 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep transfer learning for system identification using long short-term memory neural networks
Apr 06, 2022
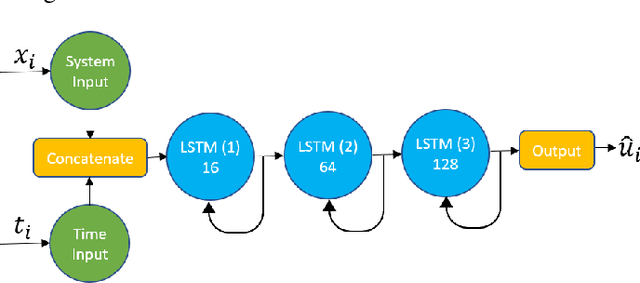
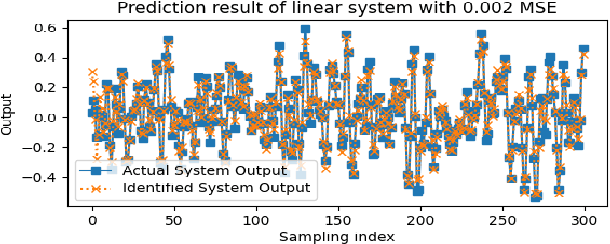
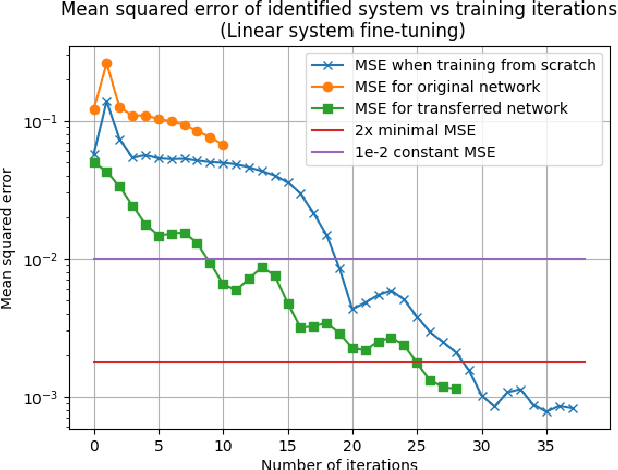
Recurrent neural networks (RNNs) have many advantages over more traditional system identification techniques. They may be applied to linear and nonlinear systems, and they require fewer modeling assumptions. However, these neural network models may also need larger amounts of data to learn and generalize. Furthermore, neural networks training is a time-consuming process. Hence, building upon long-short term memory neural networks (LSTM), this paper proposes using two types of deep transfer learning, namely parameter fine-tuning and freezing, to reduce the data and computation requirements for system identification. We apply these techniques to identify two dynamical systems, namely a second-order linear system and a Wiener-Hammerstein nonlinear system. Results show that compared with direct learning, our method accelerates learning by 10% to 50%, which also saves data and computing resources.
The Effect of Training Parameters and Mechanisms on Decentralized Federated Learning based on MNIST Dataset
Aug 07, 2021


Federated Learning is an algorithm suited for training models on decentralized data, but the requirement of a central "server" node is a bottleneck. In this document, we first introduce the notion of Decentralized Federated Learning (DFL). We then perform various experiments on different setups, such as changing model aggregation frequency, switching from independent and identically distributed (IID) dataset partitioning to non-IID partitioning with partial global sharing, using different optimization methods across clients, and breaking models into segments with partial sharing. All experiments are run on the MNIST handwritten digits dataset. We observe that those altered training procedures are generally robust, albeit non-optimal. We also observe failures in training when the variance between model weights is too large. The open-source experiment code is accessible through GitHub\footnote{Code was uploaded at \url{https://github.com/zhzhang2018/DecentralizedFL}}.