 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Evolution of Policy and Internal Reward for Language Agents
Apr 03, 2026Large language model (LLM) agents learn by interacting with environments, but long-horizon training remains fundamentally bottlenecked by sparse and delayed rewards. Existing methods typically address this challenge through post-hoc credit assignment or external reward models, which provide limited guidance at inference time and often separate reward improvement from policy improvement. We propose Self-Guide, a self-generated internal reward for language agents that supports both inference-time guidance and training-time supervision. Specifically, the agent uses Self-Guide as a short self-guidance signal to steer the next action during inference, and converts the same signal into step-level internal reward for denser policy optimization during training. This creates a co-evolving loop: better policy produces better guidance, and better guidance further improves policy as internal reward. Across three agent benchmarks, inference-time self-guidance already yields clear gains, while jointly evolving policy and internal reward with GRPO brings further improvements (8\%) over baselines trained solely with environment reward. Overall, our results suggest that language agents can improve not only by collecting more experience, but also by learning to generate and refine their own internal reward during acting and learning.
PAct: Part-Decomposed Single-View Articulated Object Generation
Feb 16, 2026Articulated objects are central to interactive 3D applications, including embodied AI, robotics, and VR/AR, where functional part decomposition and kinematic motion are essential. Yet producing high-fidelity articulated assets remains difficult to scale because it requires reliable part decomposition and kinematic rigging. Existing approaches largely fall into two paradigms: optimization-based reconstruction or distillation, which can be accurate but often takes tens of minutes to hours per instance, and inference-time methods that rely on template or part retrieval, producing plausible results that may not match the specific structure and appearance in the input observation. We introduce a part-centric generative framework for articulated object creation that synthesizes part geometry, composition, and articulation under explicit part-aware conditioning. Our representation models an object as a set of movable parts, each encoded by latent tokens augmented with part identity and articulation cues. Conditioned on a single image, the model generates articulated 3D assets that preserve instance-level correspondence while maintaining valid part structure and motion. The resulting approach avoids per-instance optimization, enables fast feed-forward inference, and supports controllable assembly and articulation, which are important for embodied interaction. Experiments on common articulated categories (e.g., drawers and doors) show improved input consistency, part accuracy, and articulation plausibility over optimization-based and retrieval-driven baselines, while substantially reducing inference time.
Incorporating Spatial Information into Goal-Conditioned Hierarchical Reinforcement Learning via Graph Representations
Nov 14, 2025



The integration of graphs with Goal-conditioned Hierarchical Reinforcement Learning (GCHRL) has recently gained attention, as intermediate goals (subgoals) can be effectively sampled from graphs that naturally represent the overall task structure in most RL tasks. However, existing approaches typically rely on domain-specific knowledge to construct these graphs, limiting their applicability to new tasks. Other graph-based approaches create graphs dynamically during exploration but struggle to fully utilize them, because they have problems passing the information in the graphs to newly visited states. Additionally, current GCHRL methods face challenges such as sample inefficiency and poor subgoal representation. This paper proposes a solution to these issues by developing a graph encoder-decoder to evaluate unseen states. Our proposed method, Graph-Guided sub-Goal representation Generation RL (G4RL), can be incorporated into any existing GCHRL method when operating in environments with primarily symmetric and reversible transitions to enhance performance across this class of problems. We show that the graph encoder-decoder can be effectively implemented using a network trained on the state graph generated during exploration. Empirical results indicate that leveraging high and low-level intrinsic rewards from the graph encoder-decoder significantly enhances the performance of state-of-the-art GCHRL approaches with an extra small computational cost in dense and sparse reward environments.
