 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Machine Translation Systems for the Next Thousand Languages
May 16, 2022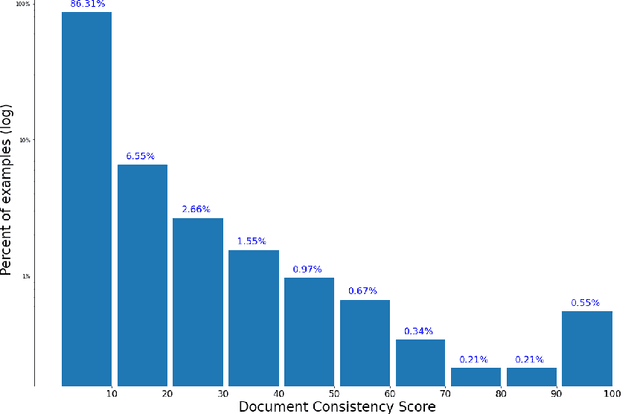

In this paper we share findings from our effort to build practical machine translation (MT) systems capable of translating across over one thousand languages. We describe results in three research domains: (i) Building clean, web-mined datasets for 1500+ languages by leveraging semi-supervised pre-training for language identification and developing data-driven filtering techniques; (ii) Developing practical MT models for under-served languages by leveraging massively multilingual models trained with supervised parallel data for over 100 high-resource languages and monolingual datasets for an additional 1000+ languages; and (iii) Studying the limitations of evaluation metrics for these languages and conducting qualitative analysis of the outputs from our MT models, highlighting several frequent error modes of these types of models. We hope that our work provides useful insights to practitioners working towards building MT systems for currently understudied languages, and highlights research directions that can complement the weaknesses of massively multilingual models in data-sparse settings.
Towards the Next 1000 Languages in Multilingual Machine Translation: Exploring the Synergy Between Supervised and Self-Supervised Learning
Jan 13, 2022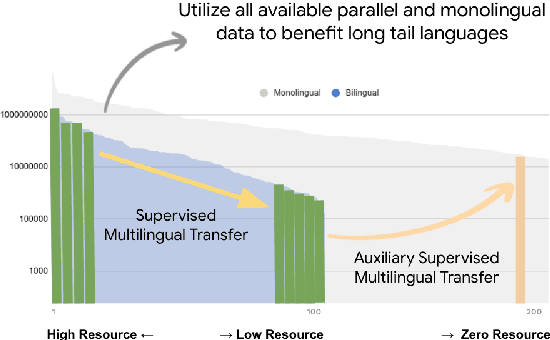
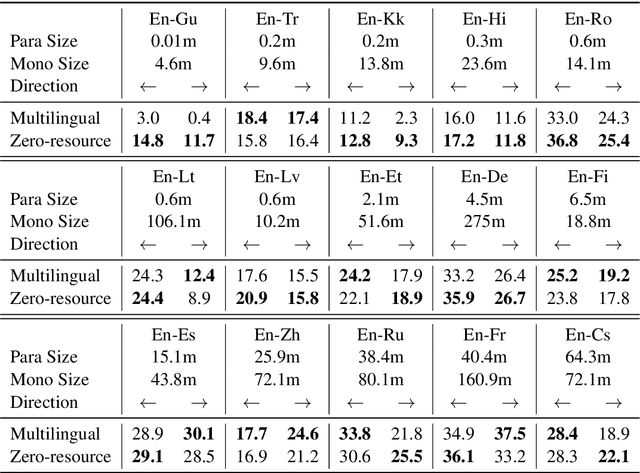

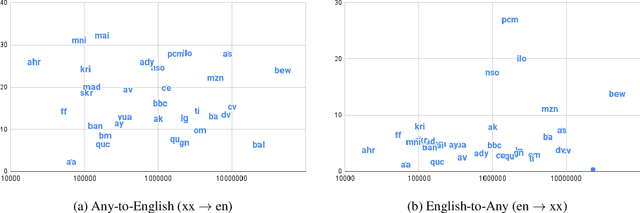
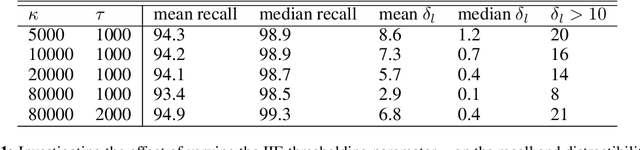
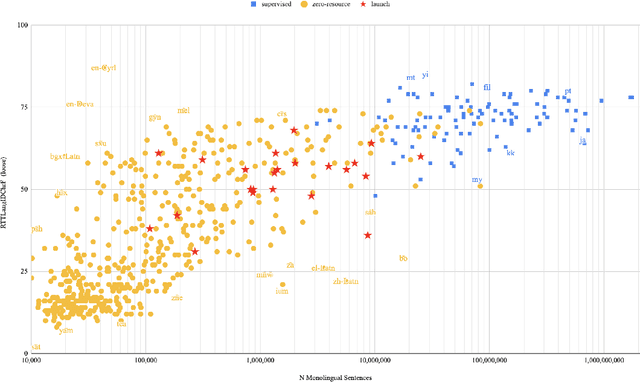
Achieving universal translation between all human language pairs is the holy-grail of machine translation (MT) research. While recent progress in massively multilingual MT is one step closer to reaching this goal, it is becoming evident that extending a multilingual MT system simply by training on more parallel data is unscalable, since the availability of labeled data for low-resource and non-English-centric language