 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack Box Variational Inference with a Deterministic Objective: Faster, More Accurate, and Even More Black Box
Apr 11, 2023



Automatic differentiation variational inference (ADVI) offers fast and easy-to-use posterior approximation in multiple modern probabilistic programming languages. However, its stochastic optimizer lacks clear convergence criteria and requires tuning parameters. Moreover, ADVI inherits the poor posterior uncertainty estimates of mean-field variational Bayes (MFVB). We introduce ``deterministic ADVI'' (DADVI) to address these issues. DADVI replaces the intractable MFVB objective with a fixed Monte Carlo approximation, a technique known in the stochastic optimization literature as the ``sample average approximation'' (SAA). By optimizing an approximate but deterministic objective, DADVI can use off-the-shelf second-order optimization, and, unlike standard mean-field ADVI, is amenable to more accurate posterior linear response (LR) covariance estimates. In contrast to existing worst-case theory, we show that, on certain classes of common statistical problems, DADVI and the SAA can perform well with relatively few samples even in very high dimensions, though we also show that such favorable results cannot extend to variational approximations that are too expressive relative to mean-field ADVI. We show on a variety of real-world problems that DADVI reliably finds good solutions with default settings (unlike ADVI) and, together with LR covariances, is typically faster and more accurate than standard ADVI.
Scaling multi-species occupancy models to large citizen science datasets
Jun 17, 2022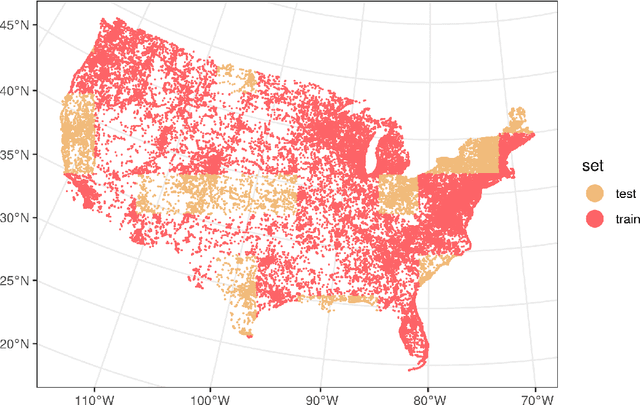
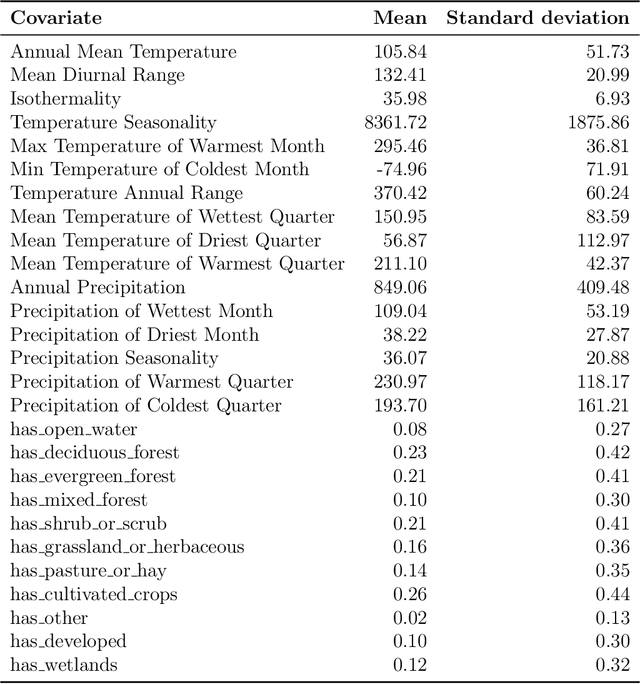
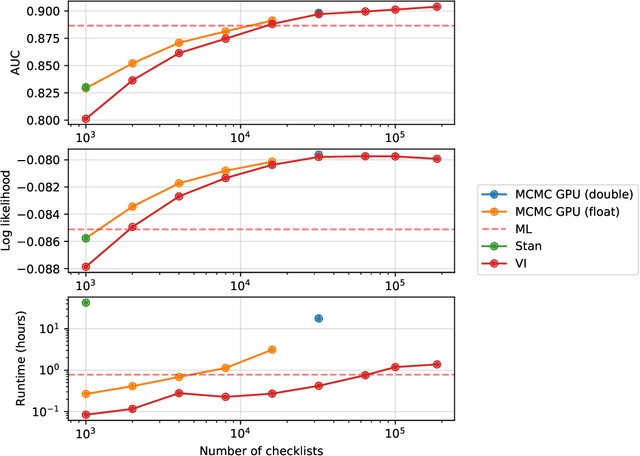

Citizen science datasets can be very large and promise to improve species distribution modelling, but detection is imperfect, risking bias when fitting models. In particular, observers may not detect species that are actually present. Occupancy models can estimate and correct for this observation process, and multi-species occupancy models exploit similarities in the observation process, which can improve estimates for rare species. However, the computational methods currently used to fit these models do not scale to large datasets. We develop approximate Bayesian