 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCLIP++: Learn to Rectify the Bias of CLIP for Unsupervised Semantic Segmentation
Paper and Code
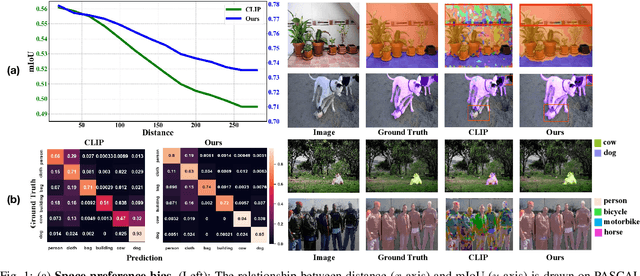
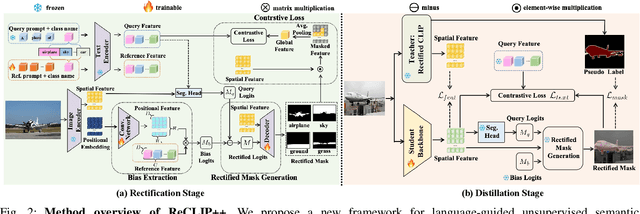
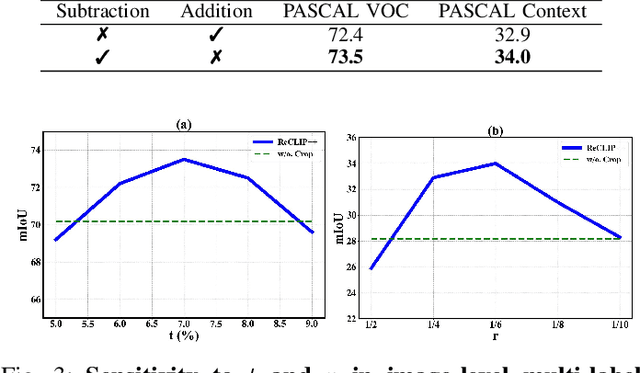

Recent works utilize CLIP to perform the challenging unsupervised semantic segmentation task where only images without annotations are available. However, we observe that when adopting CLIP to such a pixel-level understanding task, unexpected bias (including class-preference bias and space-preference bias) occurs. Previous works don't explicitly model the bias, which largely constrains the segmentation performance. In this paper, we propose to explicitly model and rectify the bias existing in CLIP to facilitate the unsupervised semantic segmentation task. Specifically, we design a learnable ''Reference'' prompt to encode class-preference bias and a projection of the positional embedding in vision transformer to encode space-preference bias respectively. To avoid interference, two kinds of biases are firstly independently encoded into the Reference feature and the positional feature. Via a matrix multiplication between two features, a bias logit map is generated to explicitly represent two kinds of biases. Then we rectify the logits of CLIP via a simple element-wise subtraction. To make the rectified results smoother and more contextual, we design a mask decoder which takes the feature of CLIP and rectified logits as input and outputs a rectified segmentation mask with the help of Gumbel-Softmax operation. To make the bias modeling and rectification process meaningful and effective, a contrastive loss based on masked visual features and the text features of different classes is imposed. To further improve the segmentation, we distill the knowledge from the rectified CLIP to the advanced segmentation architecture via minimizing our designed mask-guided, feature-guided and text-guided loss terms. Extensive experiments on various benchmarks demonstrate that ReCLIP++ performs favorably against previous SOTAs. The implementation is available at: https://github.com/dogehhh/ReCLIP.