 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoGEM: Training-free Action Grounding in Videos
Mar 26, 2025Vision-language foundation models have shown impressive capabilities across various zero-shot tasks, including training-free localization and grounding, primarily focusing on localizing objects in images. However, leveraging those capabilities to localize actions and events in videos is challenging, as actions have less physical outline and are usually described by higher-level concepts. In this work, we propose VideoGEM, the first training-free spatial action grounding method based on pretrained image- and video-language backbones. Namely, we adapt the self-self attention formulation of GEM to spatial activity grounding. We observe that high-level semantic concepts, such as actions, usually emerge in the higher layers of the image- and video-language models. We, therefore, propose a layer weighting in the self-attention path to prioritize higher layers. Additionally, we introduce a dynamic weighting method to automatically tune layer weights to capture each layer`s relevance to a specific prompt. Finally, we introduce a prompt decomposition, processing action, verb, and object prompts separately, resulting in a better spatial localization of actions. We evaluate the proposed approach on three image- and video-language backbones, CLIP, OpenCLIP, and ViCLIP, and on four video grounding datasets, V-HICO, DALY, YouCook-Interactions, and GroundingYouTube, showing that the proposed training-free approach is able to outperform current trained state-of-the-art approaches for spatial video grounding.
VL-Taboo: An Analysis of Attribute-based Zero-shot Capabilities of Vision-Language Models
Sep 12, 2022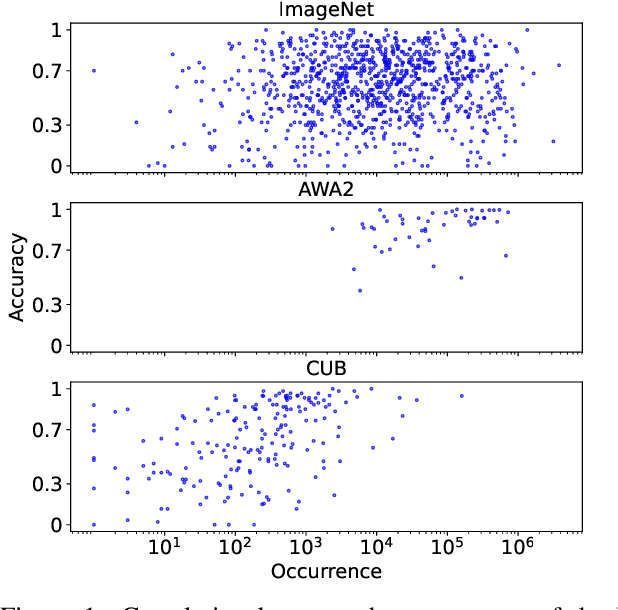
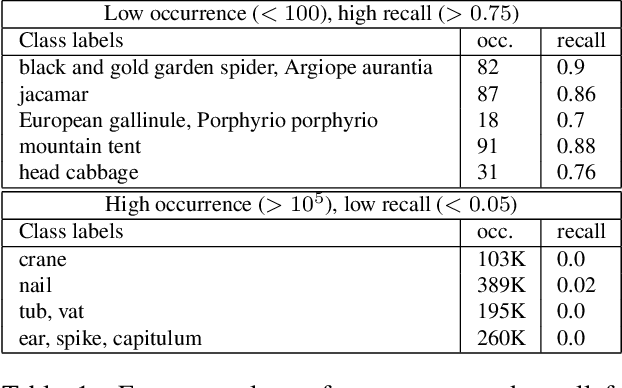

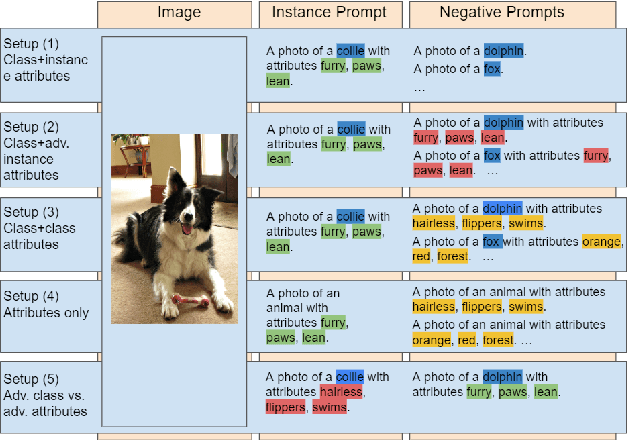
Vision-language models trained on large, randomly collected data had significant impact in many areas since they appeared. But as they show great performance in various fields, such as image-text-retrieval, their inner workings are still not fully understood. The current work analyses the true zero-shot capabilities of those models. We start from the analysis of the training corpus assessing to what extent (and which of) the test classes are really zero-shot and how this correlates with individual classes performance. We follow up with the analysis of the attribute-based zero-shot learning capabilities of these models, evaluating how well this classical zero-shot notion emerges from large-scale webly supervision. We leverage the recently released LAION400M data corpus as well as the publicly available pretrained models of CLIP, OpenCLIP, and FLAVA, evaluating the attribute-based zero-shot capabilities on CUB and AWA2 benchmarks. Our analysis shows that: (i) most of the classes in popular zero-shot benchmarks are observed (a lot) during pre-training; (ii) zero-shot performance mainly comes out of models' capability of recognizing class labels, whenever they are present in the text, and a significantly lower performing capability of attribute-based zeroshot learning is only observed when class labels are not used; (iii) the number of the attributes used can have a significant effect on performance, and can easily cause a significant performance decrease.