 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSR: A Semi-Decentralized Federated Learning Algorithm for Non-IIDness in IoT System
Mar 19, 2024



In the Industrial Internet of Things (IoT), a large amount of data will be generated every day. Due to privacy and security issues, it is difficult to collect all these data together to train deep learning models, thus the federated learning, a distributed machine learning paradigm that protects data privacy, has been widely used in IoT. However, in practical federated learning, the data distributions usually have large differences across devices, and the heterogeneity of data will deteriorate the performance of the model. Moreover, federated learning in IoT usually has a large number of devices involved in training, and the limited communication resource of cloud servers become a bottleneck for training. To address the above issues, in this paper, we combine centralized federated learning with decentralized federated learning to design a semi-decentralized cloud-edge-device hierarchical federated learning framework, which can mitigate the impact of data heterogeneity, and can be deployed at lage scale in IoT. To address the effect of data heterogeneity, we use an incremental subgradient optimization algorithm in each ring cluster to improve the generalization ability of the ring cluster models. Our extensive experiments show that our approach can effectively mitigate the impact of data heterogeneity and alleviate the communication bottleneck in cloud servers.
CodeArt: Better Code Models by Attention Regularization When Symbols Are Lacking
Feb 19, 2024



Transformer based code models have impressive performance in many software engineering tasks. However, their effectiveness degrades when symbols are missing or not informative. The reason is that the model may not learn to pay attention to the right correlations/contexts without the help of symbols. We propose a new method to pre-train general code models when symbols are lacking. We observe that in such cases, programs degenerate to something written in a very primitive language. We hence propose to use program analysis to extract contexts a priori (instead of relying on symbols and masked language modeling as in vanilla models). We then leverage a novel attention masking method to only allow the model attending to these contexts, e.g., bi-directional program dependence transitive closures and token co-occurrences. In the meantime, the inherent self-attention mechanism is utilized to learn which of the allowed attentions are more important compared to others. To realize the idea, we enhance the vanilla tokenization and model architecture of a BERT model, construct and utilize attention masks, and introduce a new pre-training algorithm. We pre-train this BERT-like model from scratch, using a dataset of 26 million stripped binary functions with explicit program dependence information extracted by our tool. We apply the model in three downstream tasks: binary similarity, type inference, and malware family classification. Our pre-trained model can improve the SOTAs in these tasks from 53% to 64%, 49% to 60%, and 74% to 94%, respectively. It also substantially outperforms other general pre-training techniques of code understanding models.
Fight Fire with Fire: Combating Adversarial Patch Attacks using Pattern-randomized Defensive Patches
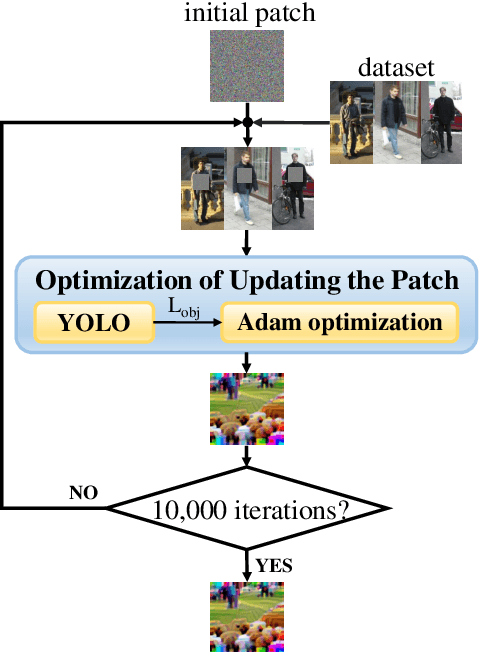
Nov 10, 2023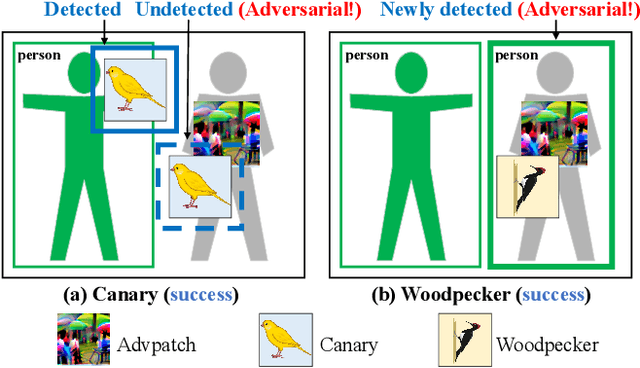
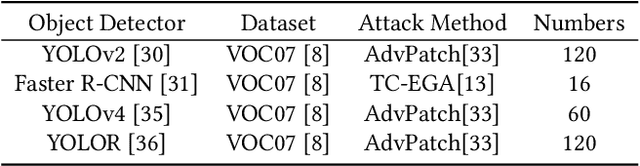
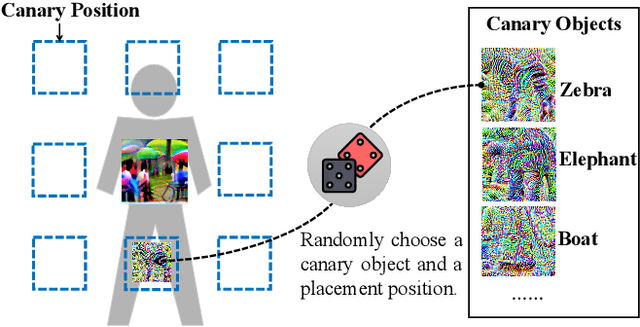

