 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModal-aware Features for Multimodal Hashing
Nov 19, 2019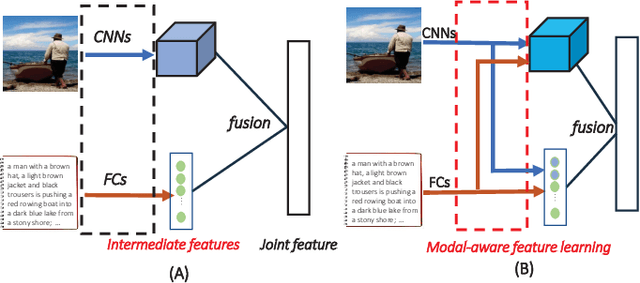


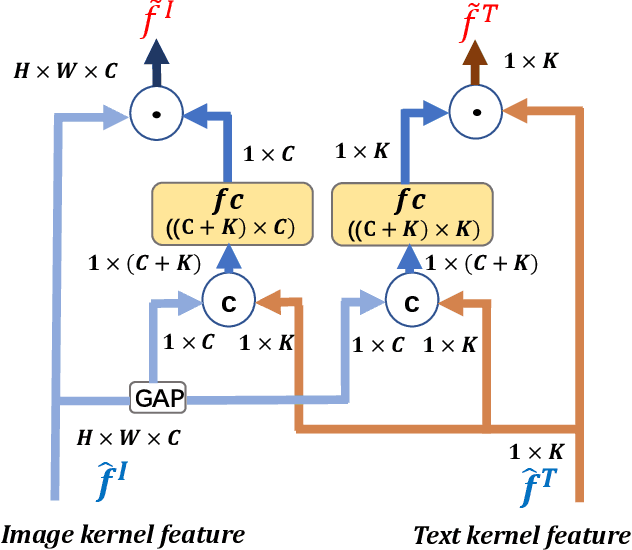
Many retrieval applications can benefit from multiple modalities, e.g., text that contains images on Wikipedia, for which how to represent multimodal data is the critical component. Most deep multimodal learning methods typically involve two steps to construct the joint representations: 1) learning of multiple intermediate features, with each intermediate feature corresponding to a modality, using separate and independent deep models; 2) merging the intermediate features into a joint representation using a fusion strategy. However, in the first step, these intermediate features do not have previous knowledge of each other and cannot fully exploit the information contained in the other modalities. In this paper, we present a modal-aware operation as a generic building block to capture the non-linear dependences among the heterogeneous intermediate features that can learn the underlying correlation structures in other multimodal data as soon as possible. The modal-aware operation consists of a kernel network and an attention network. The kernel network is utilized to learn the non-linear relationships with other modalities. Then, to learn better representations for binary hash codes, we present an attention network that finds the informative regions of these modal-aware features that are favorable for retrieval. Experiments conducted on three public benchmark datasets demonstrate significant improvements in the performance of our method relative to state-of-the-art methods.