 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLAS-multi: A Multilingual Corpus of Automatically Generated Natural Language Argumentation Schemes
Feb 22, 2024Some of the major limitations identified in the areas of argument mining, argument generation, and natural language argument analysis are related to the complexity of annotating argumentatively rich data, the limited size of these corpora, and the constraints that represent the different languages and domains in which these data is annotated. To address these limitations, in this paper we present the following contributions: (i) an effective methodology for the automatic generation of natural language arguments in different topics and languages, (ii) the largest publicly available corpus of natural language argumentation schemes, and (iii) a set of solid baselines and fine-tuned models for the automatic identification of argumentation schemes.
Knowledge-Enhanced Evidence Retrieval for Counterargument Generation
Sep 19, 2021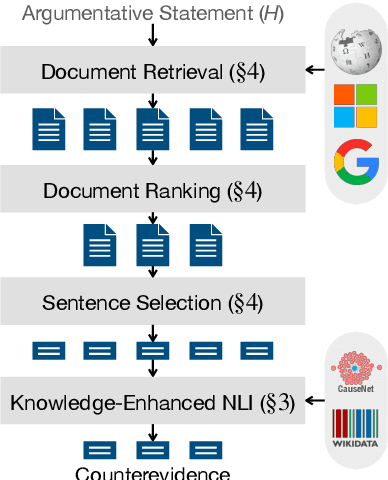

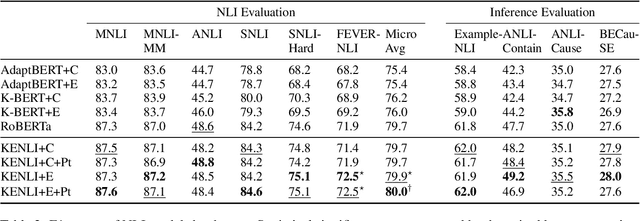
Finding counterevidence to statements is key to many tasks, including counterargument generation. We build a system that, given a statement, retrieves counterevidence from diverse sources on the Web. At the core of this system is a natural language inference (NLI) model that determines whether a candidate sentence is valid counterevidence or not. Most NLI models to date, however, lack proper reasoning abilities necessary to find counterevidence that involves complex inference. Thus, we present a knowledge-enhanced NLI model that aims to handle causality- and example-based inference by incorporating knowledge graphs. Our NLI model outperforms baselines for NLI tasks, especially for instances that require the targeted inference. In addition, this NLI model further improves the counterevidence retrieval system, notably finding complex counterevidence better.
Classifying Argumentative Relations Using Logical Mechanisms and Argumentation Schemes
May 17, 2021


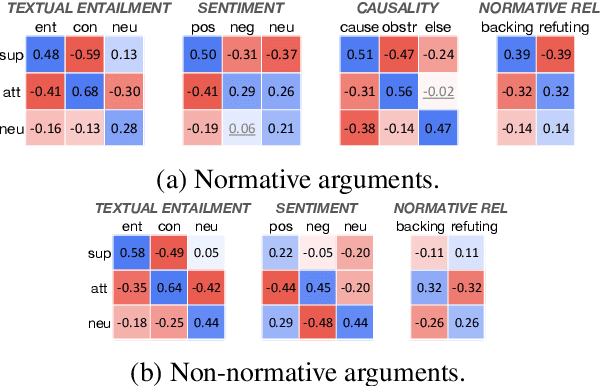
While argument mining has achieved significant success in classifying argumentative relations between statements (support, attack, and neutral), we have a limited computational understanding of logical mechanisms that constitute those relations. Most recent studies rely on black-box models, which are not as linguistically insightful as desired. On the other hand, earlier studies use rather simple lexical features, missing logical relations between statements. To overcome these limitations, our work classifies argumentative relations based on four logical and theory-informed mechanisms between two statements, namely (i) factual consistency, (ii) sentiment coherence, (iii) causal relation, and (iv) normative relation. We demonstrate that our operationalization of these logical mechanisms classifies argumentative relations without directly training on data labeled with the relations, significantly better than several unsupervised baselines. We further demonstrate that these mechanisms also improve supervised classifiers through representation learning.
