 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Better Environments for Autonomous Cyber Defence
Apr 09, 2026In November 2025, the authors ran a workshop on the topic of what makes a good reinforcement learning (RL) environment for autonomous cyber defence (ACD). This paper details the knowledge shared by participants both during the workshop and shortly afterwards by contributing herein. The workshop participants come from academia, industry, and government, and have extensive hands-on experience designing and working with RL and cyber environments. While there is now a sizeable body of literature describing work in RL for ACD, there is nevertheless a great deal of tradecraft, domain knowledge, and common hazards which are not detailed comprehensively in a single resource. With a specific focus on building better environments to train and evaluate autonomous RL agents in network defence scenarios, including government and critical infrastructure networks, the contributions of this work are twofold: (1) a framework for decomposing the interface between RL cyber environments and real systems, and (2) guidelines on current best practice for RL-based ACD environment development and agent evaluation, based on the key findings from our workshop.
SoK: The Pitfalls of Deep Reinforcement Learning for Cybersecurity
Feb 09, 2026Deep Reinforcement Learning (DRL) has achieved remarkable success in domains requiring sequential decision-making, motivating its application to cybersecurity problems. However, transitioning DRL from laboratory simulations to bespoke cyber environments can introduce numerous issues. This is further exacerbated by the often adversarial, non-stationary, and partially-observable nature of most cybersecurity tasks. In this paper, we identify and systematize 11 methodological pitfalls that frequently occur in DRL for cybersecurity (DRL4Sec) literature across the stages of environment modeling, agent training, performance evaluation, and system deployment. By analyzing 66 significant DRL4Sec papers (2018-2025), we quantify the prevalence of each pitfall and find an average of over five pitfalls per paper. We demonstrate the practical impact of these pitfalls using controlled experiments in (i) autonomous cyber defense, (ii) adversarial malware creation, and (iii) web security testing environments. Finally, we provide actionable recommendations for each pitfall to support the development of more rigorous and deployable DRL-based security systems.
Clutch Control: An Attention-based Combinatorial Bandit for Efficient Mutation in JavaScript Engine Fuzzing
Oct 14, 2025JavaScript engines are widely used in web browsers, PDF readers, and server-side applications. The rise in concern over their security has led to the development of several targeted fuzzing techniques. However, existing approaches use random selection to determine where to perform mutations in JavaScript code. We postulate that the problem of selecting better mutation targets is suitable for combinatorial bandits with a volatile number of arms. Thus, we propose CLUTCH, a novel deep combinatorial bandit that can observe variable length JavaScript test case representations, using an attention mechanism from deep learning. Furthermore, using Concrete Dropout, CLUTCH can dynamically adapt its exploration. We show that CLUTCH increases efficiency in JavaScript fuzzing compared to three state-of-the-art solutions by increasing the number of valid test cases and coverage-per-testcase by, respectively, 20.3% and 8.9% on average. In volatile and combinatorial settings we show that CLUTCH outperforms state-of-the-art bandits, achieving at least 78.1% and 4.1% less regret in volatile and combinatorial settings, respectively.
DRMD: Deep Reinforcement Learning for Malware Detection under Concept Drift
Aug 26, 2025Malware detection in real-world settings must deal with evolving threats, limited labeling budgets, and uncertain predictions. Traditional classifiers, without additional mechanisms, struggle to maintain performance under concept drift in malware domains, as their supervised learning formulation cannot optimize when to defer decisions to manual labeling and adaptation. Modern malware detection pipelines combine classifiers with monthly active learning (AL) and rejection mechanisms to mitigate the impact of concept drift. In this work, we develop a novel formulation of malware detection as a one-step Markov Decision Process and train a deep reinforcement learning (DRL) agent, simultaneously optimizing sample classification performance and rejecting high-risk samples for manual labeling. We evaluated the joint detection and drift mitigation policy learned by the DRL-based Malware Detection (DRMD) agent through time-aware evaluations on Android malware datasets subject to realistic drift requiring multi-year performance stability. The policies learned under these conditions achieve a higher Area Under Time (AUT) performance compared to standard classification approaches used in the domain, showing improved resilience to concept drift. Specifically, the DRMD agent achieved a $5.18\pm5.44$, $14.49\pm12.86$, and $10.06\pm10.81$ average AUT performance improvement for the classification only, classification with rejection, and classification with rejection and AL settings, respectively. Our results demonstrate for the first time that DRL can facilitate effective malware detection and improved resiliency to concept drift in the dynamic environment of the Android malware domain.
APIRL: Deep Reinforcement Learning for REST API Fuzzing
Dec 20, 2024REST APIs have become key components of web services. However, they often contain logic flaws resulting in server side errors or security vulnerabilities. HTTP requests are used as test cases to find and mitigate such issues. Existing methods to modify requests, including those using deep learning, suffer from limited performance and precision, relying on undirected search or making limited usage of the contextual information. In this paper we propose APIRL, a fully automated deep reinforcement learning tool for testing REST APIs. A key novelty of our approach is the use of feedback from a transformer module pre-trained on JSON-structured data, akin to that used in API responses. This allows APIRL to learn the subtleties relating to test outcomes, and generalise to unseen API endpoints. We show APIRL can find significantly more bugs than the state-of-the-art in real world REST APIs while minimising the number of required test cases. We also study how reward functions, and other key design choices, affect learnt policies in a thorough ablation study.