SCAR: Shapley Credit Assignment for More Efficient RLHF
May 26, 2025Reinforcement Learning from Human Feedback (RLHF) is a widely used technique for aligning Large Language Models (LLMs) with human preferences, yet it often suffers from sparse reward signals, making effective credit assignment challenging. In typical setups, the reward model provides a single scalar score for an entire generated sequence, offering little insight into which token or span-level decisions were responsible for the outcome. To address this, we propose Shapley Credit Assignment Rewards (SCAR), a novel method that leverages Shapley values in cooperative game theory. SCAR distributes the total sequence-level reward among constituent tokens or text spans based on their principled marginal contributions. This creates dense reward signals, crucially, without necessitating the training of auxiliary critique models or recourse to fine-grained human annotations at intermediate generation stages. Unlike prior dense reward methods, SCAR offers a game-theoretic foundation for fair credit attribution. Theoretically, we demonstrate that SCAR preserves the original optimal policy, and empirically, across diverse tasks including sentiment control, text summarization, and instruction tuning, we show that SCAR converges significantly faster and achieves higher final reward scores compared to standard RLHF and attention-based dense reward baselines. Our findings suggest that SCAR provides a more effective and theoretically sound method for credit assignment in RLHF, leading to more efficient alignment of LLMs.
TCC-Bench: Benchmarking the Traditional Chinese Culture Understanding Capabilities of MLLMs
May 19, 2025



Recent progress in Multimodal Large Language Models (MLLMs) have significantly enhanced the ability of artificial intelligence systems to understand and generate multimodal content. However, these models often exhibit limited effectiveness when applied to non-Western cultural contexts, which raises concerns about their wider applicability. To address this limitation, we propose the Traditional Chinese Culture understanding Benchmark (TCC-Bench), a bilingual (i.e., Chinese and English) Visual Question Answering (VQA) benchmark specifically designed for assessing the understanding of traditional Chinese culture by MLLMs. TCC-Bench comprises culturally rich and visually diverse data, incorporating images from museum artifacts, everyday life scenes, comics, and other culturally significant contexts. We adopt a semi-automated pipeline that utilizes GPT-4o in text-only mode to generate candidate questions, followed by human curation to ensure data quality and avoid potential data leakage. The benchmark also avoids language bias by preventing direct disclosure of cultural concepts within question texts. Experimental evaluations across a wide range of MLLMs demonstrate that current models still face significant challenges when reasoning about culturally grounded visual content. The results highlight the need for further research in developing culturally inclusive and context-aware multimodal systems. The code and data can be found at: https://tcc-bench.github.io/.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Revisiting Heterophily For Graph Neural Networks
