 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMENet: Joint 3D Semantic Scene Completion and 2D Semantic Segmentation through Iterative Mutual Enhancement
Paper and Code
Jun 29, 2021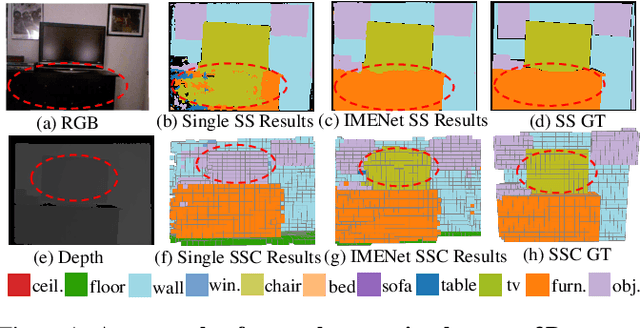
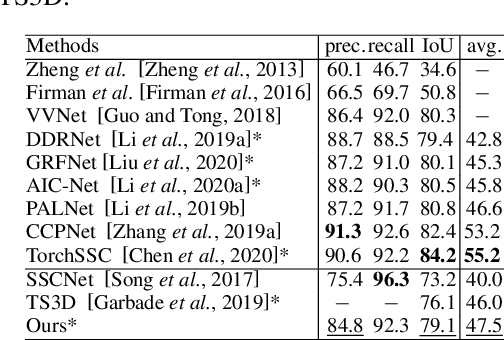
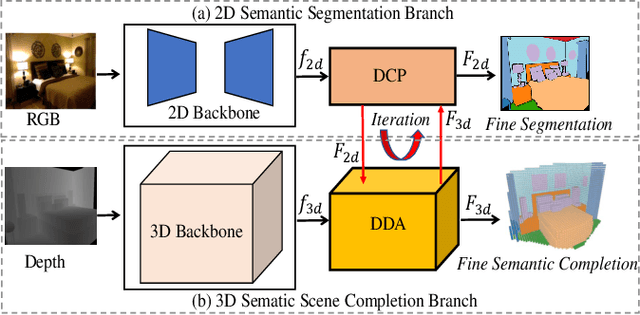
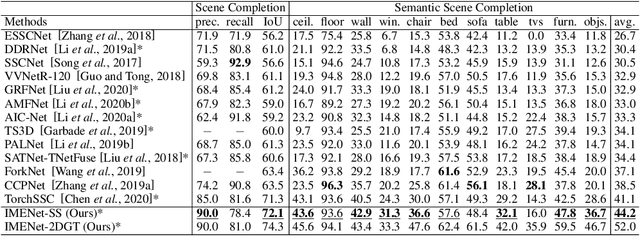
3D semantic scene completion and 2D semantic segmentation are two tightly correlated tasks that are both essential for indoor scene understanding, because they predict the same semantic classes, using positively correlated high-level features. Current methods use 2D features extracted from early-fused RGB-D images for 2D segmentation to improve 3D scene completion. We argue that this sequential scheme does not ensure these two tasks fully benefit each other, and present an Iterative Mutual Enhancement Network (IMENet) to solve them jointly, which interactively refines the two tasks at the late prediction stage. Specifically, two refinement modules are developed under a unified framework for the two tasks. The first is a 2D Deformable Context Pyramid (DCP) module, which receives the projection from the current 3D predictions to refine the 2D predictions. In turn, a 3D Deformable Depth Attention (DDA) module is proposed to leverage the reprojected results from 2D predictions to update the coarse 3D predictions. This iterative fusion happens to the stable high-level features of both tasks at a late stage. Extensive experiments on NYU and NYUCAD datasets verify the effectiveness of the proposed iterative late fusion scheme, and our approach outperforms the state of the art on both 3D semantic scene completion and 2D semantic segmentation.