 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Robust Calibration Strategy for Point-of-Gaze Estimation on Mobile Phones
Aug 14, 2025Although appearance-based point-of-gaze (PoG) estimation has improved, the estimators still struggle to generalize across individuals due to personal differences. Therefore, person-specific calibration is required for accurate PoG estimation. However, calibrated PoG estimators are often sensitive to head pose variations. To address this, we investigate the key factors influencing calibrated estimators and explore pose-robust calibration strategies. Specifically, we first construct a benchmark, MobilePoG, which includes facial images from 32 individuals focusing on designated points under either fixed or continuously changing head poses. Using this benchmark, we systematically analyze how the diversity of calibration points and head poses influences estimation accuracy. Our experiments show that introducing a wider range of head poses during calibration improves the estimator's ability to handle pose variation. Building on this insight, we propose a dynamic calibration strategy in which users fixate on calibration points while moving their phones. This strategy naturally introduces head pose variation during a user-friendly and efficient calibration process, ultimately producing a better calibrated PoG estimator that is less sensitive to head pose variations than those using conventional calibration strategies. Codes and datasets are available at our project page.
MAFW: A Large-scale, Multi-modal, Compound Affective Database for Dynamic Facial Expression Recognition in the Wild
Aug 01, 2022
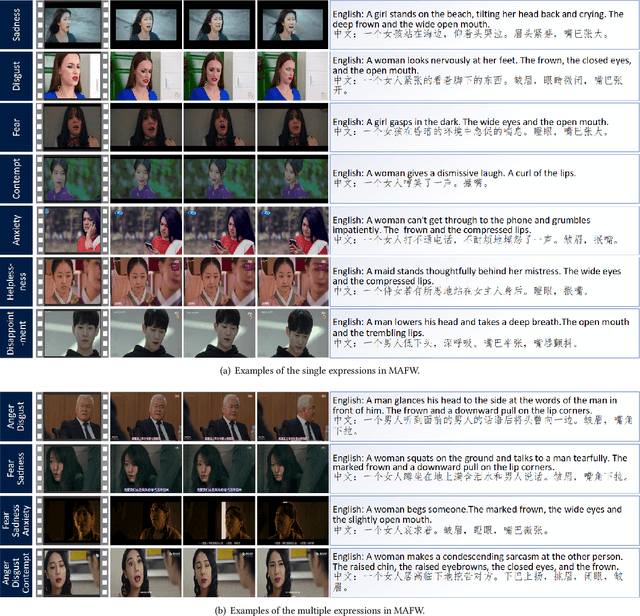
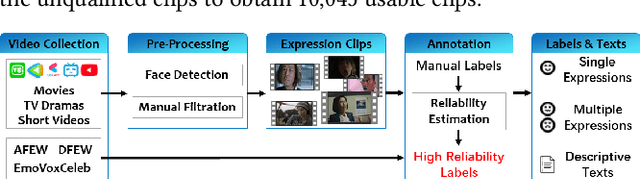
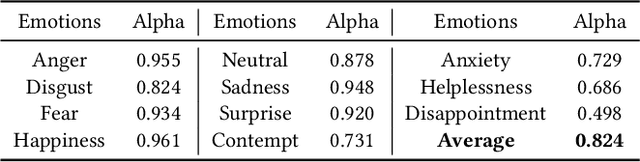
Dynamic facial expression recognition (FER) databases provide important data support for affective computing and applications. However, most FER databases are annotated with several basic mutually exclusive emotional categories and contain only one modality, e.g., videos. The monotonous labels and modality cannot accurately imitate human emotions and fulfill applications in the real world. In this paper, we propose MAFW, a large-scale multi-modal compound affective database with 10,045 video-audio clips in the wild. Each clip is annotated with a compound emotional category and a couple of sentences that describe the subjects' affective behaviors in the clip. For the compound emotion annotation, each clip is categorized into one or more of the 11 widely-used emotions, i.e., anger, disgust, fear, happiness, neutral, sadness, surprise, contempt, anxiety, helplessness, and disappointment. To ensure high quality of the labels, we filter out the unreliable annotations by an Expectation Maximization (EM) algorithm, and then obtain 11 single-label emotion categories and 32 multi-label emotion categories. To the best of our knowledge, MAFW is the first in-the-wild multi-modal database annotated with compound emotion annotations and emotion-related captions. Additionally, we also propose a novel Transformer-based expression snippet feature learning method to recognize the compound emotions leveraging the expression-change relations among different emotions and modalities. Extensive experiments on MAFW database show the advantages of the proposed method over other state-of-the-art methods for both uni- and multi-modal FER. Our MAFW database is publicly available from https://mafw-database.github.io/MAFW.