pairs is forbiddingly limited. To this end, we present a pragmatic approach towards building a multilingual MT model that covers hundreds of languages, using a mixture of supervised and self-supervised objectives, depending on the data availability for different language pairs. We demonstrate that the synergy between these two training paradigms enables the model to produce high-quality translations in the zero-resource setting, even surpassing supervised translation quality for low- and mid-resource languages. We conduct a wide array of experiments to understand the effect of the degree of multilingual supervision, domain mismatches and amounts of parallel and monolingual data on the quality of our self-supervised multilingual models. To demonstrate the scalability of the approach, we train models with over 200 languages and demonstrate high performance on zero-resource translation on several previously under-studied languages. We hope our findings will serve as a stepping stone towards enabling translation for the next thousand languages.
Rapid Domain Adaptation for Machine Translation with Monolingual Data
Oct 23, 2020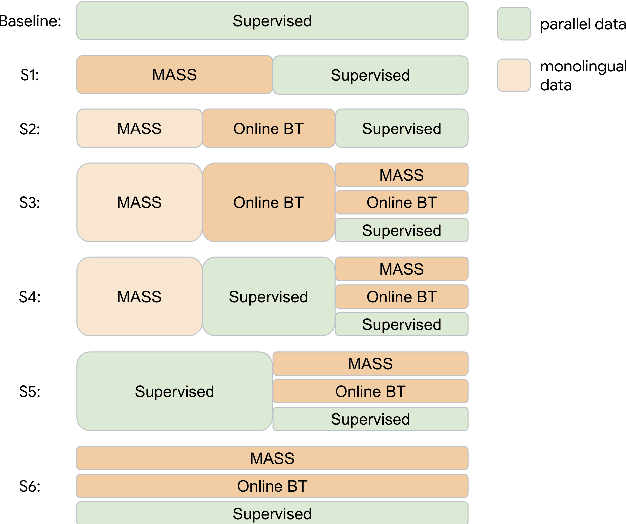



One challenge of machine translation is how to quickly adapt to unseen domains in face of surging events like COVID-19, in which case timely and accurate translation of in-domain information into multiple languages is critical but little parallel data is available yet. In this paper, we propose an approach that enables rapid domain adaptation from the perspective of unsupervised translation. Our proposed approach only requires in-domain monolingual data and can be quickly applied to a preexisting translation system trained on general domain, reaching significant gains on in-domain translation quality with little or no drop on general-domain. We also propose an effective procedure of simultaneous adaptation for multiple domains and languages. To the best of our knowledge, this is the first attempt that aims to address unsupervised multilingual domain adaptation.
