 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Explainable Framework for Misinformation Identification via Critical Question Answering
Mar 18, 2025Natural language misinformation detection approaches have been, to date, largely dependent on sequence classification methods, producing opaque systems in which the reasons behind classification as misinformation are unclear. While an effort has been made in the area of automated fact-checking to propose explainable approaches to the problem, this is not the case for automated reason-checking systems. In this paper, we propose a new explainable framework for both factual and rational misinformation detection based on the theory of Argumentation Schemes and Critical Questions. For that purpose, we create and release NLAS-CQ, the first corpus combining 3,566 textbook-like natural language argumentation scheme instances and 4,687 corresponding answers to critical questions related to these arguments. On the basis of this corpus, we implement and validate our new framework which combines classification with question answering to analyse arguments in search of misinformation, and provides the explanations in form of critical questions to the human user.
NLAS-multi: A Multilingual Corpus of Automatically Generated Natural Language Argumentation Schemes
Feb 22, 2024Some of the major limitations identified in the areas of argument mining, argument generation, and natural language argument analysis are related to the complexity of annotating argumentatively rich data, the limited size of these corpora, and the constraints that represent the different languages and domains in which these data is annotated. To address these limitations, in this paper we present the following contributions: (i) an effective methodology for the automatic generation of natural language arguments in different topics and languages, (ii) the largest publicly available corpus of natural language argumentation schemes, and (iii) a set of solid baselines and fine-tuned models for the automatic identification of argumentation schemes.
Multi-level computational methods for interdisciplinary research in the HathiTrust Digital Library
Jun 08, 2017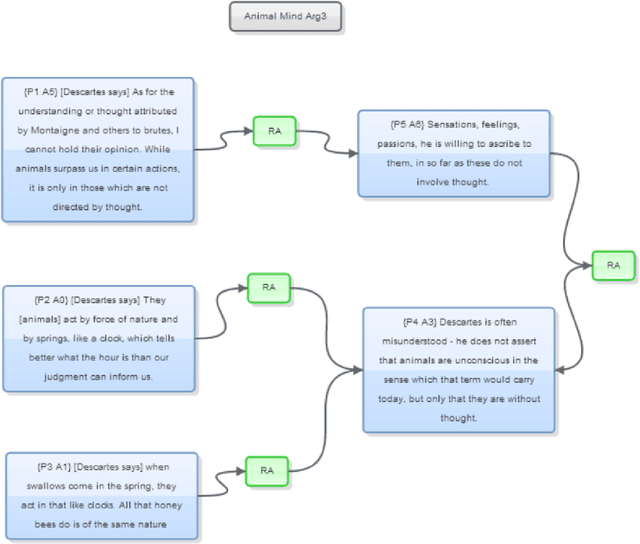
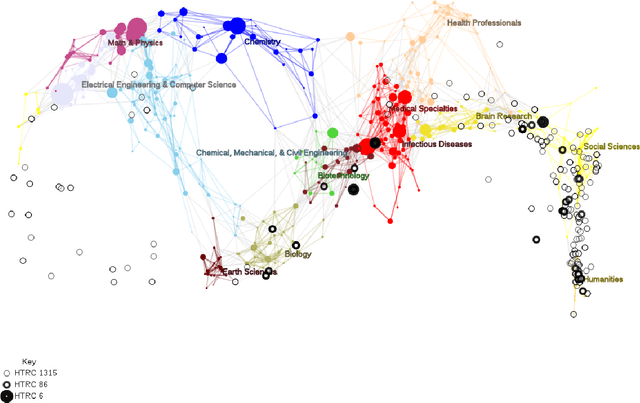

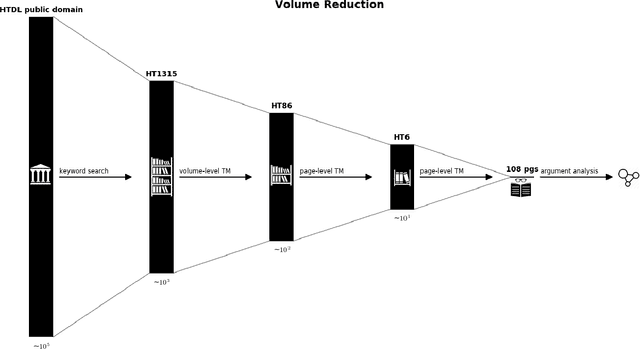
We show how faceted search using a combination of traditional classification systems and mixed-membership topic models can go beyond keyword search to inform resource discovery, hypothesis formulation, and argument extraction for interdisciplinary research. Our test domain is the history and philosophy of scientific work on animal mind and cognition. The methods can be generalized to other research areas and ultimately support a system for semi-automatic identification of argument structures. We provide a case study for the application of the methods to the problem of identifying and extracting arguments about anthropomorphism during a critical period in the development of comparative psychology. We show how a combination of classification systems and mixed-membership models trained over large digital libraries can inform resource discovery in this domain. Through a novel approach of "drill-down" topic modeling---simultaneously reducing both the size of the corpus and the unit of analysis---we are able to reduce a large collection of fulltext volumes to a much smaller set of pages within six focal volumes containing arguments of interest to historians and philosophers of comparative psychology. The volumes identified in this way did not appear among the first ten results of the keyword search in the HathiTrust digital library and the pages bear the kind of "close reading" needed to generate original interpretations that is the heart of scholarly work in the humanities. Zooming back out, we provide a way to place the books onto a map of science originally constructed from very different data and for different purposes. The multilevel approach advances understanding of the intellectual and societal contexts in which writings are interpreted.