Oct 14, 2022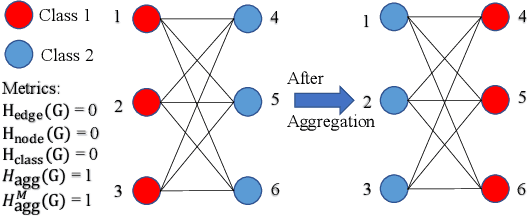
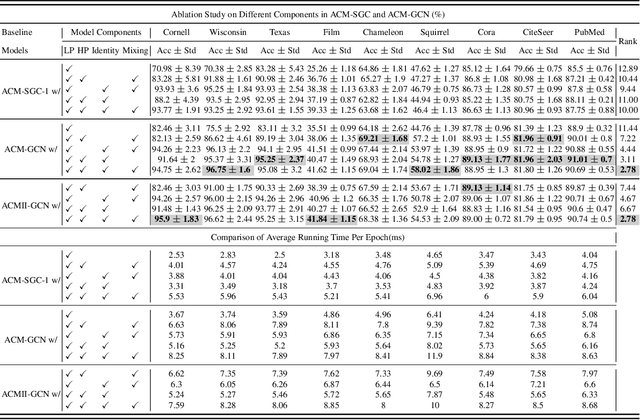
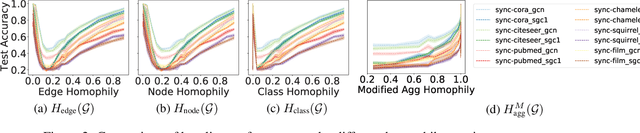
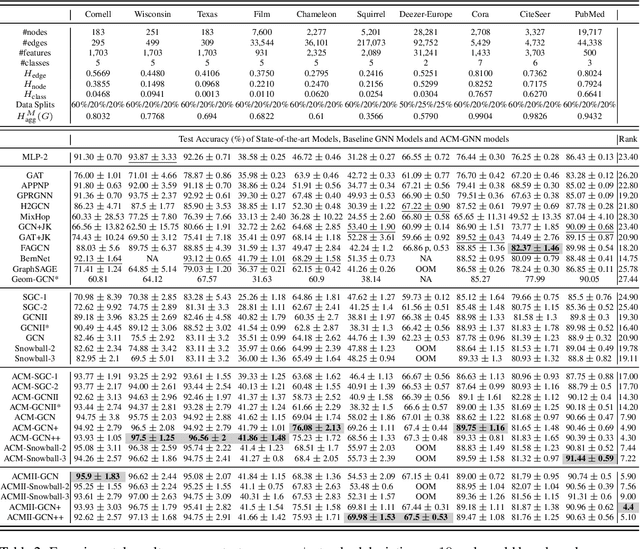
Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by using graph structures based on the relational inductive bias (homophily assumption). While GNNs have been commonly believed to outperform NNs in real-world tasks, recent work has identified a non-trivial set of datasets where their performance compared to NNs is not satisfactory. Heterophily has been considered the main cause of this empirical observation and numerous works have been put forward to address it. In this paper, we first revisit the widely used homophily metrics and point out that their consideration of only graph-label consistency is a shortcoming. Then, we study heterophily from the perspective of post-aggregation node similarity and define new homophily metrics, which are potentially advantageous compared to existing ones. Based on this investigation, we prove that some harmful cases of heterophily can be effectively addressed by local diversification operation. Then, we propose the Adaptive Channel Mixing (ACM), a framework to adaptively exploit aggregation, diversification and identity channels node-wisely to extract richer localized information for diverse node heterophily situations. ACM is more powerful than the commonly used uni-channel framework for node classification tasks on heterophilic graphs and is easy to be implemented in baseline GNN layers. When evaluated on 10 benchmark node classification tasks, ACM-augmented baselines consistently achieve significant performance gain, exceeding state-of-the-art GNNs on most tasks without incurring significant computational burden.
N-Grammer: Augmenting Transformers with latent n-grams
Jul 13, 2022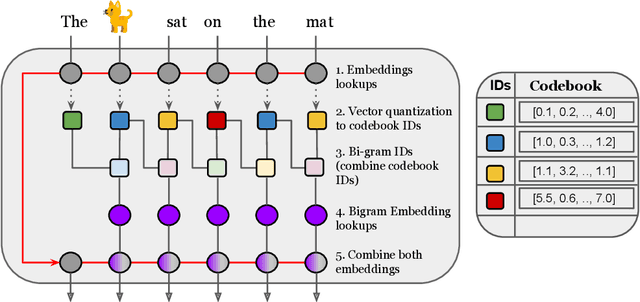
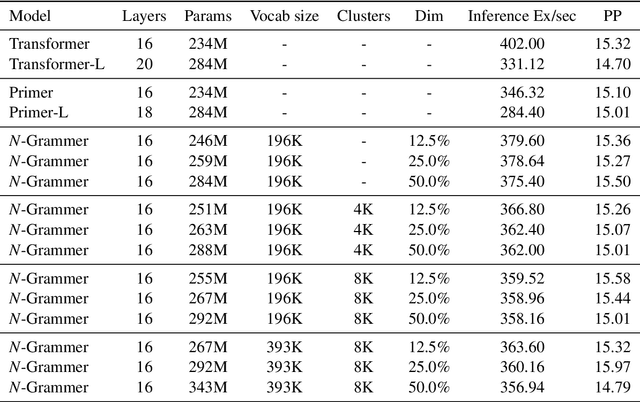

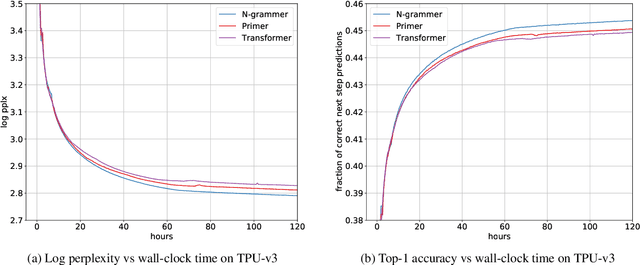
Transformer models have recently emerged as one of the foundational models in natural language processing, and as a byproduct, there is significant recent interest and investment in scaling these models. However, the training and inference costs of these large Transformer language models are prohibitive, thus necessitating more research in identifying more efficient variants. In this work, we propose a simple yet effective modification to the Transformer architecture inspired by the literature in statistical language modeling, by augmenting the model with n-grams that are constructed from a discrete latent representation of the text sequence. We evaluate our model, the N-Grammer on language modeling on the C4 data-set as well as text classification on the SuperGLUE data-set, and find that it outperforms several strong baselines such as the Transformer and the Primer. We open-source our model for reproducibility purposes in Jax.