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Jul 11, 2019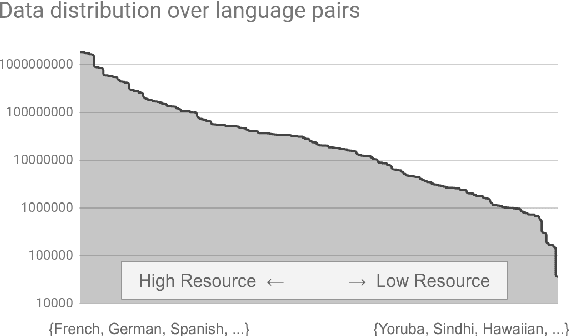

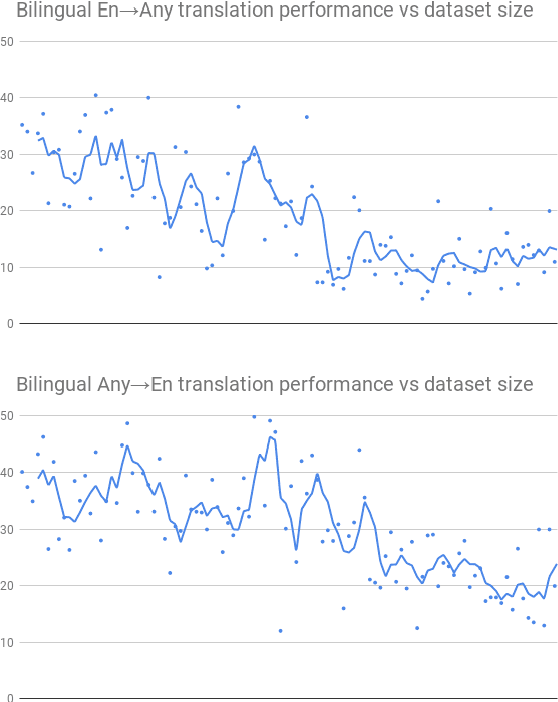

We introduce our efforts towards building a universal neural machine translation (NMT) system capable of translating between any language pair. We set a milestone towards this goal by building a single massively multilingual NMT model handling 103 languages trained on over 25 billion examples. Our system demonstrates effective transfer learning ability, significantly improving translation quality of low-resource languages, while keeping high-resource language translation quality on-par with competitive bilingual baselines. We provide in-depth analysis of various aspects of model building that are crucial to achieving quality and practicality in universal NMT. While we prototype a high-quality universal translation system, our extensive empirical analysis exposes issues that need to be further addressed, and we suggest directions for future research.
