 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpression Snippet Transformer for Robust Video-based Facial Expression Recognition
Paper and Code
Sep 17, 2021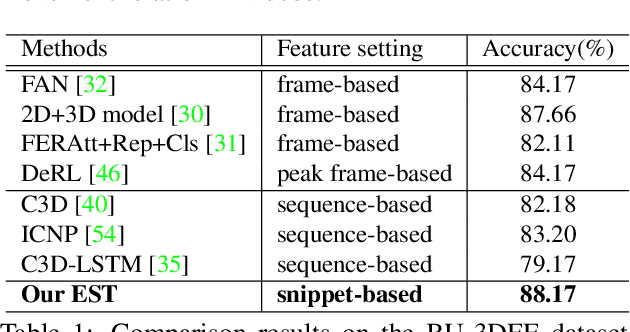
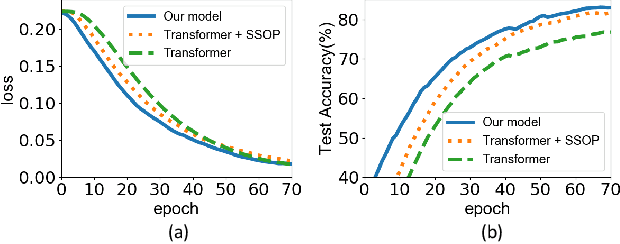
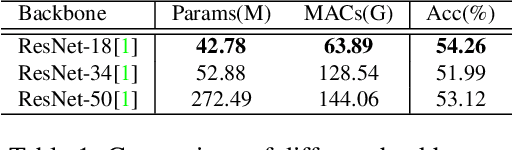
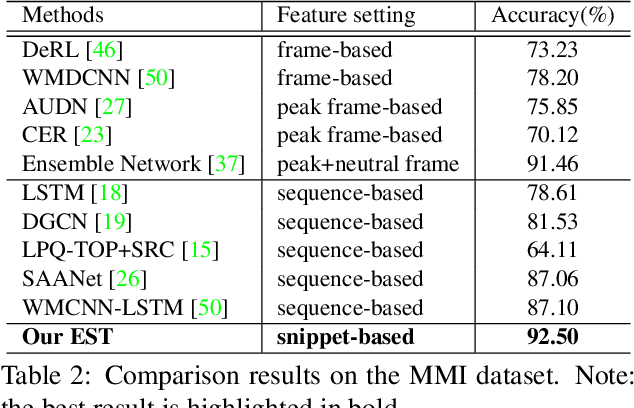
The recent success of Transformer has provided a new direction to various visual understanding tasks, including video-based facial expression recognition (FER). By modeling visual relations effectively, Transformer has shown its power for describing complicated patterns. However, Transformer still performs unsatisfactorily to notice subtle facial expression movements, because the expression movements of many videos can be too small to extract meaningful spatial-temporal relations and achieve robust performance. To this end, we propose to decompose each video into a series of expression snippets, each of which contains a small number of facial movements, and attempt to augment the Transformer's ability for modeling intra-snippet and inter-snippet visual relations, respectively, obtaining the Expression snippet Transformer (EST). In particular, for intra-snippet modeling, we devise an attention-augmented snippet feature extractor (AA-SFE) to enhance the encoding of subtle facial movements of each snippet by gradually attending to more salient information. In addition, for inter-snippet modeling, we introduce a shuffled snippet order prediction (SSOP) head and a corresponding loss to improve the modeling of subtle motion changes across subsequent snippets by training the Transformer to identify shuffled snippet orders. Extensive experiments on four challenging datasets (i.e., BU-3DFE, MMI, AFEW, and DFEW) demonstrate that our EST is superior to other CNN-based methods, obtaining state-of-the-art performance.