 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Effective Sequence-to-Sequence Dialogue State Tracking
Sep 08, 2021
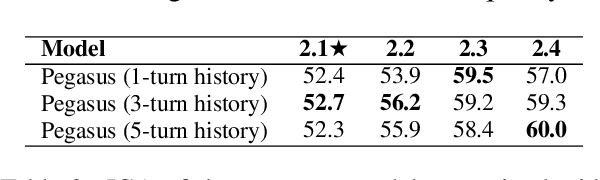
Sequence-to-sequence models have been applied to a wide variety of NLP tasks, but how to properly use them for dialogue state tracking has not been systematically investigated. In this paper, we study this problem from the perspectives of pre-training objectives as well as the formats of context representations. We demonstrate that the choice of pre-training objective makes a significant difference to the state tracking quality. In particular, we find that masked span prediction is more effective than auto-regressive language modeling. We also explore using Pegasus, a span prediction-based pre-training objective for text summarization, for the state tracking model. We found that pre-training for the seemingly distant summarization task works surprisingly well for dialogue state tracking. In addition, we found that while recurrent state context representation works also reasonably well, the model may have a hard time recovering from earlier mistakes. We conducted experiments on the MultiWOZ 2.1-2.4, WOZ 2.0, and DSTC2 datasets with consistent observations.
Improving Longer-range Dialogue State Tracking
Feb 27, 2021
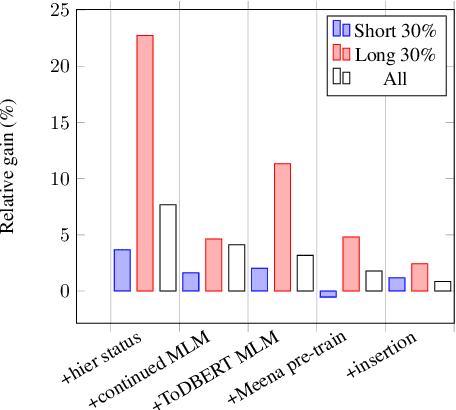


Dialogue state tracking (DST) is a pivotal component in task-oriented dialogue systems. While it is relatively easy for a DST model to capture belief states in short conversations, the task of DST becomes more challenging as the length of a dialogue increases due to the injection of more distracting contexts. In this paper, we aim to improve the overall performance of DST with a special focus on handling longer dialogues. We tackle this problem from three perspectives: 1) A model designed to enable hierarchical slot status prediction; 2) Balanced training procedure for generic and task-specific language understanding; 3) Data perturbation which enhances the model's ability in handling longer conversations. We conduct experiments on the MultiWOZ benchmark, and demonstrate the effectiveness of each component via a set of ablation tests, especially on longer conversations.
Rapid Domain Adaptation for Machine Translation with Monolingual Data
Oct 23, 2020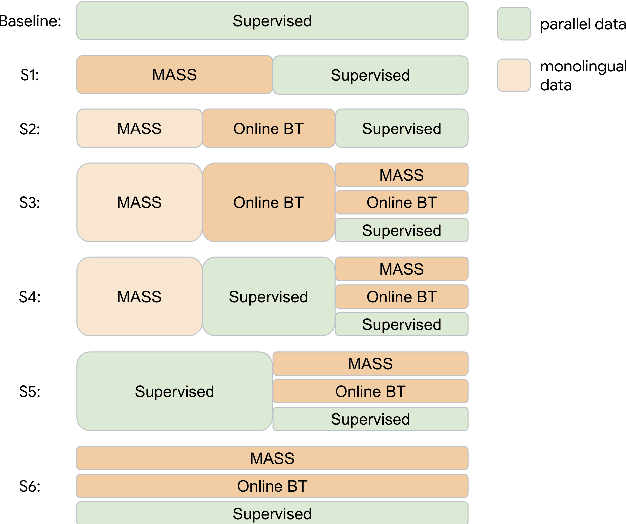



One challenge of machine translation is how to quickly adapt to unseen domains in face of surging events like COVID-19, in which case timely and accurate translation of in-domain information into multiple languages is critical but little parallel data is available yet. In this paper, we propose an approach that enables rapid domain adaptation from the perspective of unsupervised translation. Our proposed approach only requires in-domain monolingual data and can be quickly applied to a preexisting translation system trained on general domain, reaching significant gains on in-domain translation quality with little or no drop on general-domain. We also propose an effective procedure of simultaneous adaptation for multiple domains and languages. To the best of our knowledge, this is the first attempt that aims to address unsupervised multilingual domain adaptation.