Detecting Attackable Sentences in Arguments
Oct 06, 2020
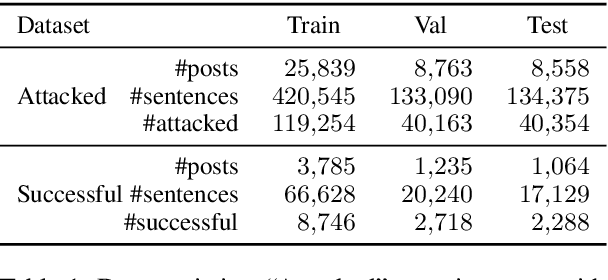


Finding attackable sentences in an argument is the first step toward successful refutation in argumentation. We present a first large-scale analysis of sentence attackability in online arguments. We analyze driving reasons for attacks in argumentation and identify relevant characteristics of sentences. We demonstrate that a sentence's attackability is associated with many of these characteristics regarding the sentence's content, proposition types, and tone, and that an external knowledge source can provide useful information about attackability. Building on these findings, we demonstrate that machine learning models can automatically detect attackable sentences in arguments, significantly better than several baselines and comparably well to laypeople.
Extracting Implicitly Asserted Propositions in Argumentation
Oct 06, 2020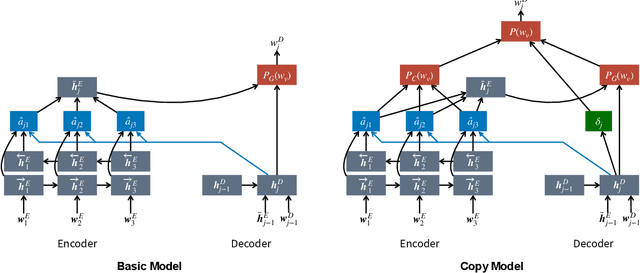
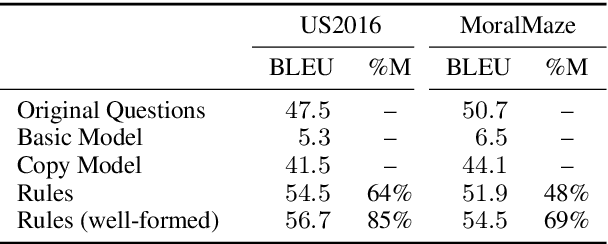
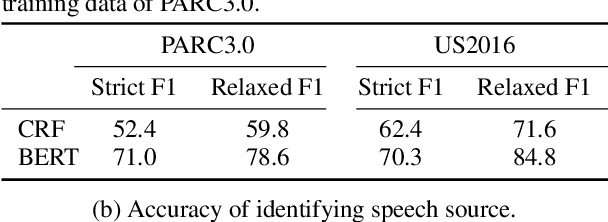
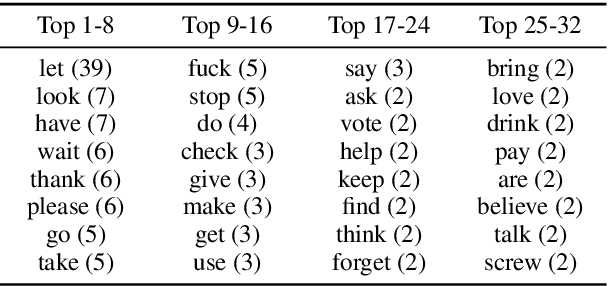
Argumentation accommodates various rhetorical devices, such as questions, reported speech, and imperatives. These rhetorical tools usually assert argumentatively relevant propositions rather implicitly, so understanding their true meaning is key to understanding certain arguments properly. However, most argument mining systems and computational linguistics research have paid little attention to implicitly asserted propositions in argumentation. In this paper, we examine a wide range of computational methods for extracting propositions that are implicitly asserted in questions, reported speech, and imperatives in argumentation. By evaluating the models on a corpus of 2016 U.S. presidential debates and online commentary, we demonstrate the effectiveness and limitations of the computational models. Our study may inform future research on argument mining and the semantics of these rhetorical devices in argumentation.
