 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Diffusion Scopes with Parameterized Laplacian for Heterophilic Graph Learning
Sep 15, 2024



The ability of Graph Neural Networks (GNNs) to capture long-range and global topology information is limited by the scope of conventional graph Laplacian, leading to unsatisfactory performance on some datasets, particularly on heterophilic graphs. To address this limitation, we propose a new class of parameterized Laplacian matrices, which provably offers more flexibility in controlling the diffusion distance between nodes than the conventional graph Laplacian, allowing long-range information to be adaptively captured through diffusion on graph. Specifically, we first prove that the diffusion distance and spectral distance on graph have an order-preserving relationship. With this result, we demonstrate that the parameterized Laplacian can accelerate the diffusion of long-range information, and the parameters in the Laplacian enable flexibility of the diffusion scopes. Based on the theoretical results, we propose topology-guided rewiring mechanism to capture helpful long-range neighborhood information for heterophilic graphs. With this mechanism and the new Laplacian, we propose two GNNs with flexible diffusion scopes: namely the Parameterized Diffusion based Graph Convolutional Networks (PD-GCN) and Graph Attention Networks (PD-GAT). Synthetic experiments reveal the high correlations between the parameters of the new Laplacian and the performance of parameterized GNNs under various graph homophily levels, which verifies that our new proposed GNNs indeed have the ability to adjust the parameters to adaptively capture the global information for different levels of heterophilic graphs. They also outperform the state-of-the-art (SOTA) models on 6 out of 7 real-world benchmark datasets, which further confirms their superiority.
Are Heterophily-Specific GNNs and Homophily Metrics Really Effective? Evaluation Pitfalls and New Benchmarks
Sep 09, 2024



Over the past decade, Graph Neural Networks (GNNs) have achieved great success on machine learning tasks with relational data. However, recent studies have found that heterophily can cause significant performance degradation of GNNs, especially on node-level tasks. Numerous heterophilic benchmark datasets have been put forward to validate the efficacy of heterophily-specific GNNs and various homophily metrics have been designed to help people recognize these malignant datasets. Nevertheless, there still exist multiple pitfalls that severely hinder the proper evaluation of new models and metrics. In this paper, we point out three most serious pitfalls: 1) a lack of hyperparameter tuning; 2) insufficient model evaluation on the real challenging heterophilic datasets; 3) missing quantitative evaluation benchmark for homophily metrics on synthetic graphs. To overcome these challenges, we first train and fine-tune baseline models on $27$ most widely used benchmark datasets, categorize them into three distinct groups: malignant, benign and ambiguous heterophilic datasets, and identify the real challenging subsets of tasks. To our best knowledge, we are the first to propose such taxonomy. Then, we re-evaluate $10$ heterophily-specific state-of-the-arts (SOTA) GNNs with fine-tuned hyperparameters on different groups of heterophilic datasets. Based on the model performance, we reassess their effectiveness on addressing heterophily challenge. At last, we evaluate $11$ popular homophily metrics on synthetic graphs with three different generation approaches. To compare the metrics strictly, we propose the first quantitative evaluation method based on Fr\'echet distance.
The Heterophilic Graph Learning Handbook: Benchmarks, Models, Theoretical Analysis, Applications and Challenges
Jul 12, 2024



Homophily principle, \ie{} nodes with the same labels or similar attributes are more likely to be connected, has been commonly believed to be the main reason for the superiority of Graph Neural Networks (GNNs) over traditional Neural Networks (NNs) on graph-structured data, especially on node-level tasks. However, recent work has identified a non-trivial set of datasets where GNN's performance compared to the NN's is not satisfactory. Heterophily, i.e. low homophily, has been considered the main cause of this empirical observation. People have begun to revisit and re-evaluate most existing graph models, including graph transformer and its variants, in the heterophily scenario across various kinds of graphs, e.g. heterogeneous graphs, temporal graphs and hypergraphs. Moreover, numerous graph-related applications are found to be closely related to the heterophily problem. In the past few years, considerable effort has been devoted to studying and addressing the heterophily issue. In this survey, we provide a comprehensive review of the latest progress on heterophilic graph learning, including an extensive summary of benchmark datasets and evaluation of homophily metrics on synthetic graphs, meticulous classification of the most updated supervised and unsupervised learning methods, thorough digestion of the theoretical analysis on homophily/heterophily, and broad exploration of the heterophily-related applications. Notably, through detailed experiments, we are the first to categorize benchmark heterophilic datasets into three sub-categories: malignant, benign and ambiguous heterophily. Malignant and ambiguous datasets are identified as the real challenging datasets to test the effectiveness of new models on the heterophily challenge. Finally, we propose several challenges and future directions for heterophilic graph representation learning.
GCEPNet: Graph Convolution-Enhanced Expectation Propagation for Massive MIMO Detection
Apr 23, 2024