Gmail Smart Compose: Real-Time Assisted Writing
May 17, 2019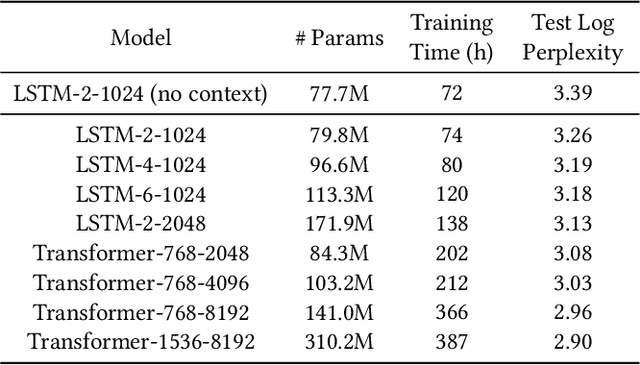
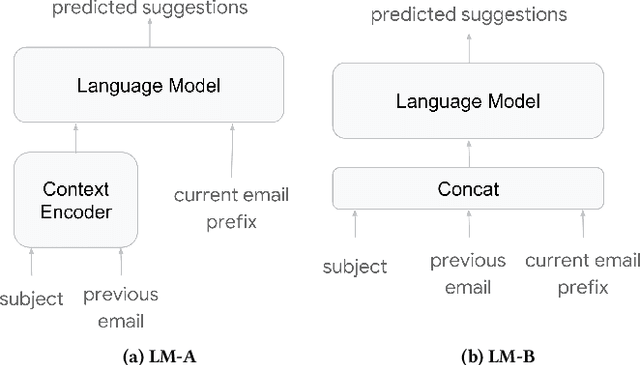
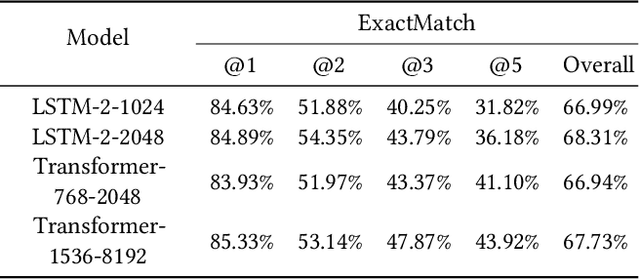
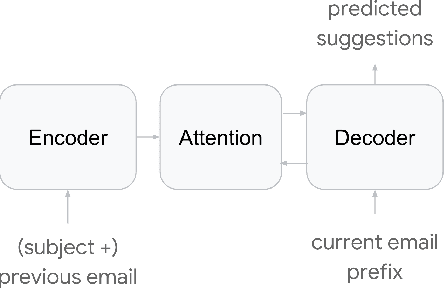
In this paper, we present Smart Compose, a novel system for generating interactive, real-time suggestions in Gmail that assists users in writing mails by reducing repetitive typing. In the design and deployment of such a large-scale and complicated system, we faced several challenges including model selection, performance evaluation, serving and other practical issues. At the core of Smart Compose is a large-scale neural language model. We leveraged state-of-the-art machine learning techniques for language model training which enabled high-quality suggestion prediction, and constructed novel serving infrastructure for high-throughput and real-time inference. Experimental results show the effectiveness of our proposed system design and deployment approach. This system is currently being served in Gmail.
Training Deeper Neural Machine Translation Models with Transparent Attention
Sep 04, 2018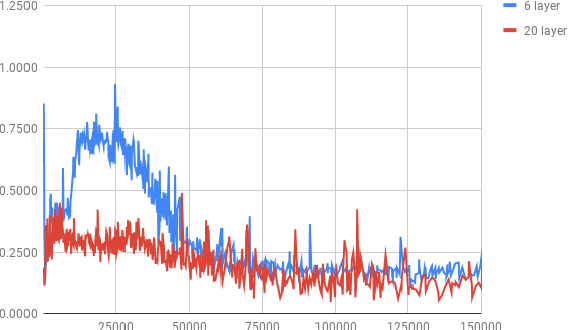
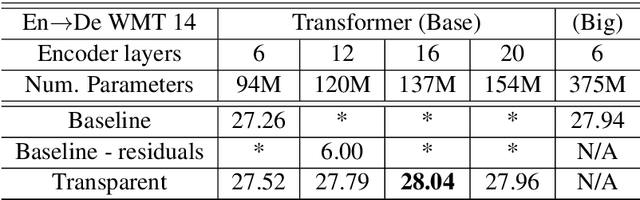


While current state-of-the-art NMT models, such as RNN seq2seq and Transformers, possess a large number of parameters, they are still shallow in comparison to convolutional models used for both text and vision applications. In this work we attempt to train significantly (2-3x) deeper Transformer and Bi-RNN encoders for machine translation. We propose a simple modification to the attention mechanism that eases the optimization of deeper models, and results in consistent gains of 0.7-1.1 BLEU on the benchmark WMT'14 English-German and WMT'15 Czech-English tasks for both architectures.
