 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedQV: Leveraging Quadratic Voting in Federated Learning
Jan 02, 2024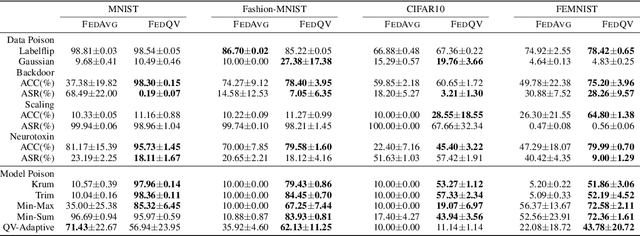
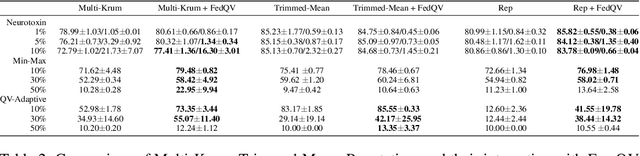
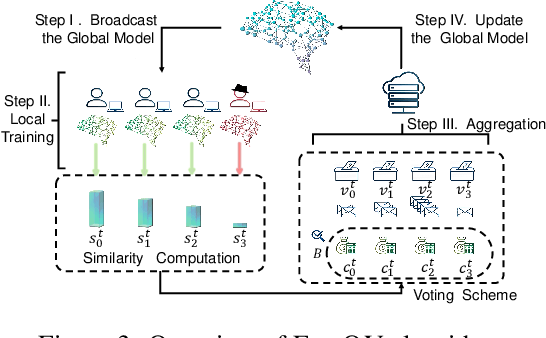
Federated Learning (FL) permits different parties to collaboratively train a global model without disclosing their respective local labels. A crucial step of FL, that of aggregating local models to produce the global one, shares many similarities with public decision-making, and elections in particular. In that context, a major weakness of FL, namely its vulnerability to poisoning attacks, can be interpreted as a consequence of the one person one vote (henceforth 1p1v) principle underpinning most contemporary aggregation rules. In this paper, we propose FedQV, a novel aggregation algorithm built upon the quadratic voting scheme, recently proposed as a better alternative to 1p1v-based elections. Our theoretical analysis establishes that FedQV is a truthful mechanism in which bidding according to one's true valuation is a dominant strategy that achieves a convergence rate that matches those of state-of-the-art methods. Furthermore, our empirical analysis using multiple real-world datasets validates the superior performance of FedQV against poisoning attacks. It also shows that combining FedQV with unequal voting ``budgets'' according to a reputation score increases its performance benefits even further. Finally, we show that FedQV can be easily combined with Byzantine-robust privacy-preserving mechanisms to enhance its robustness against both poisoning and privacy attacks.
PriPrune: Quantifying and Preserving Privacy in Pruned Federated Learning
Oct 30, 2023



Federated learning (FL) is a paradigm that allows several client devices and a server to collaboratively train a global model, by exchanging only model updates, without the devices sharing their local training data. These devices are often constrained in terms of communication and computation resources, and can further benefit from model pruning -- a paradigm that is widely used to reduce the size and complexity of models. Intuitively, by making local models coarser, pruning is expected to also provide some protection against privacy attacks in the context of FL. However this protection has not been previously characterized, formally or experimentally, and it is unclear if it is sufficient against state-of-the-art attacks. In this paper, we perform the first investigation of privacy guarantees for model pruning in FL. We derive information-theoretic upper bounds on the amount of information leaked by pruned FL models. We complement and validate these theoretical findings, with comprehensive experiments that involve state-of-the-art privacy attacks, on several state-of-the-art FL pruning schemes, using benchmark datasets. This evaluation provides valuable insights into the choices and parameters that can affect the privacy protection provided by pruning. Based on these insights, we introduce PriPrune -- a privacy-aware algorithm for local model pruning, which uses a personalized per-client defense mask and adapts the defense pruning rate so as to jointly optimize privacy and model performance. PriPrune is universal in that can be applied after any pruned FL scheme on the client, without modification, and protects against any inversion attack by the server. Our empirical evaluation demonstrates that PriPrune significantly improves the privacy-accuracy tradeoff compared to state-of-the-art pruned FL schemes that do not take privacy into account.