.89% respectively. On CIFAR100, our approach improves clean performance by 26.32%.