 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAFW: A Large-scale, Multi-modal, Compound Affective Database for Dynamic Facial Expression Recognition in the Wild
Aug 01, 2022
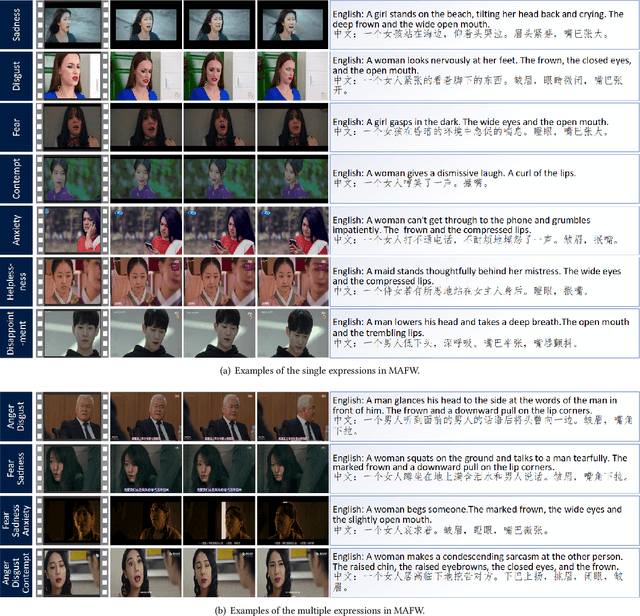
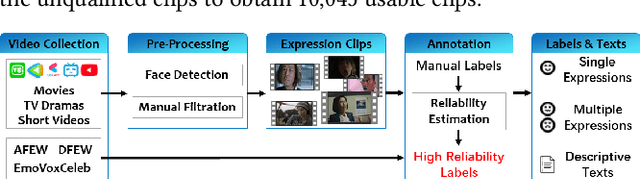
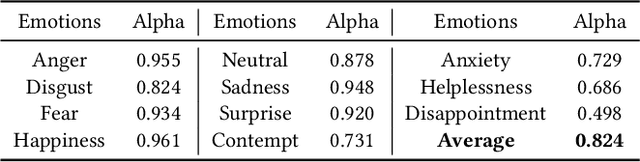
Dynamic facial expression recognition (FER) databases provide important data support for affective computing and applications. However, most FER databases are annotated with several basic mutually exclusive emotional categories and contain only one modality, e.g., videos. The monotonous labels and modality cannot accurately imitate human emotions and fulfill applications in the real world. In this paper, we propose MAFW, a large-scale multi-modal compound affective database with 10,045 video-audio clips in the wild. Each clip is annotated with a compound emotional category and a couple of sentences that describe the subjects' affective behaviors in the clip. For the compound emotion annotation, each clip is categorized into one or more of the 11 widely-used emotions, i.e., anger, disgust, fear, happiness, neutral, sadness, surprise, contempt, anxiety, helplessness, and disappointment. To ensure high quality of the labels, we filter out the unreliable annotations by an Expectation Maximization (EM) algorithm, and then obtain 11 single-label emotion categories and 32 multi-label emotion categories. To the best of our knowledge, MAFW is the first in-the-wild multi-modal database annotated with compound emotion annotations and emotion-related captions. Additionally, we also propose a novel Transformer-based expression snippet feature learning method to recognize the compound emotions leveraging the expression-change relations among different emotions and modalities. Extensive experiments on MAFW database show the advantages of the proposed method over other state-of-the-art methods for both uni- and multi-modal FER. Our MAFW database is publicly available from https://mafw-database.github.io/MAFW.
Expression Snippet Transformer for Robust Video-based Facial Expression Recognition
Sep 17, 2021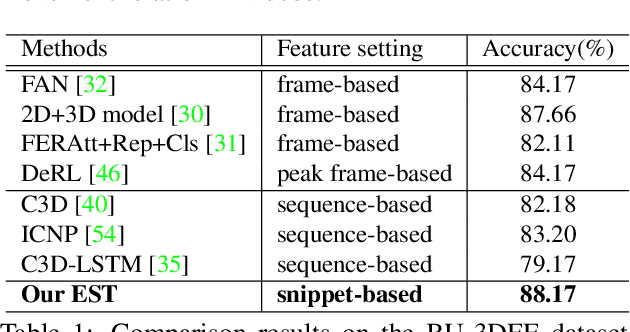
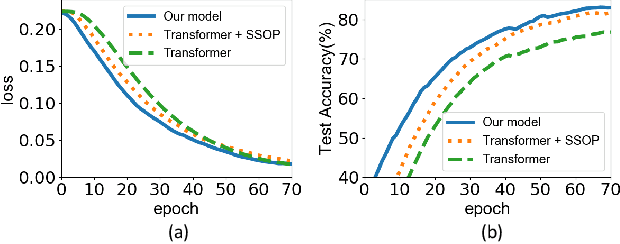
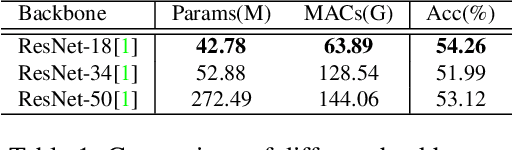
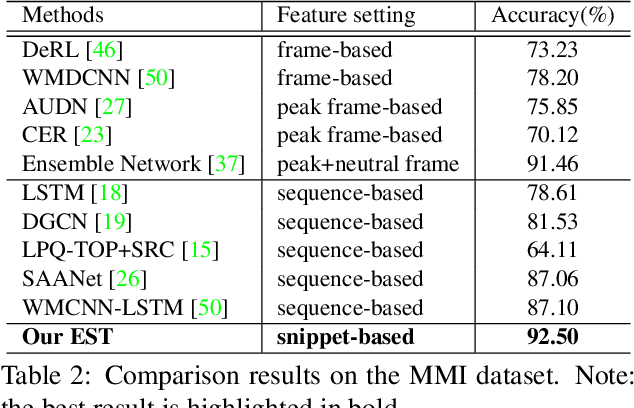
The recent success of Transformer has provided a new direction to various visual understanding tasks, including video-based facial expression recognition (FER). By modeling visual relations effectively, Transformer has shown its power for describing complicated patterns. However, Transformer still performs unsatisfactorily to notice subtle facial expression movements, because the expression movements of many videos can be too small to extract meaningful spatial-temporal relations and achieve robust performance. To this end, we propose to decompose each video into a series of expression snippets, each of which contains a small number of facial movements, and attempt to augment the Transformer's ability for modeling intra-snippet and inter-snippet visual relations, respectively, obtaining the Expression snippet Transformer (EST). In particular, for intra-snippet modeling, we devise an attention-augmented snippet feature extractor (AA-SFE) to enhance the encoding of subtle facial movements of each snippet by gradually attending to more salient information. In addition, for inter-snippet modeling, we introduce a shuffled snippet order prediction (SSOP) head and a corresponding loss to improve the modeling of subtle motion changes across subsequent snippets by training the Transformer to identify shuffled snippet orders. Extensive experiments on four challenging datasets (i.e., BU-3DFE, MMI, AFEW, and DFEW) demonstrate that our EST is superior to other CNN-based methods, obtaining state-of-the-art performance.