 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVR-Met: A Hypothesis-Verification-Replaning Agentic System for Extreme Weather Diagnosis
Mar 01, 2026While deep learning-based weather forecasting paradigms have made significant strides, addressing extreme weather diagnostics remains a formidable challenge. This gap exists primarily because the diagnostic process demands sophisticated multi-step logical reasoning, dynamic tool invocation, and expert-level prior judgment. Although agents possess inherent advantages in task decomposition and autonomous execution, current architectures are still hampered by critical bottlenecks: inadequate expert knowledge integration, a lack of professional-grade iterative reasoning loops, and the absence of fine-grained validation and evaluation systems for complex workflows under extreme conditions. To this end, we propose HVR-Met, a multi-agent meteorological diagnostic system characterized by the deep integration of expert knowledge. Its central innovation is the ``Hypothesis-Verification-Replanning'' closed-loop mechanism, which facilitates sophisticated iterative reasoning for anomalous meteorological signals during extreme weather events. To bridge gaps within existing evaluation frameworks, we further introduce a novel benchmark focused on atomic-level subtasks. Experimental evidence demonstrates that the system excels in complex diagnostic scenarios.
ChartAgent: A Chart Understanding Framework with Tool Integrated Reasoning
Dec 16, 2025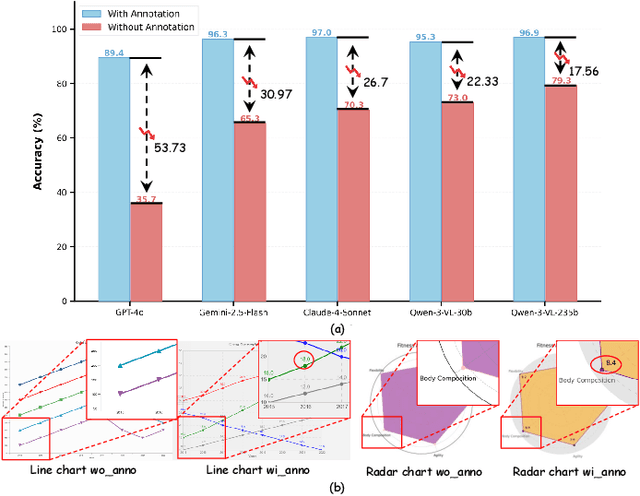
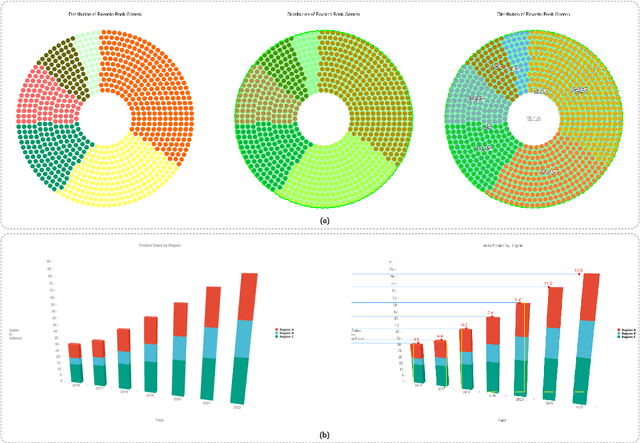
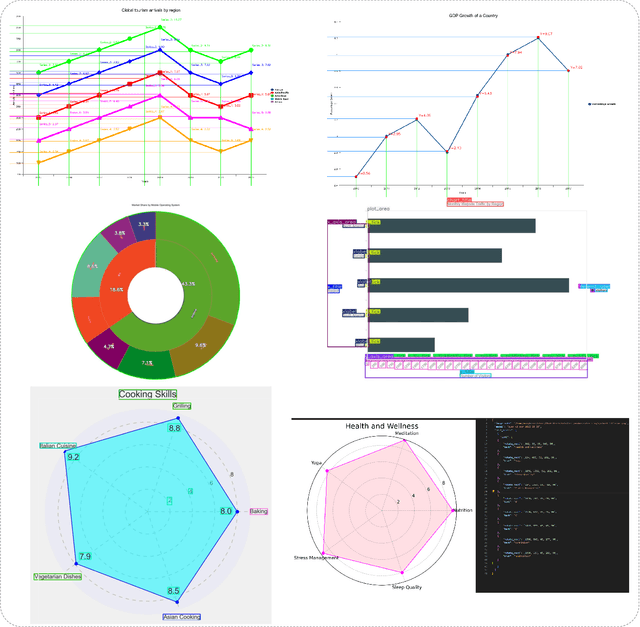
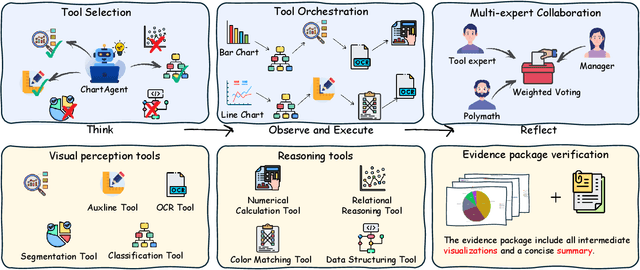
With their high information density and intuitive readability, charts have become the de facto medium for data analysis and communication across disciplines. Recent multimodal large language models (MLLMs) have made notable progress in automated chart understanding, yet they remain heavily dependent on explicit textual annotations and the performance degrades markedly when key numerals are absent. To address this limitation, we introduce ChartAgent, a chart understanding framework grounded in Tool-Integrated Reasoning (TIR). Inspired by human cognition, ChartAgent decomposes complex chart analysis into a sequence of observable, replayable steps. Supporting this architecture is an extensible, modular tool library comprising more than a dozen core tools, such as keyelement detection, instance segmentation, and optical character recognition (OCR), which the agent dynamically orchestrates to achieve systematic visual parsing across diverse chart types. Leveraging TIRs transparency and verifiability, ChartAgent moves beyond the black box paradigm by standardizing and consolidating intermediate outputs into a structured Evidence Package, providing traceable and reproducible support for final conclusions. Experiments show that ChartAgent substantially improves robustness under sparse annotation settings, offering a practical path toward trustworthy and extensible systems for chart understanding.
MeteorPred: A Meteorological Multimodal Large Model and Dataset for Severe Weather Event Prediction