Massive MIMO (multiple-input multiple-output) detection is an important topic in wireless communication and various machine learning based methods have been developed recently for this task. Expectation propagation (EP) and its variants are widely used for MIMO detection and have achieved the best performance. However, EP-based solvers fail to capture the correlation between unknown variables, leading to loss of information, and in addition, they are computationally expensive. In this paper, we show that the real-valued system can be modeled as spectral signal convolution on graph, through which the correlation between unknown variables can be captured. Based on this analysis, we propose graph convolution-enhanced expectation propagation (GCEPNet), a graph convolution-enhanced EP detector. GCEPNet incorporates data-dependent attention scores into Chebyshev polynomial for powerful graph convolution with better generalization capacity. It enables a better estimation of the cavity distribution for EP and empirically achieves the state-of-the-art (SOTA) MIMO detection performance with much faster inference speed. To our knowledge, we are the first to shed light on the connection between the system model and graph convolution, and the first to design the data-dependent attention scores for graph convolution.
Representation Learning on Heterophilic Graph with Directional Neighborhood Attention
Mar 03, 2024



Graph Attention Network (GAT) is one of the most popular Graph Neural Network (GNN) architecture, which employs the attention mechanism to learn edge weights and has demonstrated promising performance in various applications. However, since it only incorporates information from immediate neighborhood, it lacks the ability to capture long-range and global graph information, leading to unsatisfactory performance on some datasets, particularly on heterophilic graphs. To address this limitation, we propose the Directional Graph Attention Network (DGAT) in this paper. DGAT is able to combine the feature-based attention with the global directional information extracted from the graph topology. To this end, a new class of Laplacian matrices is proposed which can provably reduce the diffusion distance between nodes. Based on the new Laplacian, topology-guided neighbour pruning and edge adding mechanisms are proposed to remove the noisy and capture the helpful long-range neighborhood information. Besides, a global directional attention is designed to enable a topological-aware information propagation. The superiority of the proposed DGAT over the baseline GAT has also been verified through experiments on real-world benchmarks and synthetic data sets. It also outperforms the state-of-the-art (SOTA) models on 6 out of 7 real-world benchmark datasets.
Bidirectional Generative Pre-training for Improving Time Series Representation Learning
Feb 14, 2024Learning time-series representations for discriminative tasks has been a long-standing challenge. Current pre-training methods are limited in either unidirectional next-token prediction or randomly masked token prediction. We propose a novel architecture called Bidirectional Timely Generative Pre-trained Transformer (BiTimelyGPT), which pre-trains on time-series data by both next-token and previous-token predictions in alternating transformer layers. This pre-training task preserves original distribution and data shapes of the time-series. Additionally, the full-rank forward and backward attention matrices exhibit more expressive representation capabilities. Using biosignal data, BiTimelyGPT demonstrates superior performance in predicting neurological functionality, disease diagnosis, and physiological signs. By visualizing the attention heatmap, we observe that the pre-trained BiTimelyGPT can identify discriminative segments from time-series sequences, even more so after fine-tuning on the task.
TimelyGPT: Recurrent Convolutional Transformer for Long Time-series Representation
Nov 29, 2023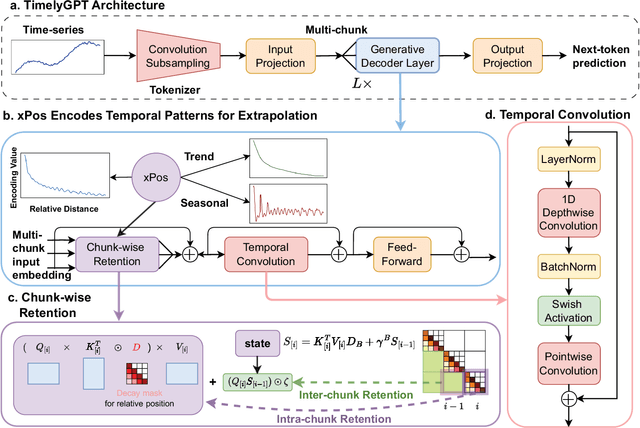