Multi-level computational methods for interdisciplinary research in the HathiTrust Digital Library
Jun 08, 2017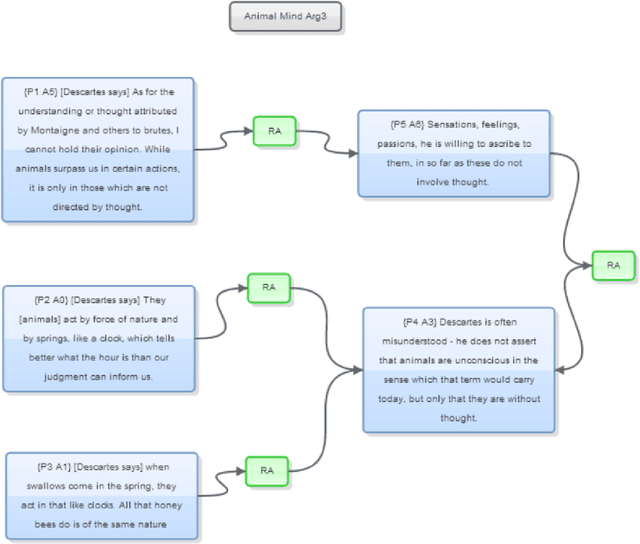
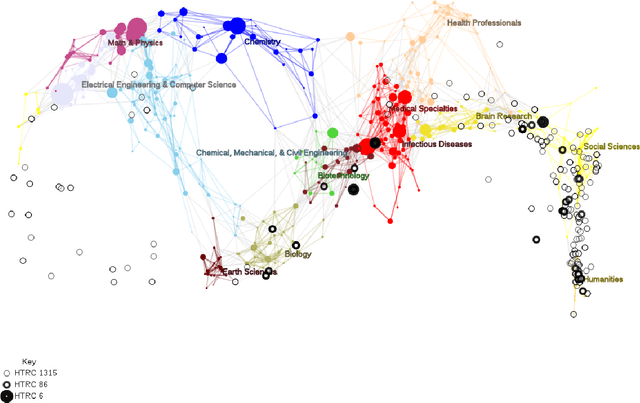

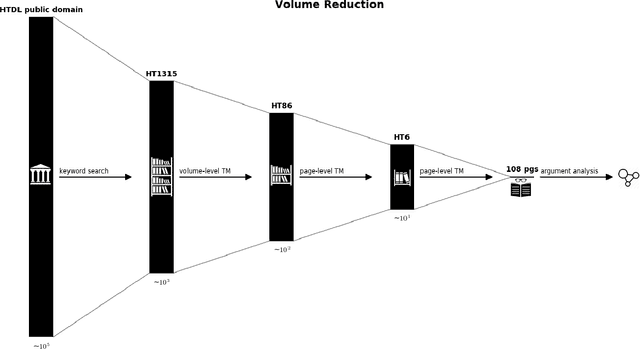
We show how faceted search using a combination of traditional classification systems and mixed-membership topic models can go beyond keyword search to inform resource discovery, hypothesis formulation, and argument extraction for interdisciplinary research. Our test domain is the history and philosophy of scientific work on animal mind and cognition. The methods can be generalized to other research areas and ultimately support a system for semi-automatic identification of argument structures. We provide a case study for the application of the methods to the problem of identifying and extracting arguments about anthropomorphism during a critical period in the development of comparative psychology. We show how a combination of classification systems and mixed-membership models trained over large digital libraries can inform resource discovery in this domain. Through a novel approach of "drill-down" topic modeling---simultaneously reducing both the size of the corpus and the unit of analysis---we are able to reduce a large collection of fulltext volumes to a much smaller set of pages within six focal volumes containing arguments of interest to historians and philosophers of comparative psychology. The volumes identified in this way did not appear among the first ten results of the keyword search in the HathiTrust digital library and the pages bear the kind of "close reading" needed to generate original interpretations that is the heart of scholarly work in the humanities. Zooming back out, we provide a way to place the books onto a map of science originally constructed from very different data and for different purposes. The multilevel approach advances understanding of the intellectual and societal contexts in which writings are interpreted.