Is Heterophily A Real Nightmare For Graph Neural Networks To Do Node Classification?
Sep 12, 2021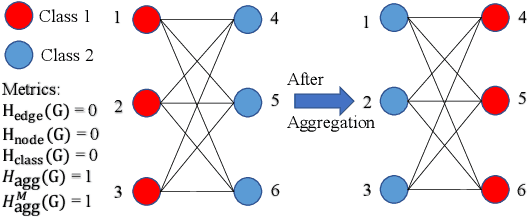
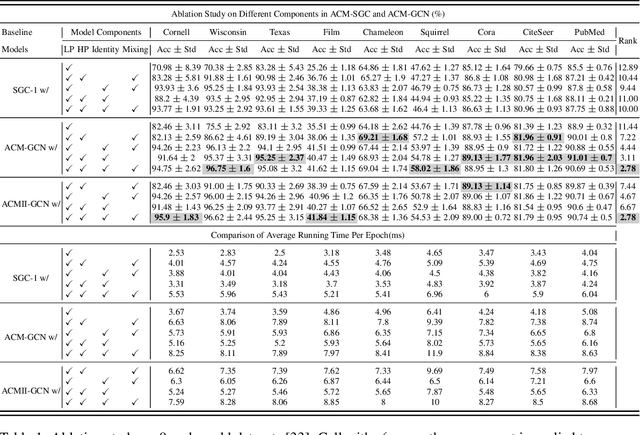
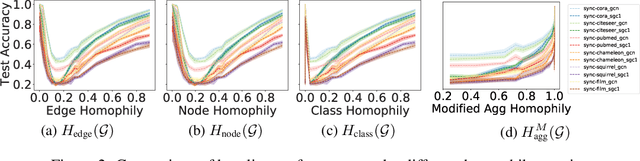
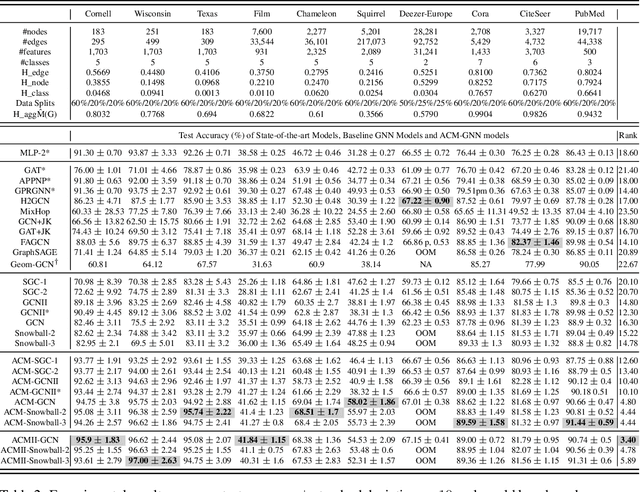
Graph Neural Networks (GNNs) extend basic Neural Networks (NNs) by using the graph structures based on the relational inductive bias (homophily assumption). Though GNNs are believed to outperform NNs in real-world tasks, performance advantages of GNNs over graph-agnostic NNs seem not generally satisfactory. Heterophily has been considered as a main cause and numerous works have been put forward to address it. In this paper, we first show that not all cases of heterophily are harmful for GNNs with aggregation operation. Then, we propose new metrics based on a similarity matrix which considers the influence of both graph structure and input features on GNNs. The metrics demonstrate advantages over the commonly used homophily metrics by tests on synthetic graphs. From the metrics and the observations, we find some cases of harmful heterophily can be addressed by diversification operation. With this fact and knowledge of filterbanks, we propose the Adaptive Channel Mixing (ACM) framework to adaptively exploit aggregation, diversification and identity channels in each GNN layer to address harmful heterophily. We validate the ACM-augmented baselines with 10 real-world node classification tasks. They consistently achieve significant performance gain and exceed the state-of-the-art GNNs on most of the tasks without incurring significant computational burden.