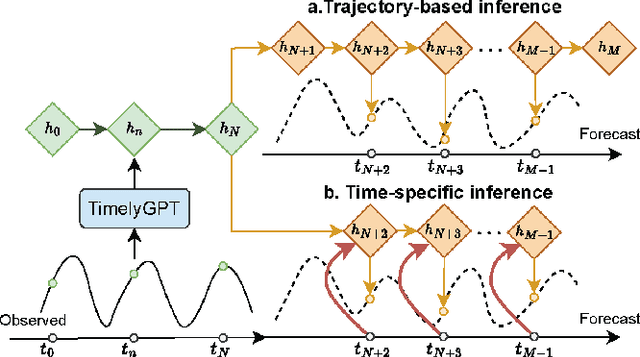

Pre-trained models (PTMs) have gained prominence in Natural Language Processing and Computer Vision domains. When it comes to time-series PTMs, their development has been limited. Previous research on time-series transformers has mainly been devoted to small-scale tasks, yet these models have not consistently outperformed traditional models. Additionally, the performance of these transformers on large-scale data remains unexplored. These findings raise doubts about Transformer's capabilities to scale up and capture temporal dependencies. In this study, we re-examine time-series transformers and identify the shortcomings of prior studies. Drawing from these insights, we then introduce a pioneering architecture called Timely Generative Pre-trained Transformer (\model). This architecture integrates recurrent attention and temporal convolution modules to effectively capture global-local temporal dependencies in long sequences. The relative position embedding with time decay can effectively deal with trend and periodic patterns from time-series. Our experiments show that \model~excels in modeling continuously monitored biosignal as well as irregularly-sampled time-series data commonly observed in longitudinal electronic health records. This breakthrough suggests a priority shift in time-series deep learning research, moving from small-scale modeling from scratch to large-scale pre-training.
When Do Graph Neural Networks Help with Node Classification: Investigating the Homophily Principle on Node Distinguishability
Apr 25, 2023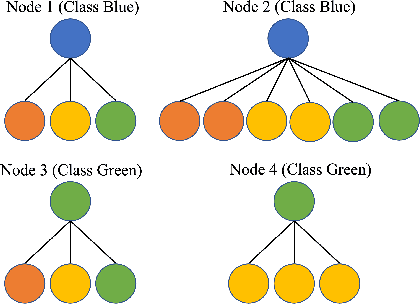
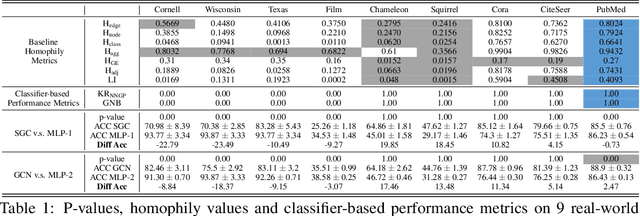
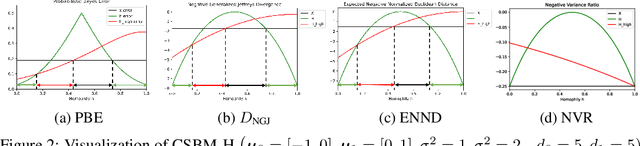
Homophily principle, i.e. nodes with the same labels are more likely to be connected, was believed to be the main reason for the performance superiority of Graph Neural Networks (GNNs) over Neural Networks (NNs) on Node Classification (NC) tasks. Recently, people have developed theoretical results arguing that, even though the homophily principle is broken, the advantage of GNNs can still hold as long as nodes from the same class share similar neighborhood patterns, which questions the validity of homophily. However, this argument only considers intra-class Node Distinguishability (ND) and ignores inter-class ND, which is insufficient to study the effect of homophily. In this paper, we first demonstrate the aforementioned insufficiency with examples and argue that an ideal situation for ND is to have smaller intra-class ND than inter-class ND. To formulate this idea and have a better understanding of homophily, we propose Contextual Stochastic Block Model for Homophily (CSBM-H) and define two metrics, Probabilistic Bayes Error (PBE) and Expected Negative KL-divergence (ENKL), to quantify ND, through which we can also find how intra- and inter-class ND influence ND together. We visualize the results and give detailed analysis. Through experiments, we verified that the superiority of GNNs is indeed closely related to both intra- and inter-class ND regardless of homophily levels, based on which we define Kernel Performance Metric (KPM). KPM is a new non-linear, feature-based metric, which is tested to be more effective than the existing homophily metrics on revealing the advantage and disadvantage of GNNs on synthetic and real-world datasets.