Object detection has found extensive applications in various tasks, but it is also susceptible to adversarial patch attacks. Existing defense methods often necessitate modifications to the target model or result in unacceptable time overhead. In this paper, we adopt a counterattack approach, following the principle of "fight fire with fire," and propose a novel and general methodology for defending adversarial attacks. We utilize an active defense strategy by injecting two types of defensive patches, canary and woodpecker, into the input to proactively probe or weaken potential adversarial patches without altering the target model. Moreover, inspired by randomization techniques employed in software security, we employ randomized canary and woodpecker injection patterns to defend against defense-aware attacks. The effectiveness and practicality of the proposed method are demonstrated through comprehensive experiments. The results illustrate that canary and woodpecker achieve high performance, even when confronted with unknown attack methods, while incurring limited time overhead. Furthermore, our method also exhibits sufficient robustness against defense-aware attacks, as evidenced by adaptive attack experiments.
We Can Always Catch You: Detecting Adversarial Patched Objects WITH or WITHOUT Signature
Jun 10, 2021
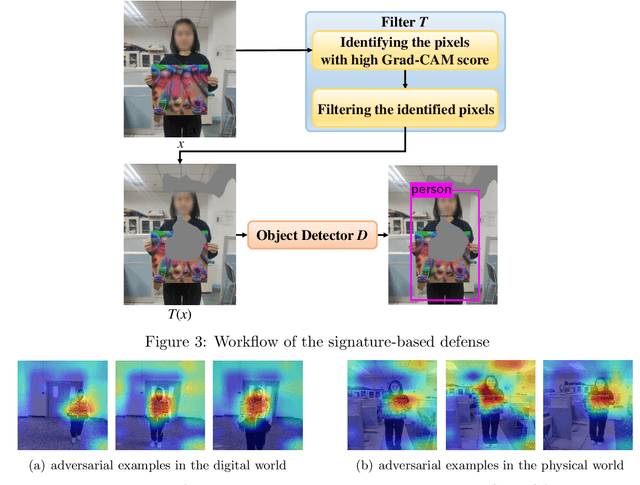

Recently, the object detection based on deep learning has proven to be vulnerable to adversarial patch attacks. The attackers holding a specially crafted patch can hide themselves from the state-of-the-art person detectors, e.g., YOLO, even in the physical world. This kind of attack can bring serious security threats, such as escaping from surveillance cameras. In this paper, we deeply explore the detection problems about the adversarial patch attacks to the object detection. First, we identify a leverageable signature of existing adversarial patches from the point of the visualization explanation. A fast signature-based defense method is proposed and demonstrated to be effective. Second, we design an improved patch generation algorithm to reveal the risk that the signature-based way may be bypassed by the techniques emerging in the future. The newly generated adversarial patches can successfully evade the proposed signature-based defense. Finally, we present a novel signature-independent detection method based on the internal content semantics consistency rather than any attack-specific prior knowledge. The fundamental intuition is that the adversarial object can appear locally but disappear globally in an input image. The experiments demonstrate that the signature-independent method can effectively detect the existing and improved attacks. It has also proven to be a general method by detecting unforeseen and even other types of attacks without any attack-specific prior knowledge. The two proposed detection methods can be adopted in different scenarios, and we believe that combining them can offer a comprehensive protection.