Gaze Estimation with an Ensemble of Four Architectures
Jul 05, 2021
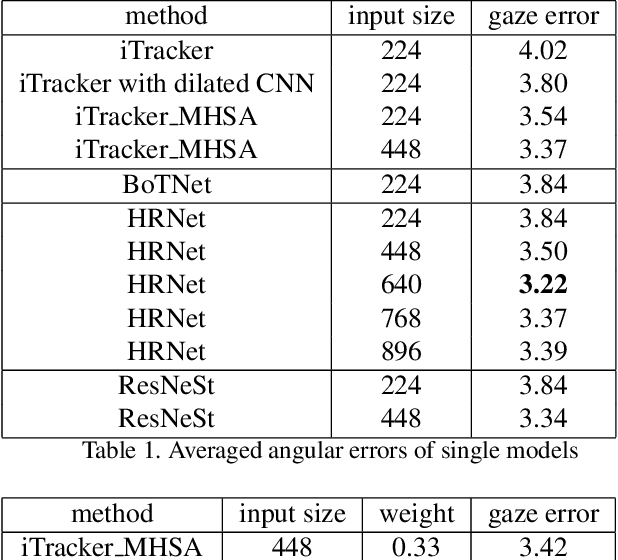
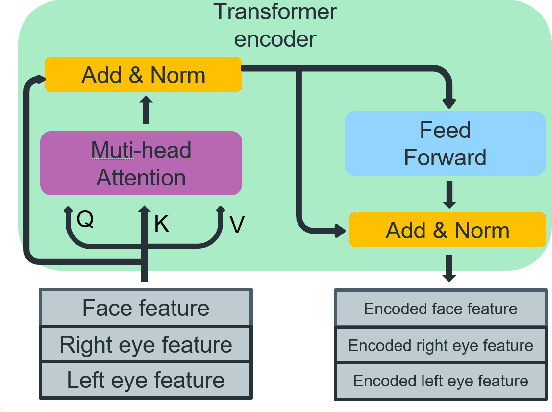
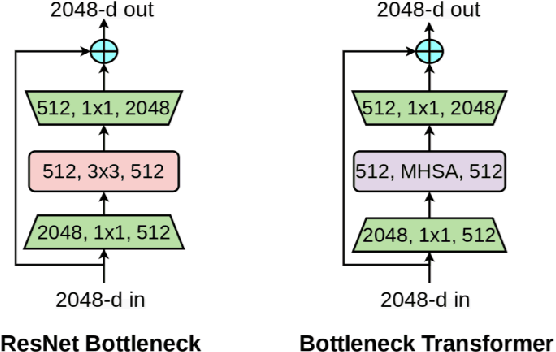
This paper presents a method for gaze estimation according to face images. We train several gaze estimators adopting four different network architectures, including an architecture designed for gaze estimation (i.e.,iTracker-MHSA) and three originally designed for general computer vision tasks(i.e., BoTNet, HRNet, ResNeSt). Then, we select the best six estimators and ensemble their predictions through a linear combination. The method ranks the first on the leader-board of ETH-XGaze Competition, achieving an average angular error of $3.11^{\circ}$ on the ETH-XGaze test set.
Emotion Recognition for In-the-wild Videos
Feb 13, 2020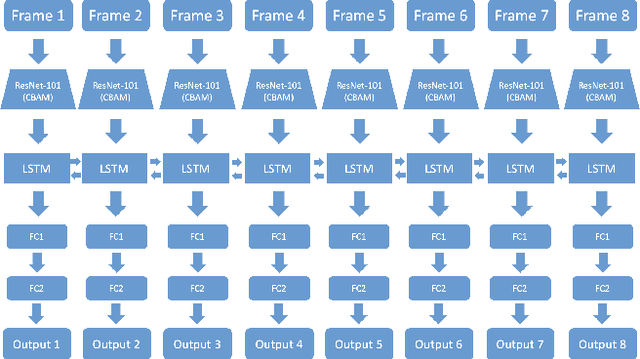
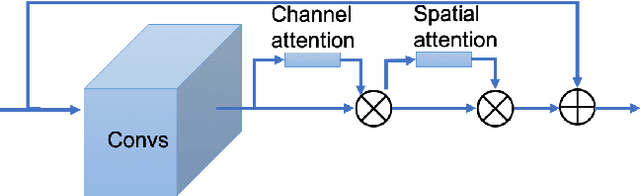
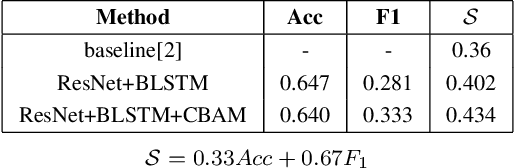
This paper is a brief introduction to our submission to the seven basic expression classification track of Affective Behavior Analysis in-the-wild Competition held in conjunction with the IEEE International Conference on Automatic Face and Gesture Recognition (FG) 2020. Our method combines Deep Residual Network (ResNet) and Bidirectional Long Short-Term Memory Network (BLSTM), achieving 64.3% accuracy and 43.4% final metric on the validation set.
