 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonoNeuralFusion: Online Monocular Neural 3D Reconstruction with Geometric Priors
Paper and Code
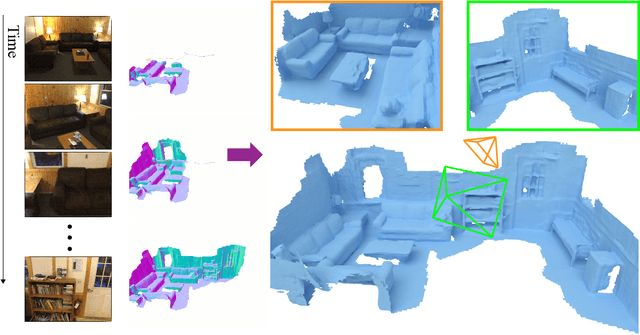
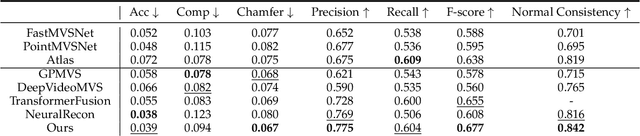
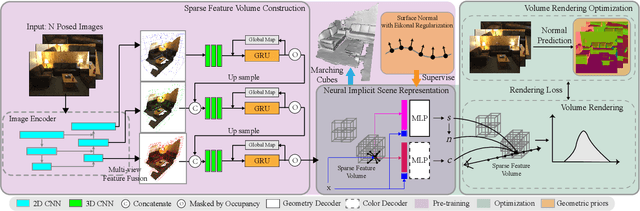
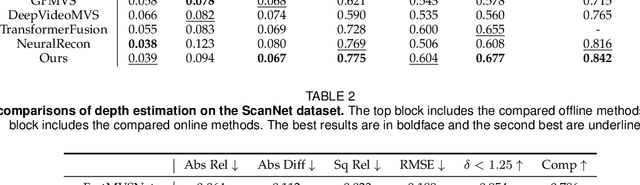
High-fidelity 3D scene reconstruction from monocular videos continues to be challenging, especially for complete and fine-grained geometry reconstruction. The previous 3D reconstruction approaches with neural implicit representations have shown a promising ability for complete scene reconstruction, while their results are often over-smooth and lack enough geometric details. This paper introduces a novel neural implicit scene representation with volume rendering for high-fidelity online 3D scene reconstruction from monocular videos. For fine-grained reconstruction, our key insight is to incorporate geometric priors into both the neural implicit scene representation and neural volume rendering, thus leading to an effective geometry learning mechanism based on volume rendering optimization. Benefiting from this, we present MonoNeuralFusion to perform the online neural 3D reconstruction from monocular videos, by which the 3D scene geometry is efficiently generated and optimized during the on-the-fly 3D monocular scanning. The extensive comparisons with state-of-the-art approaches show that our MonoNeuralFusion consistently generates much better complete and fine-grained reconstruction results, both quantitatively and qualitatively.