Modelling Contractual Arguments
Jun 07, 2001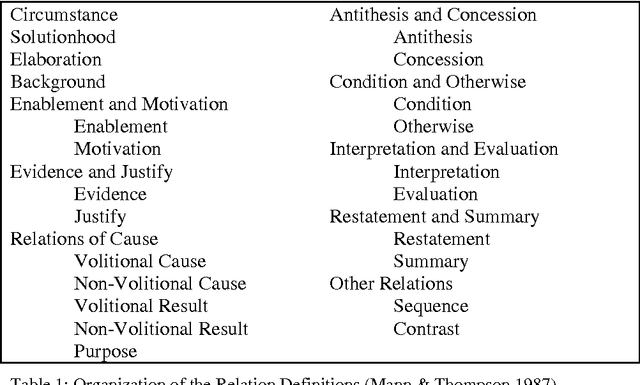
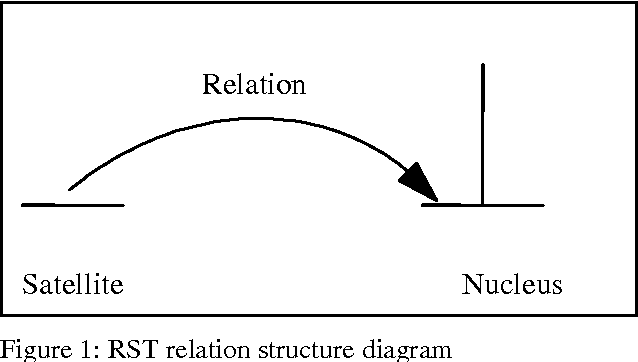
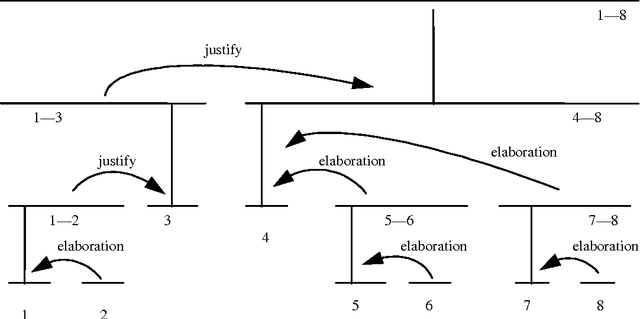

One influential approach to assessing the "goodness" of arguments is offered by the Pragma-Dialectical school (p-d) (Eemeren & Grootendorst 1992). This can be compared with Rhetorical Structure Theory (RST) (Mann & Thompson 1988), an approach that originates in discourse analysis. In p-d terms an argument is good if it avoids committing a fallacy, whereas in RST terms an argument is good if it is coherent. RST has been criticised (Snoeck Henkemans 1997) for providing only a partially functional account of argument, and similar criticisms have been raised in the Natural Language Generation (NLG) community-particularly by Moore & Pollack (1992)- with regards to its account of intentionality in text in general. Mann and Thompson themselves note that although RST can be successfully applied to a wide range of texts from diverse domains, it fails to characterise some types of text, most notably legal contracts. There is ongoing research in the Artificial Intelligence and Law community exploring the potential for providing electronic support to contract negotiators, focusing on long-term, complex engineering agreements (see for example Daskalopulu & Sergot 1997). This paper provides a brief introduction to RST and illustrates its shortcomings with respect to contractual text. An alternative approach for modelling argument structure is presented which not only caters for contractual text, but also overcomes the aforementioned limitations of RST.