The Best of Both Worlds: Combining Recent Advances in Neural Machine Translation
Apr 27, 2018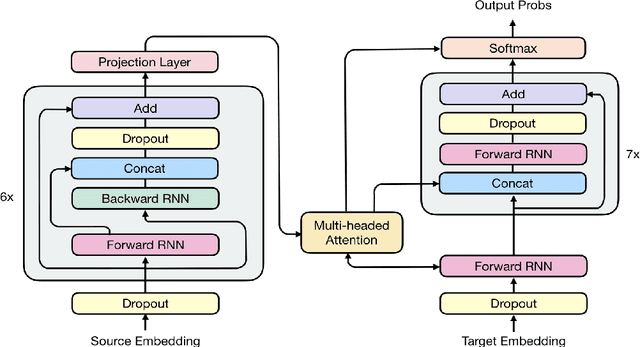
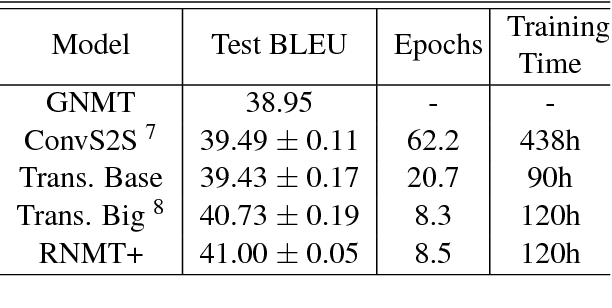
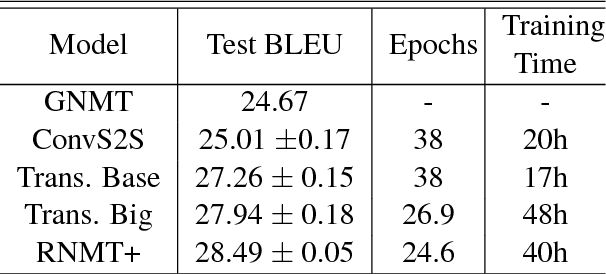
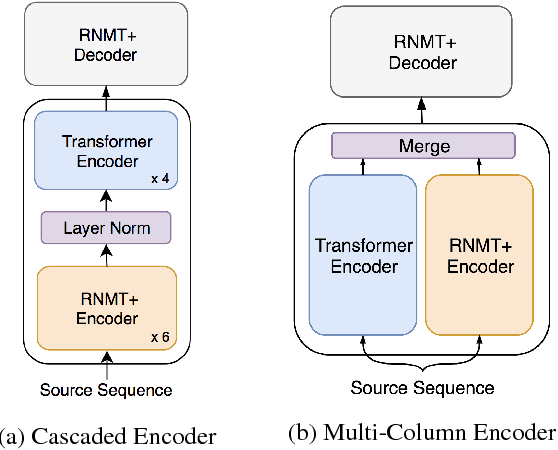
The past year has witnessed rapid advances in sequence-to-sequence (seq2seq) modeling for Machine Translation (MT). The classic RNN-based approaches to MT were first out-performed by the convolutional seq2seq model, which was then out-performed by the more recent Transformer model. Each of these new approaches consists of a fundamental architecture accompanied by a set of modeling and training techniques that are in principle applicable to other seq2seq architectures. In this paper, we tease apart the new architectures and their accompanying techniques in two ways. First, we identify several key modeling and training techniques, and apply them to the RNN architecture, yielding a new RNMT+ model that outperforms all of the three fundamental architectures on the benchmark WMT'14 English to French and English to German tasks. Second, we analyze the properties of each fundamental seq2seq architecture and devise new hybrid architectures intended to combine their strengths. Our hybrid models obtain further improvements, outperforming the RNMT+ model on both benchmark datasets.