 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducing Sustained Creativity and Diversity in Large Language Models
Mar 19, 2026We address a not-widely-recognized subset of exploratory search, where a user sets out on a typically long "search quest" for the perfect wedding dress, overlooked research topic, killer company idea, etc. The first few outputs of current large language models (LLMs) may be helpful but only as a start, since the quest requires learning the search space and evaluating many diverse and creative alternatives along the way. Although LLMs encode an impressive fraction of the world's knowledge, common decoding methods are narrowly optimized for prompts with correct answers and thus return mostly homogeneous and conventional results. Other approaches, including those designed to increase diversity across a small set of answers, start to repeat themselves long before search quest users learn enough to make final choices, or offer a uniform type of "creativity" to every user asking similar questions. We develop a novel, easy-to-implement decoding scheme that induces sustained creativity and diversity in LLMs, producing as many conceptually unique results as desired, even without access to the inner workings of an LLM's vector space. The algorithm unlocks an LLM's vast knowledge, both orthodox and heterodox, well beyond modal decoding paths. With this approach, search quest users can more quickly explore the search space and find satisfying answers.
A Perspectival Mirror of the Elephant: Investigating Language Bias on Google, ChatGPT, Wikipedia, and YouTube
Mar 28, 2023



Contrary to Google Search's mission of delivering information from "many angles so you can form your own understanding of the world," we find that Google and its most prominent returned results -- Wikipedia and YouTube, simply reflect the narrow set of cultural stereotypes tied to the search language for complex topics like "Buddhism," "Liberalism," "colonization," "Iran" and "America." Simply stated, they present, to varying degrees, distinct information across the same search in different languages (we call it 'language bias'). Instead of presenting a global picture of a complex topic, our online searches turn us into the proverbial blind person touching a small portion of an elephant, ignorant of the existence of other cultural perspectives. The language we use to search ends up as a cultural filter to promote ethnocentric views, where a person evaluates other people or ideas based on their own culture. We also find that language bias is deeply embedded in ChatGPT. As it is primarily trained on English language data, it presents the Anglo-American perspective as the normative view, reducing the complexity of a multifaceted issue to the single Anglo-American standard. In this paper, we present evidence and analysis of language bias and discuss its larger social implications. Toward the end of the paper, we propose a potential framework of using automatic translation to leverage language bias and argue that the task of piecing together a genuine depiction of the elephant is a challenging and important endeavor that deserves a new area of research in NLP and requires collaboration with scholars from the humanities to create ethically sound and socially responsible technology together.
Influence via Ethos: On the Persuasive Power of Reputation in Deliberation Online
Jun 01, 2020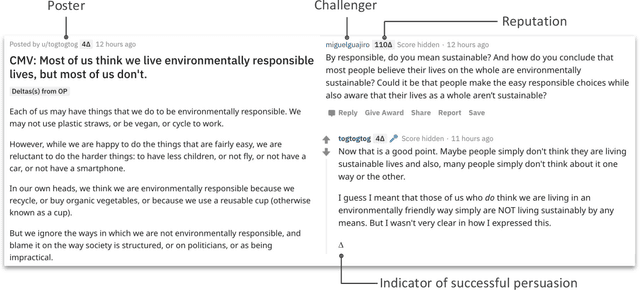
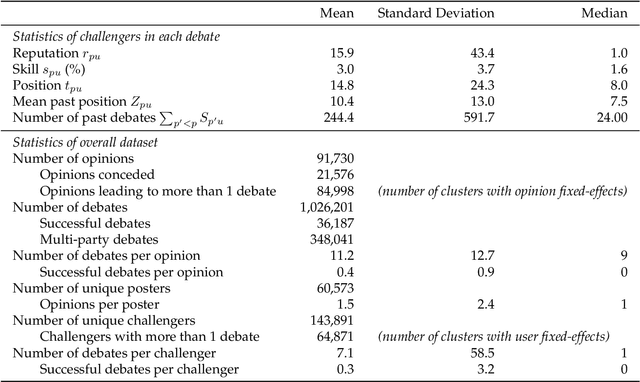
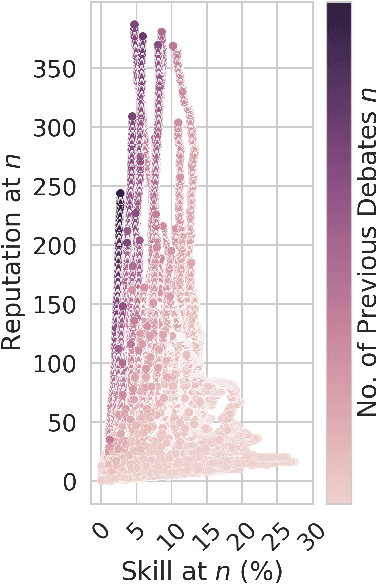
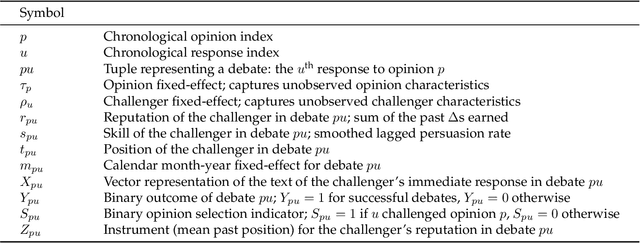
Deliberation among individuals online plays a key role in shaping the opinions that drive votes, purchases, donations and other critical offline behavior. Yet, the determinants of opinion-change via persuasion in deliberation online remain largely unexplored. Our research examines the persuasive power of $\textit{ethos}$ -- an individual's "reputation" -- using a 7-year panel of over a million debates from an argumentation platform containing explicit indicators of successful persuasion. We identify the causal effect of reputation on persuasion by constructing an instrument for reputation from a measure of past debate competition, and by controlling for unstructured argument text using neural models of language in the double machine-learning framework. We find that an individual's reputation significantly impacts their persuasion rate above and beyond the validity, strength and presentation of their arguments. In our setting, we find that having 10 additional reputation points causes a 31% increase in the probability of successful persuasion over the platform average. We also find that the impact of reputation is moderated by characteristics of the argument content, in a manner consistent with a theoretical model that attributes the persuasive power of reputation to heuristic information-processing under cognitive overload. We discuss managerial implications for platforms that facilitate deliberative decision-making for public and private organizations online.