Aug 09, 2025Timely and accurate severe weather warnings are critical for disaster mitigation. However, current forecasting systems remain heavily reliant on manual expert interpretation, introducing subjectivity and significant operational burdens. With the rapid development of AI technologies, the end-to-end "AI weather station" is gradually emerging as a new trend in predicting severe weather events. Three core challenges impede the development of end-to-end AI severe weather system: (1) scarcity of severe weather event samples; (2) imperfect alignment between high-dimensional meteorological data and textual warnings; (3) existing multimodal language models are unable to handle high-dimensional meteorological data and struggle to fully capture the complex dependencies across temporal sequences, vertical pressure levels, and spatial dimensions. To address these challenges, we introduce MP-Bench, the first large-scale temporal multimodal dataset for severe weather events prediction, comprising 421,363 pairs of raw multi-year meteorological data and corresponding text caption, covering a wide range of severe weather scenarios across China. On top of this dataset, we develop a meteorology multimodal large model (MMLM) that directly ingests 4D meteorological inputs. In addition, it is designed to accommodate the unique characteristics of 4D meteorological data flow, incorporating three plug-and-play adaptive fusion modules that enable dynamic feature extraction and integration across temporal sequences, vertical pressure layers, and spatial dimensions. Extensive experiments on MP-Bench demonstrate that MMLM performs exceptionally well across multiple tasks, highlighting its effectiveness in severe weather understanding and marking a key step toward realizing automated, AI-driven weather forecasting systems. Our source code and dataset will be made publicly available.
MV-MATH: Evaluating Multimodal Math Reasoning in Multi-Visual Contexts
Feb 28, 2025



Multimodal Large Language Models (MLLMs) have shown promising capabilities in mathematical reasoning within visual contexts across various datasets. However, most existing multimodal math benchmarks are limited to single-visual contexts, which diverges from the multi-visual scenarios commonly encountered in real-world mathematical applications. To address this gap, we introduce MV-MATH: a meticulously curated dataset of 2,009 high-quality mathematical problems. Each problem integrates multiple images interleaved with text, derived from authentic K-12 scenarios, and enriched with detailed annotations. MV-MATH includes multiple-choice, free-form, and multi-step questions, covering 11 subject areas across 3 difficulty levels, and serves as a comprehensive and rigorous benchmark for assessing MLLMs' mathematical reasoning in multi-visual contexts. Through extensive experimentation, we observe that MLLMs encounter substantial challenges in multi-visual math tasks, with a considerable performance gap relative to human capabilities on MV-MATH. Furthermore, we analyze the performance and error patterns of various models, providing insights into MLLMs' mathematical reasoning capabilities within multi-visual settings.
