 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Abstractions-Augmented Temporally Contrastive Learning: An Alternative to the Laplacian in RL
Paper and Code
Mar 21, 2022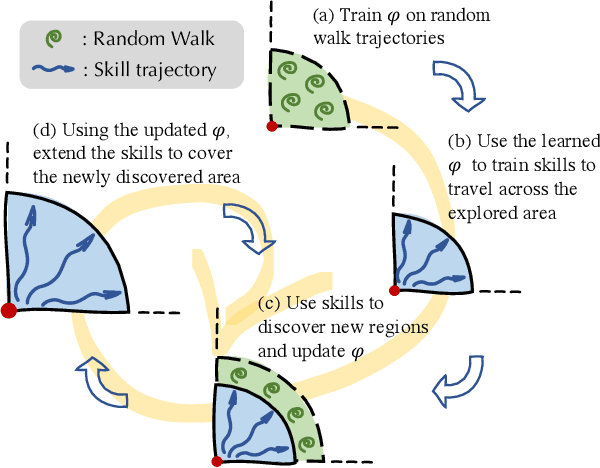
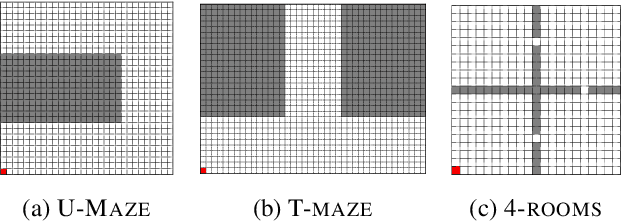

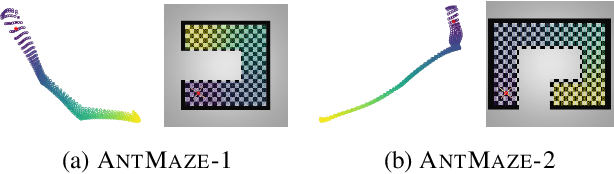
In reinforcement learning, the graph Laplacian has proved to be a valuable tool in the task-agnostic setting, with applications ranging from skill discovery to reward shaping. Recently, learning the Laplacian representation has been framed as the optimization of a temporally-contrastive objective to overcome its computational limitations in large (or continuous) state spaces. However, this approach requires uniform access to all states in the state space, overlooking the exploration problem that emerges during the representation learning process. In this work, we propose an alternative method that is able to recover, in a non-uniform-prior setting, the expressiveness and the desired properties of the Laplacian representation. We do so by combining the representation learning with a skill-based covering policy, which provides a better training distribution to extend and refine the representation. We also show that a simple augmentation of the representation objective with the learned temporal abstractions improves dynamics-awareness and helps exploration. We find that our method succeeds as an alternative to the Laplacian in the non-uniform setting and scales to challenging continuous control environments. Finally, even if our method is not optimized for skill discovery, the learned skills can successfully solve difficult continuous navigation tasks with sparse rewards, where standard skill discovery approaches are no so effective.