 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of Privacy Risks in Curriculum Learning
Oct 16, 2023Training a machine learning model with data following a meaningful order, i.e., from easy to hard, has been proven to be effective in accelerating the training process and achieving better model performance. The key enabling technique is curriculum learning (CL), which has seen great success and has been deployed in areas like image and text classification. Yet, how CL affects the privacy of machine learning is unclear. Given that CL changes the way a model memorizes the training data, its influence on data privacy needs to be thoroughly evaluated. To fill this knowledge gap, we perform the first study and leverage membership inference attack (MIA) and attribute inference attack (AIA) as two vectors to quantify the privacy leakage caused by CL. Our evaluation of nine real-world datasets with attack methods (NN-based, metric-based, label-only MIA, and NN-based AIA) revealed new insights about CL. First, MIA becomes slightly more effective when CL is applied, but the impact is much more prominent to a subset of training samples ranked as difficult. Second, a model trained under CL is less vulnerable under AIA, compared to MIA. Third, the existing defense techniques like DP-SGD, MemGuard, and MixupMMD are still effective under CL, though DP-SGD has a significant impact on target model accuracy. Finally, based on our insights into CL, we propose a new MIA, termed Diff-Cali, which exploits the difficulty scores for result calibration and is demonstrated to be effective against all CL methods and the normal training method. With this study, we hope to draw the community's attention to the unintended privacy risks of emerging machine-learning techniques and develop new attack benchmarks and defense solutions.
Continuous Release of Data Streams under both Centralized and Local Differential Privacy
May 24, 2020

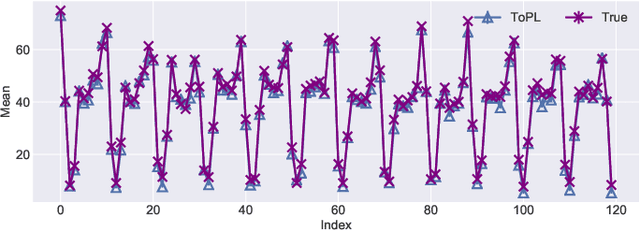
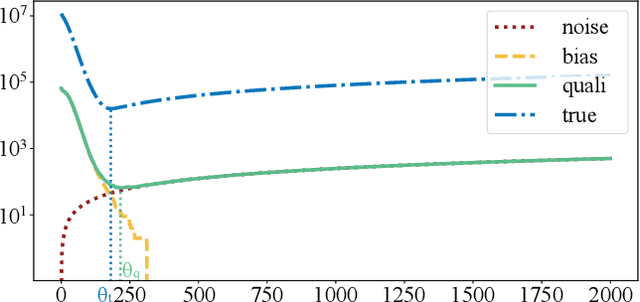
In this paper, we study the problem of publishing a stream of real-valued data satisfying differential privacy (DP). One major challenge is that the maximal possible value can be quite large; thus it is necessary to estimate a threshold so that numbers above it are truncated to reduce the amount of noise that is required to all the data. The estimation must be done based on the data in a private fashion. We develop such a method that uses the Exponential Mechanism with a quality function that approximates well the utility goal while maintaining a low sensitivity. Given the threshold, we then propose a novel online hierarchical method and several post-processing techniques. Building on these ideas, we formalize the steps into a framework for private publishing of stream data. Our framework consists of three components: a threshold optimizer that privately estimates the threshold, a perturber that adds calibrated noises to the stream, and a smoother that improves the result using post-processing. Within our framework, we design an algorithm satisfying the more stringent setting of DP called local DP (LDP). To our knowledge, this is the first LDP algorithm for publishing streaming data. Using four real-world datasets, we demonstrate that our mechanism outperforms the state-of-the-art by a factor of 6-10 orders of magnitude in terms of utility (measured by the mean squared error of answering a random range query).