From Statistical Methods to Pre-Trained Models; A Survey on Automatic Speech Recognition for Resource Scarce Urdu Language
Nov 20, 2024



Automatic Speech Recognition (ASR) technology has witnessed significant advancements in recent years, revolutionizing human-computer interactions. While major languages have benefited from these developments, lesser-resourced languages like Urdu face unique challenges. This paper provides an extensive exploration of the dynamic landscape of ASR research, focusing particularly on the resource-constrained Urdu language, which is widely spoken across South Asian nations. It outlines current research trends, technological advancements, and potential directions for future studies in Urdu ASR, aiming to pave the way for forthcoming researchers interested in this domain. By leveraging contemporary technologies, analyzing existing datasets, and evaluating effective algorithms and tools, the paper seeks to shed light on the unique challenges and opportunities associated with Urdu language processing and its integration into the broader field of speech research.
GeoEval: Benchmark for Evaluating LLMs and Multi-Modal Models on Geometry Problem-Solving
Feb 15, 2024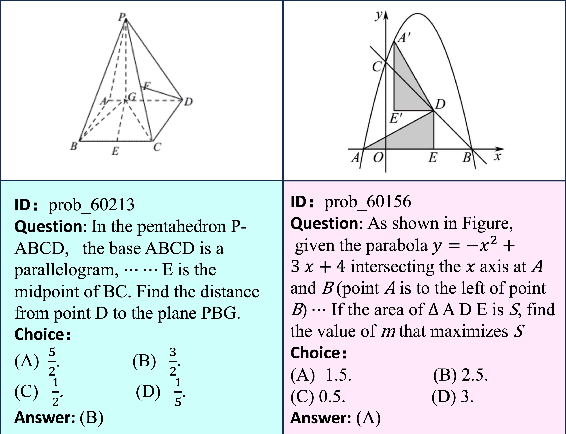
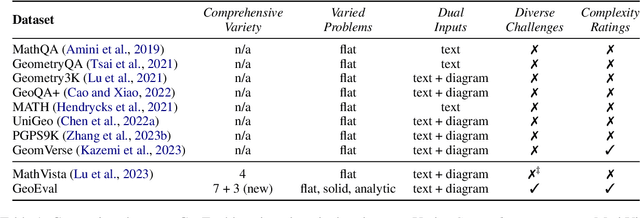
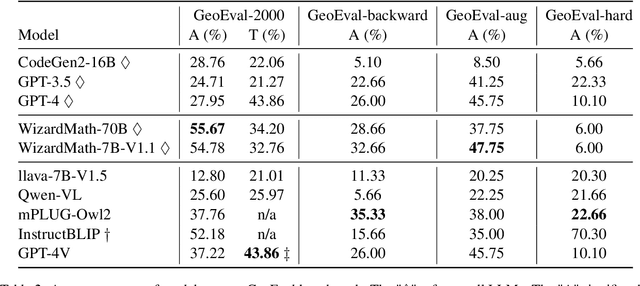
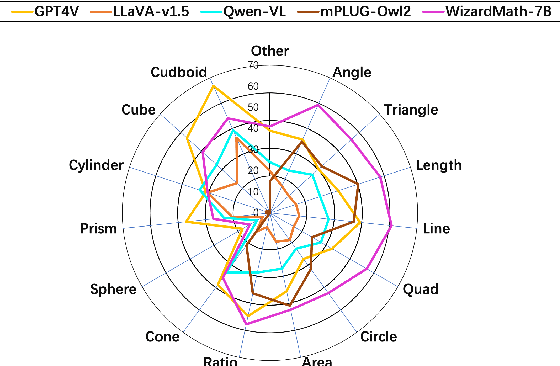
Recent advancements in Large Language Models (LLMs) and Multi-Modal Models (MMs) have demonstrated their remarkable capabilities in problem-solving. Yet, their proficiency in tackling geometry math problems, which necessitates an integrated understanding of both textual and visual information, has not been thoroughly evaluated. To address this gap, we introduce the GeoEval benchmark, a comprehensive collection that includes a main subset of 2000 problems, a 750 problem subset focusing on backward reasoning, an augmented subset of 2000 problems, and a hard subset of 300 problems. This benchmark facilitates a deeper investigation into the performance of LLMs and MMs on solving geometry math problems. Our evaluation of ten LLMs and MMs across these varied subsets reveals that the WizardMath model excels, achieving a 55.67\% accuracy rate on the main subset but only a 6.00\% accuracy on the challenging subset. This highlights the critical need for testing models against datasets on which they have not been pre-trained. Additionally, our findings indicate that GPT-series models perform more effectively on problems they have rephrased, suggesting a promising method for enhancing model capabilities.