 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Robustness the Cost of Accuracy? -- A Comprehensive Study on the Robustness of 18 Deep Image Classification Models
Paper and Code
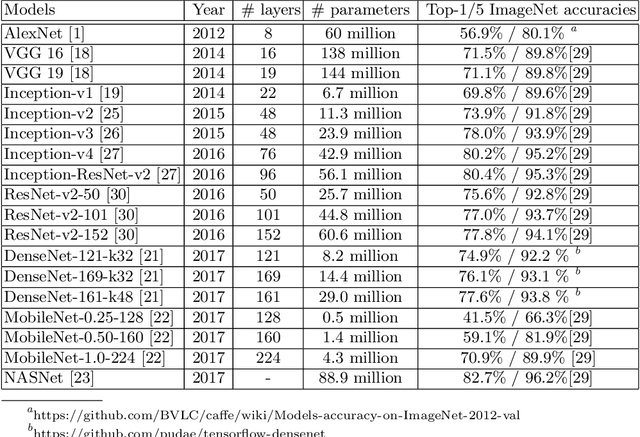
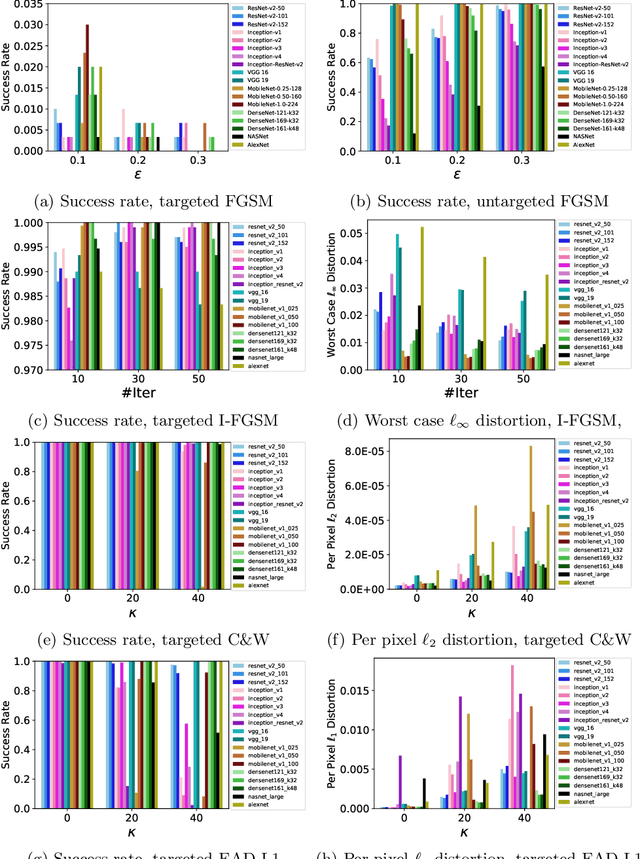
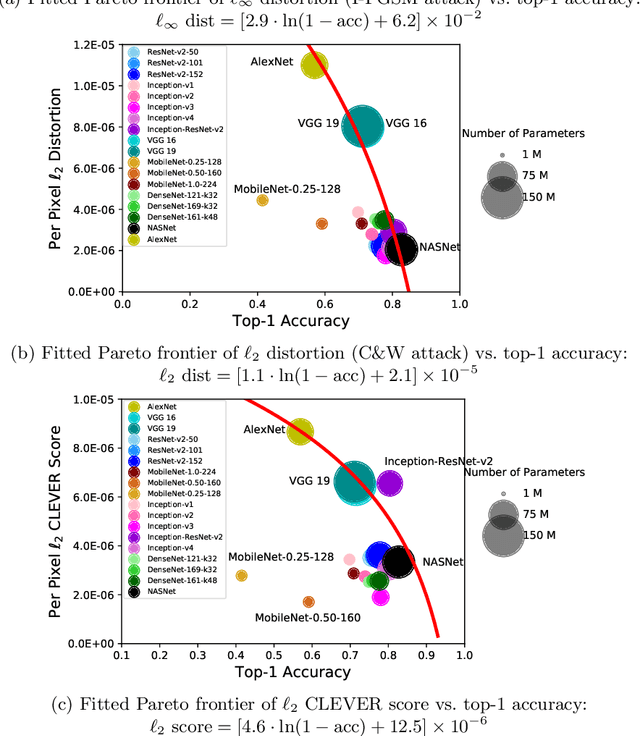
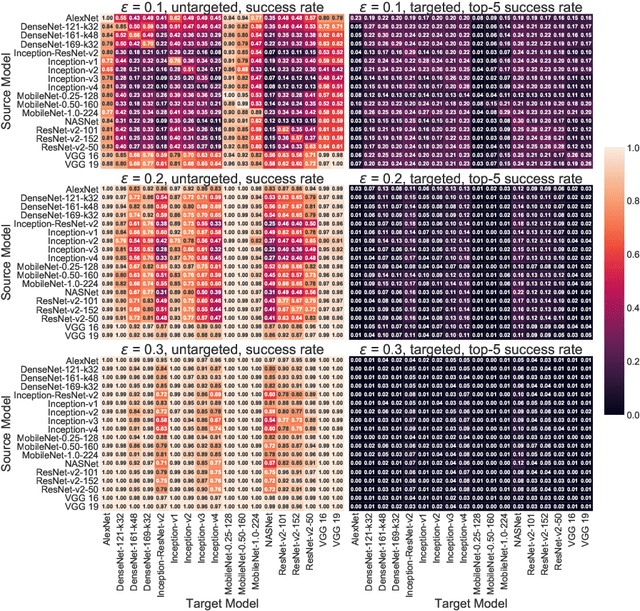
The prediction accuracy has been the long-lasting and sole standard for comparing the performance of different image classification models, including the ImageNet competition. However, recent studies have highlighted the lack of robustness in well-trained deep neural networks to adversarial examples. Visually imperceptible perturbations to natural images can easily be crafted and mislead the image classifiers towards misclassification. To demystify the trade-offs between robustness and accuracy, in this paper we thoroughly benchmark 18 ImageNet models using multiple robustness metrics, including the distortion, success rate and transferability of adversarial examples between 306 pairs of models. Our extensive experimental results reveal several new insights: (1) linear scaling law - the empirical $\ell_2$ and $\ell_\infty$ distortion metrics scale linearly with the logarithm of classification error; (2) model architecture is a more critical factor to robustness than model size, and the disclosed accuracy-robustness Pareto frontier can be used as an evaluation criterion for ImageNet model designers; (3) for a similar network architecture, increasing network depth slightly improves robustness in $\ell_\infty$ distortion; (4) there exist models (in VGG family) that exhibit high adversarial transferability, while most adversarial examples crafted from one model can only be transferred within the same family. Experiment code is publicly available at \url{https://github.com/huanzhang12/Adversarial_Survey}.