Autonomous Network Defence using Reinforcement Learning
Sep 26, 2024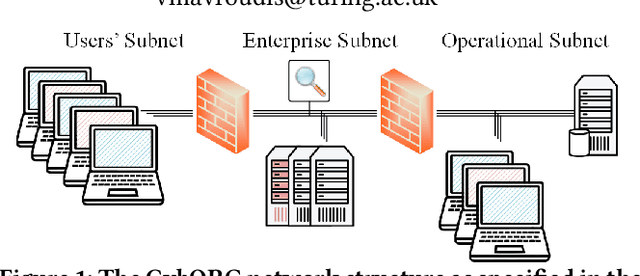
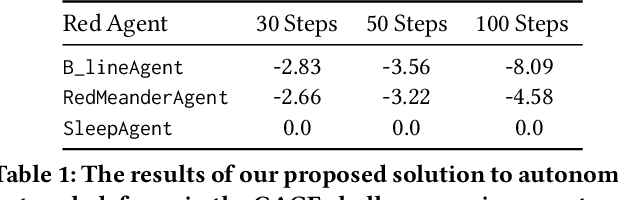
In the network security arms race, the defender is significantly disadvantaged as they need to successfully detect and counter every malicious attack. In contrast, the attacker needs to succeed only once. To level the playing field, we investigate the effectiveness of autonomous agents in a realistic network defence scenario. We first outline the problem, provide the background on reinforcement learning and detail our proposed agent design. Using a network environment simulation, with 13 hosts spanning 3 subnets, we train a novel reinforcement learning agent and show that it can reliably defend continual attacks by two advanced persistent threat (APT) red agents: one with complete knowledge of the network layout and another which must discover resources through exploration but is more general.
Canaries and Whistles: Resilient Drone Communication Networks with (or without) Deep Reinforcement Learning
Dec 08, 2023



Communication networks able to withstand hostile environments are critically important for disaster relief operations. In this paper, we consider a challenging scenario where drones have been compromised in the supply chain, during their manufacture, and harbour malicious software capable of wide-ranging and infectious disruption. We investigate multi-agent deep reinforcement learning as a tool for learning defensive strategies that maximise communications bandwidth despite continual adversarial interference. Using a public challenge for learning network resilience strategies, we propose a state-of-the-art expert technique and study its superiority over deep reinforcement learning agents. Correspondingly, we identify three specific methods for improving the performance of our learning-based agents: (1) ensuring each observation contains the necessary information, (2) using expert agents to provide a curriculum for learning, and (3) paying close attention to reward. We apply our methods and present a new mixed strategy enabling expert and learning-based agents to work together and improve on all prior results.
* Published in AISec '23. This version fixes some terminology to improve readability
Inroads into Autonomous Network Defence using Explained Reinforcement Learning
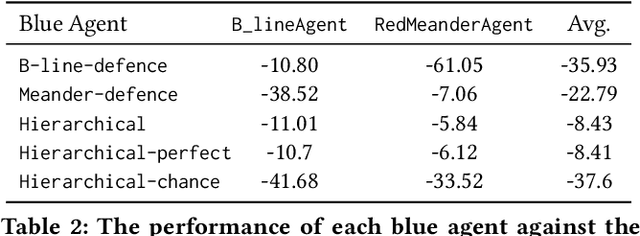
Jun 15, 2023Computer network defence is a complicated task that has necessitated a high degree of human involvement. However, with recent advancements in machine learning, fully autonomous network defence is becoming increasingly plausible. This paper introduces an end-to-end methodology for studying attack strategies, designing defence agents and explaining their operation. First, using state diagrams, we visualise adversarial behaviour to gain insight about potential points of intervention and inform the design of our defensive models. We opt to use a set of deep reinforcement learning agents trained on different parts of the task and organised in a shallow hierarchy. Our evaluation shows that the resulting design achieves a substantial performance improvement compared to prior work. Finally, to better investigate the decision-making process of our agents, we complete our analysis with a feature ablation and importance study.
Matching Pairs: Attributing Fine-Tuned Models to their Pre-Trained Large Language Models
Jun 15, 2023The wide applicability and adaptability of generative large language models (LLMs) has enabled their rapid adoption. While the pre-trained models can perform many tasks, such models are often fine-tuned to improve their performance on various downstream applications. However, this leads to issues over violation of model licenses, model theft, and copyright infringement. Moreover, recent advances show that generative technology is capable of producing harmful content which exacerbates the problems of accountability within model supply chains. Thus, we need a method to investigate how a model was trained or a piece of text was generated and what their pre-trained base model was. In this paper we take the first step to address this open problem by tracing back the origin of a given fine-tuned LLM to its corresponding pre-trained base model. We consider different knowledge levels and attribution strategies, and find that we can correctly trace back 8 out of the 10 fine tuned models with our best method.