 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tradeoff Between Privacy and Accuracy in Anomaly Detection Using Federated XGBoost
Paper and Code
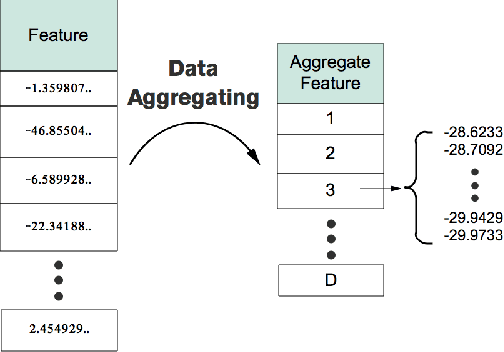

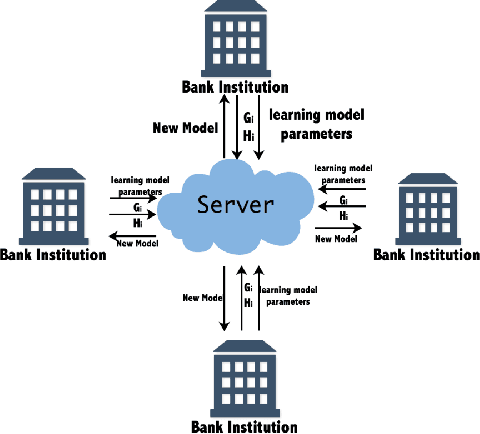
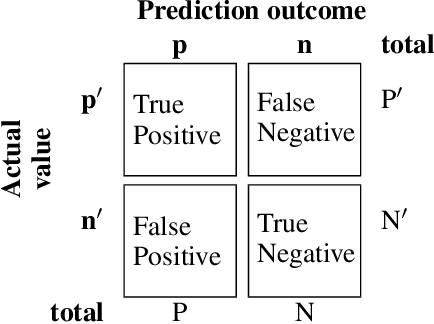
Privacy has raised considerable concerns recently, especially with the advent of information explosion and numerous data mining techniques to explore the information inside large volumes of data. In this context, a new distributed learning paradigm termed federated learning becomes prominent recently to tackle the privacy issues in distributed learning, where only learning models will be transmitted from the distributed nodes to servers without revealing users' own data and hence protecting the privacy of users. In this paper, we propose a horizontal federated XGBoost algorithm to solve the federated anomaly detection problem, where the anomaly detection aims to identify abnormalities from extremely unbalanced datasets and can be considered as a special classification problem. Our proposed federated XGBoost algorithm incorporates data aggregation and sparse federated update processes to balance the tradeoff between privacy and learning performance. In particular, we introduce the virtual data sample by aggregating a group of users' data together at a single distributed node. We compute parameters based on these virtual data samples in the local nodes and aggregate the learning model in the central server. In the learning model upgrading process, we focus more on the wrongly classified data before in the virtual sample and hence to generate sparse learning model parameters. By carefully controlling the size of these groups of samples, we can achieve a tradeoff between privacy and learning performance. Our experimental results show the effectiveness of our proposed scheme by comparing with existing state-of-the-arts.