 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI call BS: Fraud Detection in Crowdfunding Campaigns
Jun 30, 2020
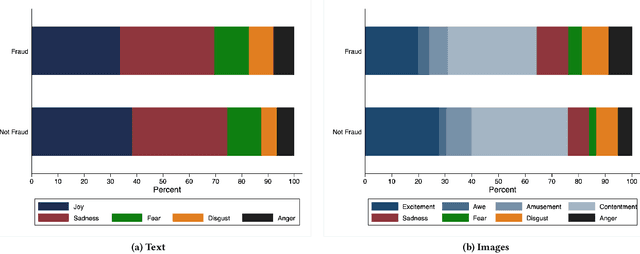

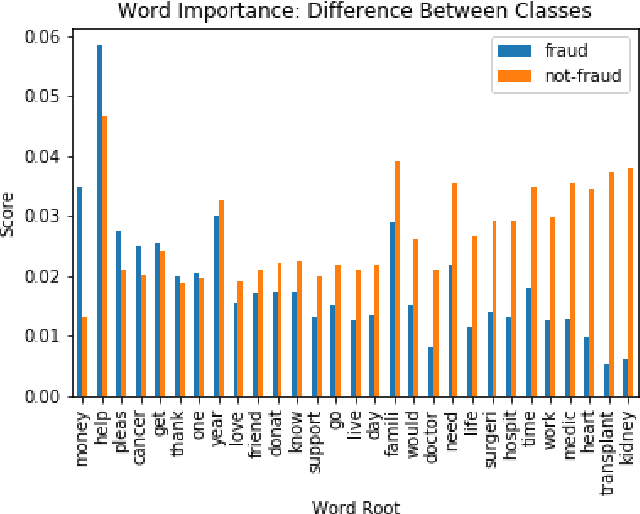
Donations to charity-based crowdfunding environments have been on the rise in the last few years. Unsurprisingly, deception and fraud in such platforms have also increased, but have not been thoroughly studied to understand what characteristics can expose such behavior and allow its automatic detection and blocking. Indeed, crowdfunding platforms are the only ones typically performing oversight for the campaigns launched in each service. However, they are not properly incentivized to combat fraud among users and the campaigns they launch: on the one hand, a platform's revenue is directly proportional to the number of transactions performed (since the platform charges a fixed amount per donation); on the other hand, if a platform is transparent with respect to how much fraud it has, it may discourage potential donors from participating. In this paper, we take the first step in studying fraud in crowdfunding campaigns. We analyze data collected from different crowdfunding platforms, and annotate 700 campaigns as fraud or not. We compute various textual and image-based features and study their distributions and how they associate with campaign fraud. Using these attributes, we build machine learning classifiers, and show that it is possible to automatically classify such fraudulent behavior with up to 90.14% accuracy and 96.01% AUC, only using features available from the campaign's description at the moment of publication (i.e., with no user or money activity), making our method applicable for real-time operation on a user browser.
You are your Metadata: Identification and Obfuscation of Social Media Users using Metadata Information
May 14, 2018
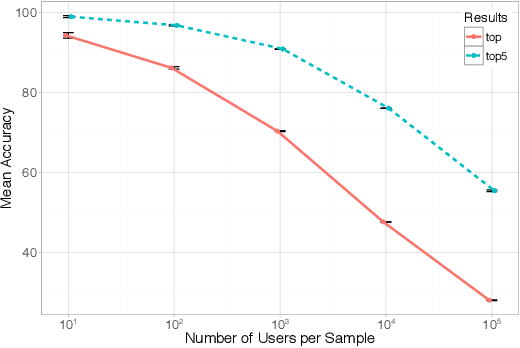

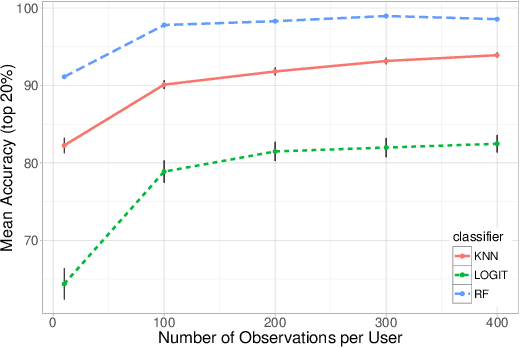
Metadata are associated to most of the information we produce in our daily interactions and communication in the digital world. Yet, surprisingly, metadata are often still catergorized as non-sensitive. Indeed, in the past, researchers and practitioners have mainly focused on the problem of the identification of a user from the content of a message. In this paper, we use Twitter as a case study to quantify the uniqueness of the association between metadata and user identity and to understand the effectiveness of potential obfuscation strategies. More specifically, we analyze atomic fields in the metadata and systematically combine them in an effort to classify new tweets as belonging to an account using different machine learning algorithms of increasing complexity. We demonstrate that through the application of a supervised learning algorithm, we are able to identify any user in a group of 10,000 with approximately 96.7% accuracy. Moreover, if we broaden the scope of our search and consider the 10 most likely candidates we increase the accuracy of the model to 99.22%. We also found that data obfuscation is hard and ineffective for this type of data: even after perturbing 60% of the training data, it is still possible to classify users with an accuracy higher than 95%. These results have strong implications in terms of the design of metadata obfuscation strategies, for example for data set release, not only for Twitter, but, more generally, for most social media platforms.