$M^3$T: Multi-Modal Continuous Valence-Arousal Estimation in the Wild
Feb 07, 2020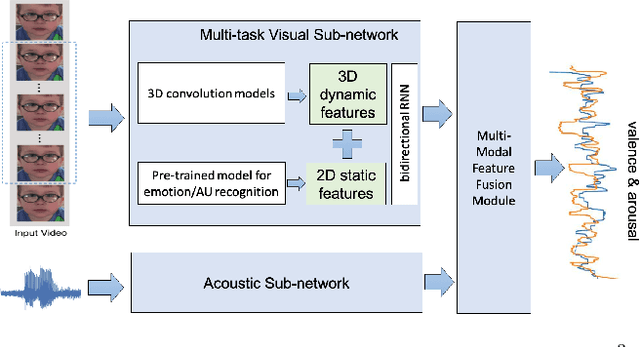
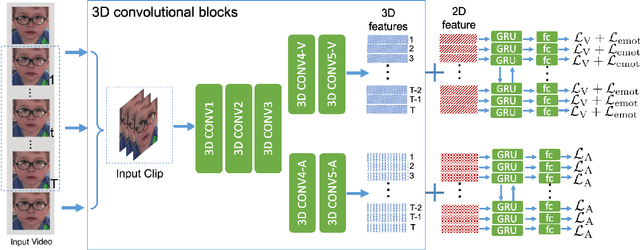
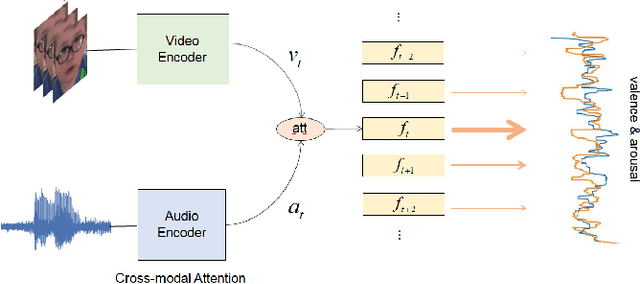
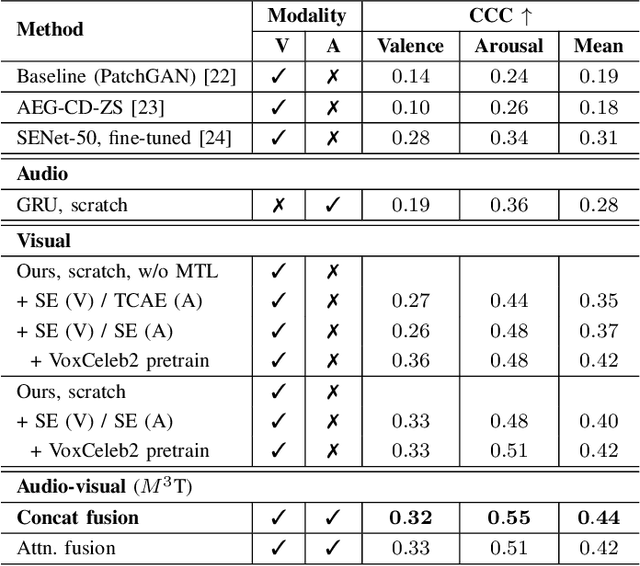
This report describes a multi-modal multi-task ($M^3$T) approach underlying our submission to the valence-arousal estimation track of the Affective Behavior Analysis in-the-wild (ABAW) Challenge, held in conjunction with the IEEE International Conference on Automatic Face and Gesture Recognition (FG) 2020. In the proposed $M^3$T framework, we fuse both visual features from videos and acoustic features from the audio tracks to estimate the valence and arousal. The spatio-temporal visual features are extracted with a 3D convolutional network and a bidirectional recurrent neural network. Considering the correlations between valence / arousal, emotions, and facial actions, we also explores mechanisms to benefit from other tasks. We evaluated the $M^3$T framework on the validation set provided by ABAW and it significantly outperforms the baseline method.