When Do We Need GNN for Node Classification?
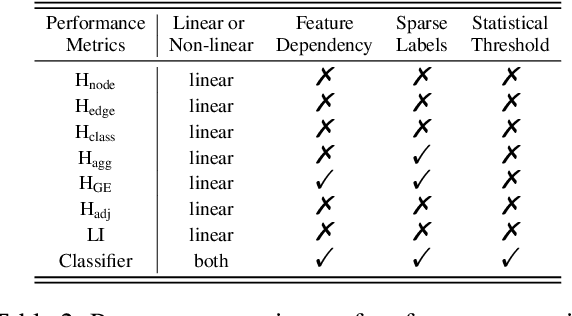
Oct 30, 2022Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by additionally making use of graph structure based on the relational inductive bias (edge bias), rather than treating the nodes as collections of independent and identically distributed (\iid) samples. Though GNNs are believed to outperform basic NNs in real-world tasks, it is found that in some cases, GNNs have little performance gain or even underperform graph-agnostic NNs. To identify these cases, based on graph signal processing and statistical hypothesis testing, we propose two measures which analyze the cases in which the edge bias in features and labels does not provide advantages. Based on the measures, a threshold value can be given to predict the potential performance advantages of graph-aware models over graph-agnostic models.
Revisiting Heterophily For Graph Neural Networks
Oct 14, 2022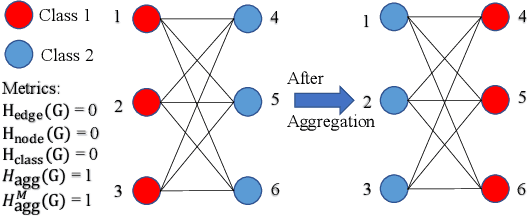
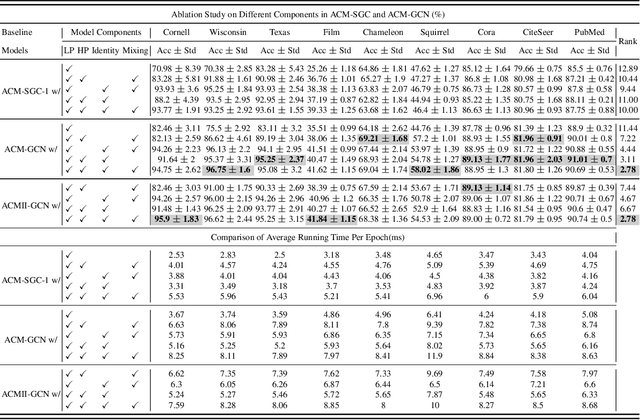
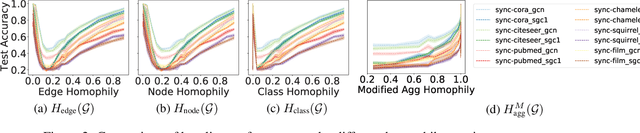
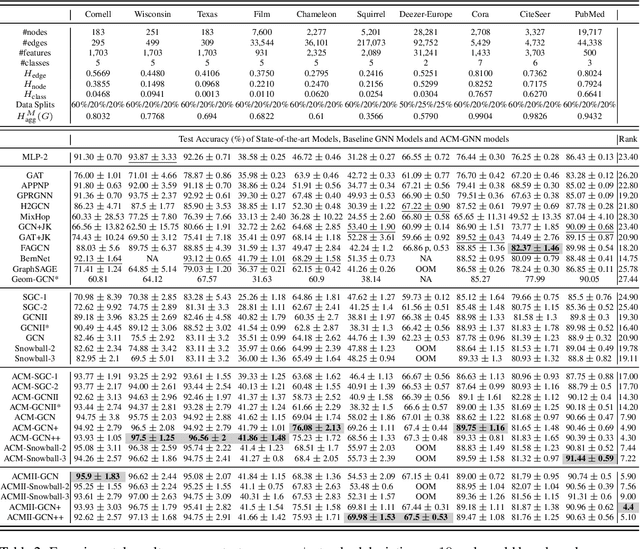
Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by using graph structures based on the relational inductive bias (homophily assumption). While GNNs have been commonly believed to outperform NNs in real-world tasks, recent work has identified a non-trivial set of datasets where their performance compared to NNs is not satisfactory. Heterophily has been considered the main cause of this empirical observation and numerous works have been put forward to address it. In this paper, we first revisit the widely used homophily metrics and point out that their consideration of only graph-label consistency is a shortcoming. Then, we study heterophily from the perspective of post-aggregation node similarity and define new homophily metrics, which are potentially advantageous compared to existing ones. Based on this investigation, we prove that some harmful cases of heterophily can be effectively addressed by local diversification operation. Then, we propose the Adaptive Channel Mixing (ACM), a framework to adaptively exploit aggregation, diversification and identity channels node-wisely to extract richer localized information for diverse node heterophily situations. ACM is more powerful than the commonly used uni-channel framework for node classification tasks on heterophilic graphs and is easy to be implemented in baseline GNN layers. When evaluated on 10 benchmark node classification tasks, ACM-augmented baselines consistently achieve significant performance gain, exceeding state-of-the-art GNNs on most tasks without incurring significant computational burden.