 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Prediction Framework for Signal Maps
Feb 12, 2022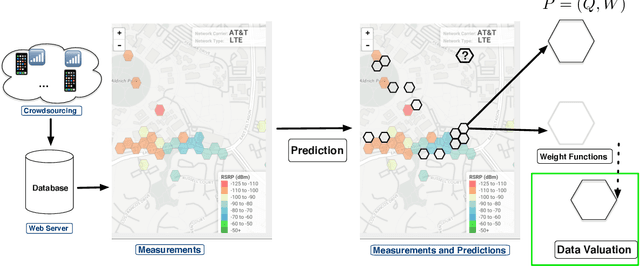
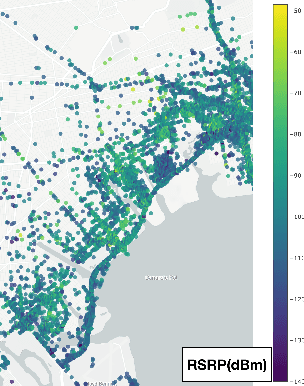
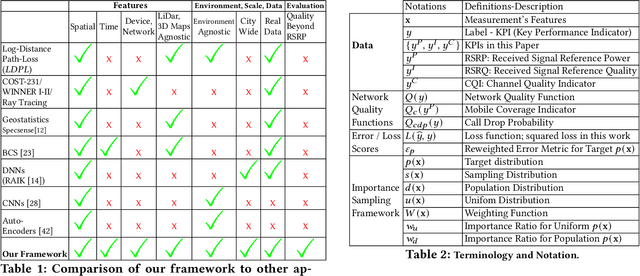

Signal maps are essential for the planning and operation of cellular networks. However, the measurements needed to create such maps are expensive, often biased, not always reflecting the metrics of interest, and posing privacy risks. In this paper, we develop a unified framework for predicting cellular signal maps from limited measurements. Our framework builds on a state-of-the-art random-forest predictor, or any other base predictor. We propose and combine three mechanisms that deal with the fact that not all measurements are equally important for a particular prediction task. First, we design quality-of-service functions ($Q$), including signal strength (RSRP) but also other metrics of interest to operators, i.e., coverage and call drop probability. By implicitly altering the loss function employed in learning, quality functions can also improve prediction for RSRP itself where it matters (e.g., MSE reduction up to 27% in the low signal strength regime, where errors are critical). Second, we introduce weight functions ($W$) to specify the relative importance of prediction at different locations and other parts of the feature space. We propose re-weighting based on importance sampling to obtain unbiased estimators when the sampling and target distributions are different. This yields improvements up to 20% for targets based on spatially uniform loss or losses based on user population density. Third, we apply the Data Shapley framework for the first time in this context: to assign values ($\phi$) to individual measurement points, which capture the importance of their contribution to the prediction task. This improves prediction (e.g., from 64% to 94% in recall for coverage loss) by removing points with negative values, and can also enable data minimization. We evaluate our methods and demonstrate significant improvement in prediction performance, using several real-world datasets.
Location Leakage in Federated Signal Maps
Dec 07, 2021

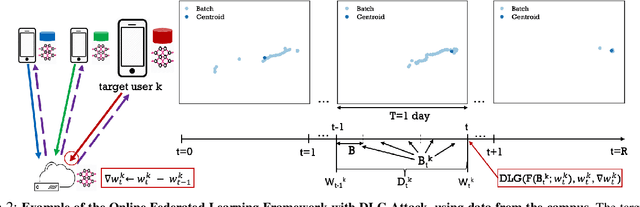

We consider the problem of predicting cellular network performance (signal maps) from measurements collected by several mobile devices. We formulate the problem within the online federated learning framework: (i) federated learning (FL) enables users to collaboratively train a model, while keeping their training data on their devices; (ii) measurements are collected as users move around over time and are used for local training in an online fashion. We consider an honest-but-curious server, who observes the updates from target users participating in FL and infers their location using a deep leakage from gradients (DLG) type of attack, originally developed to reconstruct training data of DNN image classifiers. We make the key observation that a DLG attack, applied to our setting, infers the average location of a batch of local data, and can thus be used to reconstruct the target users' trajectory at a coarse granularity. We show that a moderate level of privacy protection is already offered by the averaging of gradients, which is inherent to Federated Averaging. Furthermore, we propose an algorithm that devices can apply locally to curate the batches used for local updates, so as to effectively protect their location privacy without hurting utility. Finally, we show that the effect of multiple users participating in FL depends on the similarity of their trajectories. To the best of our knowledge, this is the first study of DLG attacks in the setting of FL from crowdsourced spatio-temporal data.
A Federated Learning Approach for Mobile Packet Classification
Jul 30, 2019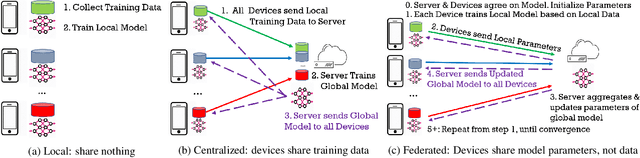



In order to improve mobile data transparency, a number of network-based approaches have been proposed to inspect packets generated by mobile devices and detect personally identifiable information (PII), ad requests, or other activities. State-of-the-art approaches train classifiers based on features extracted from HTTP packets. So far, these classifiers have only been trained in a centralized way, where mobile users label and upload their packet logs to a central server, which then trains a global classifier and shares it with the users to apply on their devices. However, packet logs used as training data may contain sensitive information that users may not want to share/upload. In this paper, we apply, for the first time, a Federated Learning approach to mobile packet classification, which allows mobile devices to collaborate and train a global model, without sharing raw training data. Methodological challenges we address in this context include: model and feature selection, and tuning the Federated Learning parameters. We apply our framework to two different packet classification tasks (i.e., to predict PII exposure or ad requests in HTTP packets) and we demonstrate its effectiveness in terms of classification performance, communication and computation cost, using three real-world datasets.