Pose-adaptive Hierarchical Attention Network for Facial Expression Recognition
May 24, 2019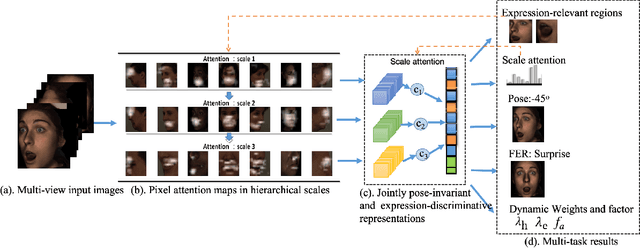


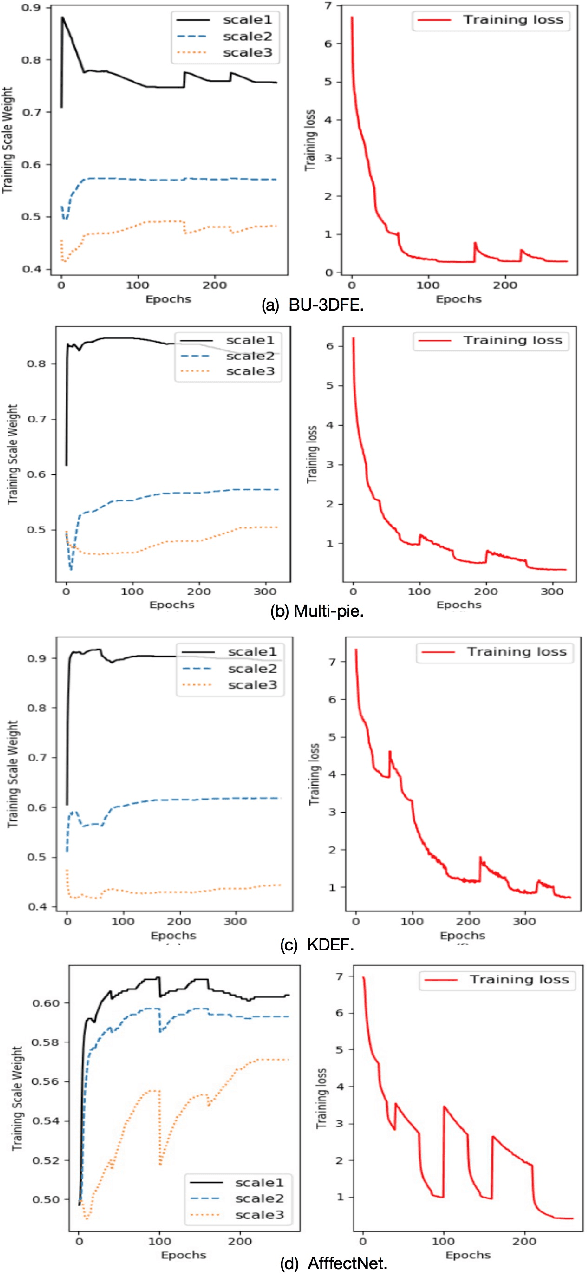
Multi-view facial expression recognition (FER) is a challenging task because the appearance of an expression varies in poses. To alleviate the influences of poses, recent methods either perform pose normalization or learn separate FER classifiers for each pose. However, these methods usually have two stages and rely on good performance of pose estimators. Different from existing methods, we propose a pose-adaptive hierarchical attention network (PhaNet) that can jointly recognize the facial expressions and poses in unconstrained environment. Specifically, PhaNet discovers the most relevant regions to the facial expression by an attention mechanism in hierarchical scales, and the most informative scales are then selected to learn the pose-invariant and expression-discriminative representations. PhaNet is end-to-end trainable by minimizing the hierarchical attention losses, the FER loss and pose loss with dynamically learned loss weights. We validate the effectiveness of the proposed PhaNet on three multi-view datasets (BU-3DFE, Multi-pie, and KDEF) and two in-the-wild FER datasets (AffectNet and SFEW). Extensive experiments demonstrate that our framework outperforms the state-of-the-arts under both within-dataset and cross-dataset settings, achieving the average accuracies of 84.92\%, 93.53\%, 88.5\%, 54.82\% and 31.25\% respectively.