 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$M^3$T: Multi-Modal Continuous Valence-Arousal Estimation in the Wild
Paper and Code
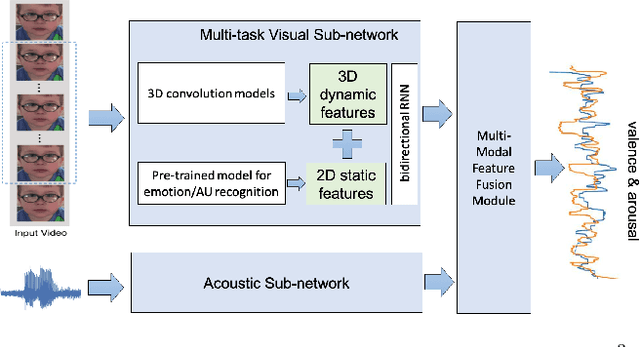
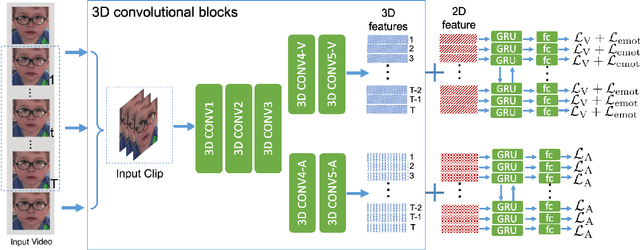
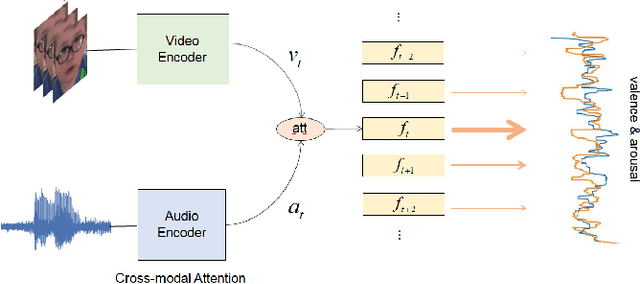
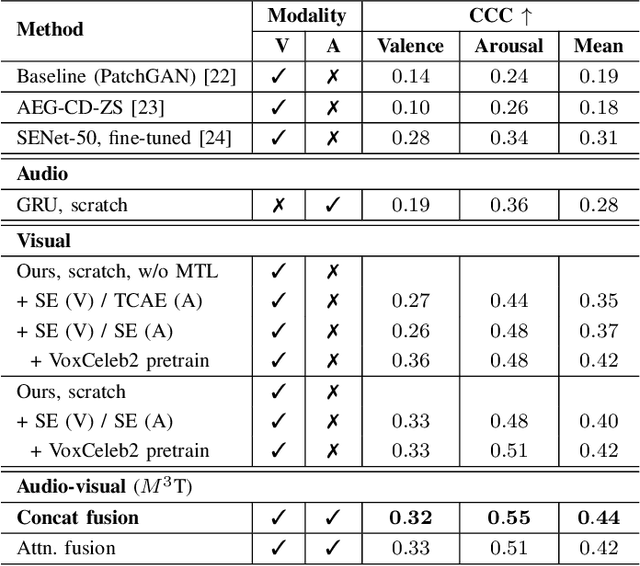
This report describes a multi-modal multi-task ($M^3$T) approach underlying our submission to the valence-arousal estimation track of the Affective Behavior Analysis in-the-wild (ABAW) Challenge, held in conjunction with the IEEE International Conference on Automatic Face and Gesture Recognition (FG) 2020. In the proposed $M^3$T framework, we fuse both visual features from videos and acoustic features from the audio tracks to estimate the valence and arousal. The spatio-temporal visual features are extracted with a 3D convolutional network and a bidirectional recurrent neural network. Considering the correlations between valence / arousal, emotions, and facial actions, we also explores mechanisms to benefit from other tasks. We evaluated the $M^3$T framework on the validation set provided by ABAW and it significantly outperforms the baseline method.