 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Model Inversion Attribute Inference Attacks on Classification Models
Paper and Code
Dec 07, 2020

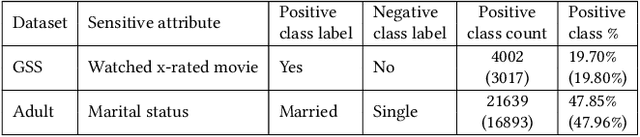
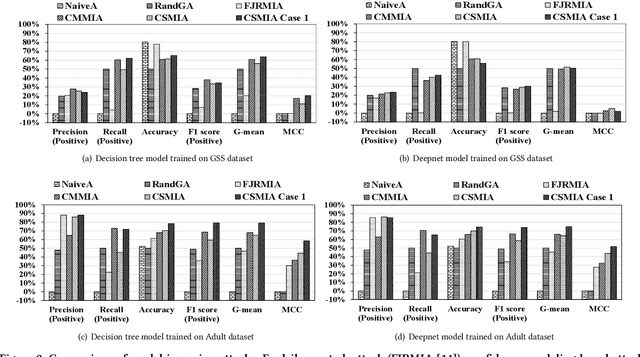
Increasing use of ML technologies in privacy-sensitive domains such as medical diagnoses, lifestyle predictions, and business decisions highlights the need to better understand if these ML technologies are introducing leakages of sensitive and proprietary training data. In this paper, we focus on one kind of model inversion attacks, where the adversary knows non-sensitive attributes about instances in the training data and aims to infer the value of a sensitive attribute unknown to the adversary, using oracle access to the target classification model. We devise two novel model inversion attribute inference attacks -- confidence modeling-based attack and confidence score-based attack, and also extend our attack to the case where some of the other (non-sensitive) attributes are unknown to the adversary. Furthermore, while previous work uses accuracy as the metric to evaluate the effectiveness of attribute inference attacks, we find that accuracy is not informative when the sensitive attribute distribution is unbalanced. We identify two metrics that are better for evaluating attribute inference attacks, namely G-mean and Matthews correlation coefficient (MCC). We evaluate our attacks on two types of machine learning models, decision tree and deep neural network, trained with two real datasets. Experimental results show that our newly proposed attacks significantly outperform the state-of-the-art attacks. Moreover, we empirically show that specific groups in the training dataset (grouped by attributes, e.g., gender, race) could be more vulnerable to model inversion attacks. We also demonstrate that our attacks' performances are not impacted significantly when some of the other (non-sensitive) attributes are also unknown to the adversary.