Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Consciousness-Inspired Planning Agent for Model-Based Reinforcement Learning
Paper and Code
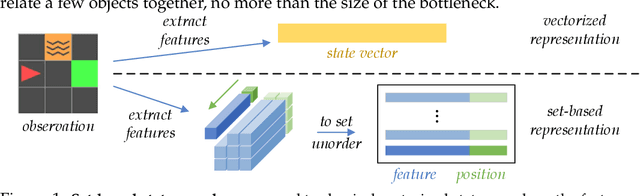
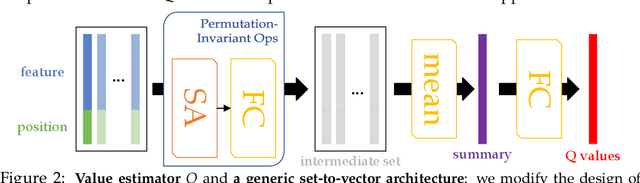
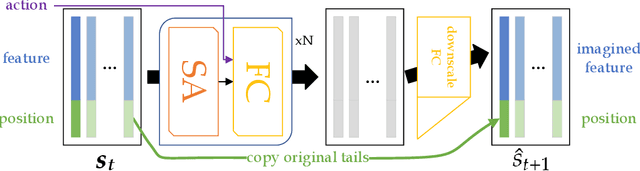
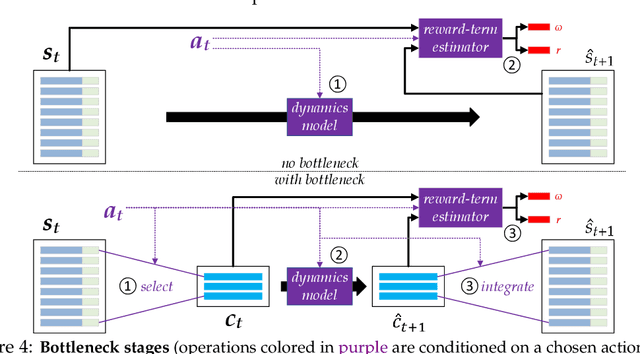
We present an end-to-end, model-based deep reinforcement learning agent which dynamically attends to relevant parts of its state, in order to plan and to generalize better out-of-distribution. The agent's architecture uses a set representation and a bottleneck mechanism, forcing the number of entities to which the agent attends at each planning step to be small. In experiments with customized MiniGrid environments with different dynamics, we observe that the design allows agents to learn to plan effectively, by attending to the relevant objects, leading to better out-of-distribution generalization.
View paper on
 OpenReview
OpenReview