 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimelyGPT: Recurrent Convolutional Transformer for Long Time-series Representation
Paper and Code
Nov 29, 2023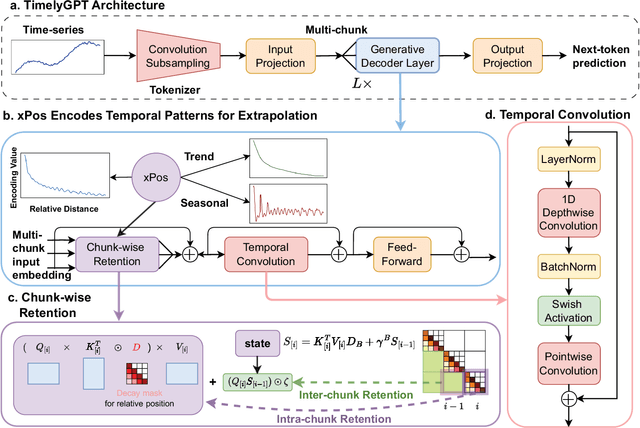

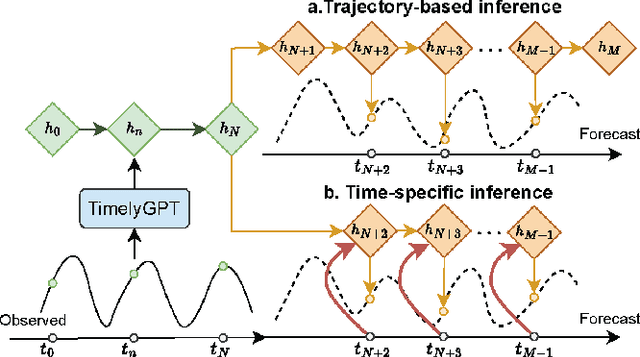

Pre-trained models (PTMs) have gained prominence in Natural Language Processing and Computer Vision domains. When it comes to time-series PTMs, their development has been limited. Previous research on time-series transformers has mainly been devoted to small-scale tasks, yet these models have not consistently outperformed traditional models. Additionally, the performance of these transformers on large-scale data remains unexplored. These findings raise doubts about Transformer's capabilities to scale up and capture temporal dependencies. In this study, we re-examine time-series transformers and identify the shortcomings of prior studies. Drawing from these insights, we then introduce a pioneering architecture called Timely Generative Pre-trained Transformer (\model). This architecture integrates recurrent attention and temporal convolution modules to effectively capture global-local temporal dependencies in long sequences. The relative position embedding with time decay can effectively deal with trend and periodic patterns from time-series. Our experiments show that \model~excels in modeling continuously monitored biosignal as well as irregularly-sampled time-series data commonly observed in longitudinal electronic health records. This breakthrough suggests a priority shift in time-series deep learning research, moving from small-scale modeling from scratch to large-scale pre-training.