 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Reweighting: On the Predictive Role of Covariate Shift in Effect Generalization
Dec 12, 2024Many existing approaches to generalizing statistical inference amidst distribution shift operate under the covariate shift assumption, which posits that the conditional distribution of unobserved variables given observable ones is invariant across populations. However, recent empirical investigations have demonstrated that adjusting for shift in observed variables (covariate shift) is often insufficient for generalization. In other words, covariate shift does not typically ``explain away'' the distribution shift between settings. As such, addressing the unknown yet non-negligible shift in the unobserved variables given observed ones (conditional shift) is crucial for generalizable inference. In this paper, we present a series of empirical evidence from two large-scale multi-site replication studies to support a new role of covariate shift in ``predicting'' the strength of the unknown conditional shift. Analyzing 680 studies across 65 sites, we find that even though the conditional shift is non-negligible, its strength can often be bounded by that of the observable covariate shift. However, this pattern only emerges when the two sources of shifts are quantified by our proposed standardized, ``pivotal'' measures. We then interpret this phenomenon by connecting it to similar patterns that can be theoretically derived from a random distribution shift model. Finally, we demonstrate that exploiting the predictive role of covariate shift leads to reliable and efficient uncertainty quantification for target estimates in generalization tasks with partially observed data. Overall, our empirical and theoretical analyses suggest a new way to approach the problem of distributional shift, generalizability, and external validity.
Using Large Language Model Annotations for Valid Downstream Statistical Inference in Social Science: Design-Based Semi-Supervised Learning
Jun 07, 2023In computational social science (CSS), researchers analyze documents to explain social and political phenomena. In most scenarios, CSS researchers first obtain labels for documents and then explain labels using interpretable regression analyses in the second step. The recent advancements in large language models (LLMs) can lower costs for CSS research by annotating documents cheaply at scale, but such surrogate labels are often imperfect and biased. We present a new algorithm for using outputs from LLMs for downstream statistical analyses while guaranteeing statistical properties -- like asymptotic unbiasedness and proper uncertainty quantification -- which are fundamental to CSS research. We show that direct use of LLM-predicted surrogate labels in downstream statistical analyses leads to substantial bias and invalid confidence intervals, even with high surrogate accuracy of 80--90\%. To address this, we build on debiased machine learning to propose the design-based semi-supervised learning (DSL) estimator. DSL employs a doubly-robust procedure to combine surrogate labels with a smaller number of gold-standard labels. Our approach guarantees valid inference for downstream statistical analyses, even when surrogates are arbitrarily biased, without requiring stringent assumptions, by controlling the probability of sampling documents for gold-standard labeling. Both our theoretical analysis and experimental results show that DSL provides valid statistical inference while achieving root mean squared errors comparable to existing alternatives that focus only on prediction without statistical guarantees.
How to Make Causal Inferences Using Texts
Feb 06, 2018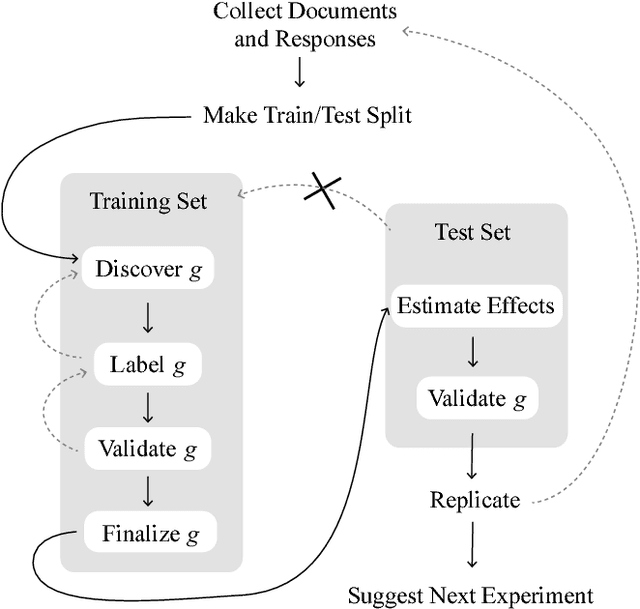
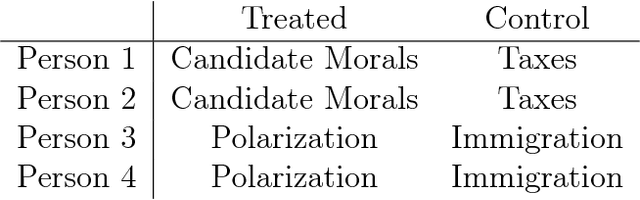

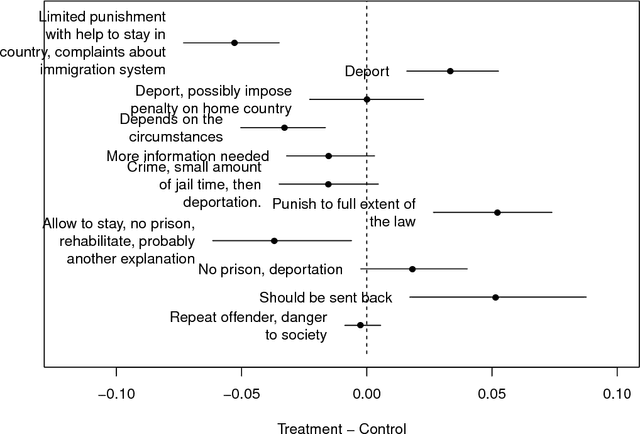
New text as data techniques offer a great promise: the ability to inductively discover measures that are useful for testing social science theories of interest from large collections of text. We introduce a conceptual framework for making causal inferences with discovered measures as a treatment or outcome. Our framework enables researchers to discover high-dimensional textual interventions and estimate the ways that observed treatments affect text-based outcomes. We argue that nearly all text-based causal inferences depend upon a latent representation of the text and we provide a framework to learn the latent representation. But estimating this latent representation, we show, creates new risks: we may introduce an identification problem or overfit. To address these risks we describe a split-sample framework and apply it to estimate causal effects from an experiment on immigration attitudes and a study on bureaucratic response. Our work provides a rigorous foundation for text-based causal inferences.