inference methods and use graphics processing units (GPUs) to scale multi-species occupancy models to very large citizen science data. We fit multi-species occupancy models to one month of data from the eBird project consisting of 186,811 checklist records comprising 430 bird species. We evaluate the predictions on a spatially separated test set of 59,338 records, comparing two different inference methods -- Markov chain Monte Carlo (MCMC) and variational inference (VI) -- to occupancy models fitted to each species separately using maximum likelihood. We fitted models to the entire dataset using VI, and up to 32,000 records with MCMC. VI fitted to the entire dataset performed best, outperforming single-species models on both AUC (90.4% compared to 88.7%) and on log likelihood (-0.080 compared to -0.085). We also evaluate how well range maps predicted by the model agree with expert maps. We find that modelling the detection process greatly improves agreement and that the resulting maps agree as closely with expert maps as ones estimated using high quality survey data. Our results demonstrate that multi-species occupancy models are a compelling approach to model large citizen science datasets, and that, once the observation process is taken into account, they can model species distributions accurately.
Gaussian Process Priors for Dynamic Paired Comparison Modelling
Feb 20, 2019
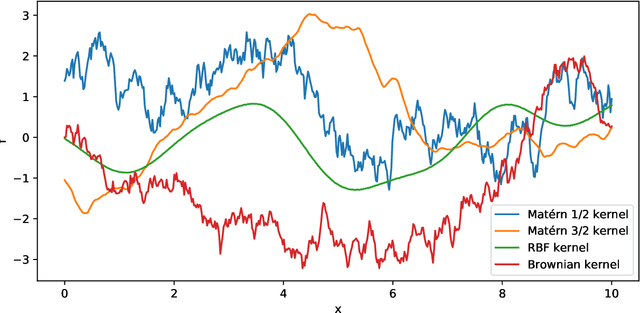
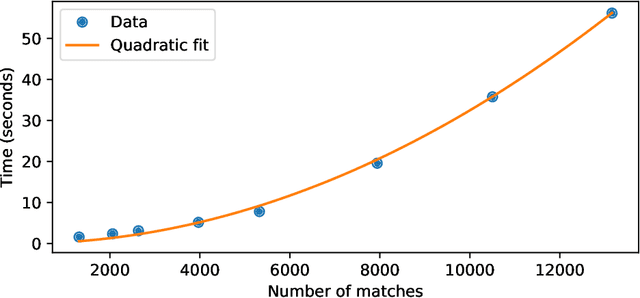
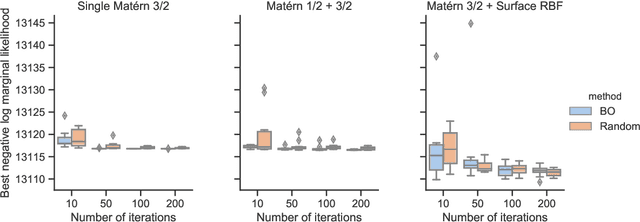
Dynamic paired comparison models, such as Elo and Glicko, are frequently used for sports prediction and ranking players or teams. We present an alternative dynamic paired comparison model which uses a Gaussian Process (GP) as a prior for the time dynamics rather than the Markovian dynamics usually assumed. In addition, we show that the GP model can easily incorporate covariates. We derive an efficient approximate Bayesian inference procedure based on the Laplace Approximation and sparse linear algebra. We select hyperparameters by maximising their marginal likelihood using Bayesian Optimisation, comparing the results against random search. Finally, we fit and evaluate the model on the 2018 season of ATP tennis matches, where it performs competitively, outperforming Elo and Glicko on log loss, particularly when surface covariates are included.