 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-adaptive Hierarchical Attention Network for Facial Expression Recognition
May 24, 2019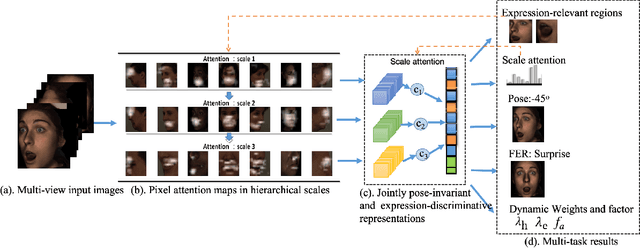


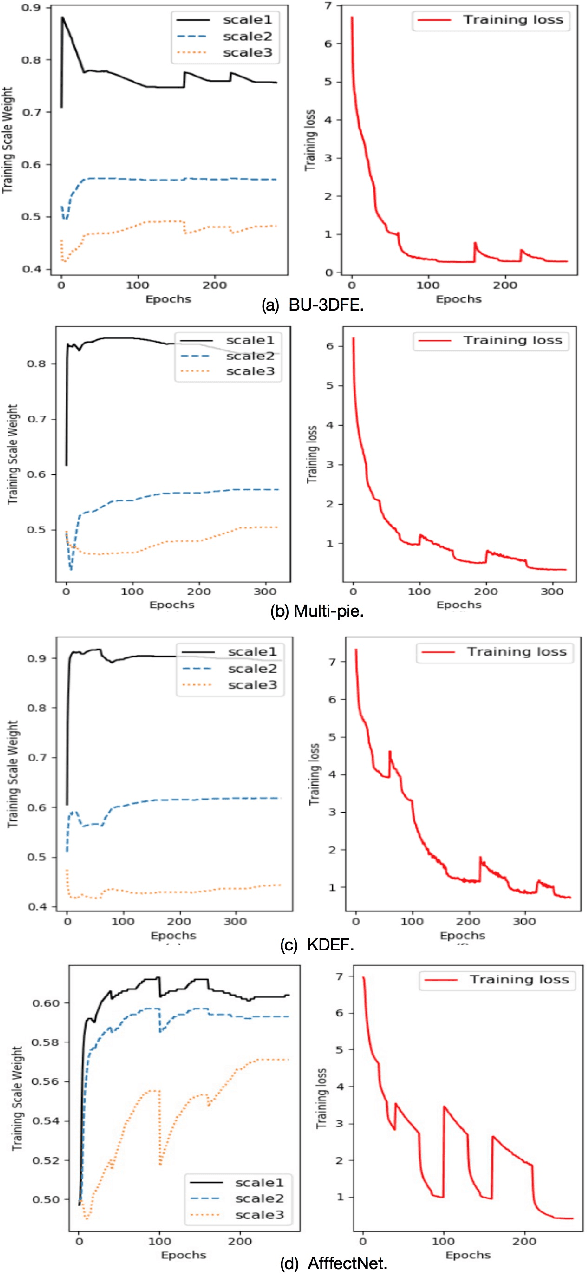
Multi-view facial expression recognition (FER) is a challenging task because the appearance of an expression varies in poses. To alleviate the influences of poses, recent methods either perform pose normalization or learn separate FER classifiers for each pose. However, these methods usually have two stages and rely on good performance of pose estimators. Different from existing methods, we propose a pose-adaptive hierarchical attention network (PhaNet) that can jointly recognize the facial expressions and poses in unconstrained environment. Specifically, PhaNet discovers the most relevant regions to the facial expression by an attention mechanism in hierarchical scales, and the most informative scales are then selected to learn the pose-invariant and expression-discriminative representations. PhaNet is end-to-end trainable by minimizing the hierarchical attention losses, the FER loss and pose loss with dynamically learned loss weights. We validate the effectiveness of the proposed PhaNet on three multi-view datasets (BU-3DFE, Multi-pie, and KDEF) and two in-the-wild FER datasets (AffectNet and SFEW). Extensive experiments demonstrate that our framework outperforms the state-of-the-arts under both within-dataset and cross-dataset settings, achieving the average accuracies of 84.92\%, 93.53\%, 88.5\%, 54.82\% and 31.25\% respectively.