 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning Framework for Cost-Effective TCR-Epitope Binding Affinity Prediction
Oct 30, 2023



T cell receptors (TCRs) are critical components of adaptive immune systems, responsible for responding to threats by recognizing epitope sequences presented on host cell surface. Computational prediction of binding affinity between TCRs and epitope sequences using machine/deep learning has attracted intense attention recently. However, its success is hindered by the lack of large collections of annotated TCR-epitope pairs. Annotating their binding affinity requires expensive and time-consuming wet-lab evaluation. To reduce annotation cost, we present ActiveTCR, a framework that incorporates active learning and TCR-epitope binding affinity prediction models. Starting with a small set of labeled training pairs, ActiveTCR iteratively searches for unlabeled TCR-epitope pairs that are ''worth'' for annotation. It aims to maximize performance gains while minimizing the cost of annotation. We compared four query strategies with a random sampling baseline and demonstrated that ActiveTCR reduces annotation costs by approximately 40%. Furthermore, we showed that providing ground truth labels of TCR-epitope pairs to query strategies can help identify and reduce more than 40% redundancy among already annotated pairs without compromising model performance, enabling users to train equally powerful prediction models with less training data. Our work is the first systematic investigation of data optimization for TCR-epitope binding affinity prediction.
Classifying Argumentative Relations Using Logical Mechanisms and Argumentation Schemes
May 17, 2021


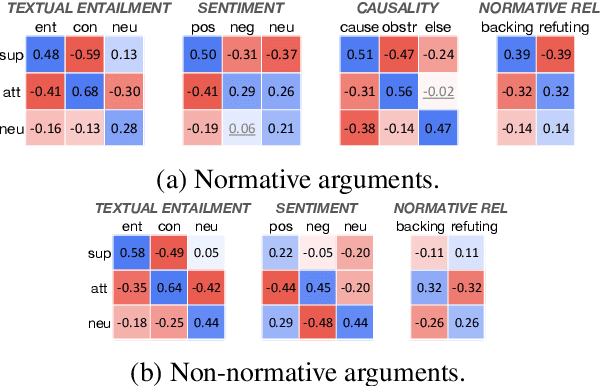
While argument mining has achieved significant success in classifying argumentative relations between statements (support, attack, and neutral), we have a limited computational understanding of logical mechanisms that constitute those relations. Most recent studies rely on black-box models, which are not as linguistically insightful as desired. On the other hand, earlier studies use rather simple lexical features, missing logical relations between statements. To overcome these limitations, our work classifies argumentative relations based on four logical and theory-informed mechanisms between two statements, namely (i) factual consistency, (ii) sentiment coherence, (iii) causal relation, and (iv) normative relation. We demonstrate that our operationalization of these logical mechanisms classifies argumentative relations without directly training on data labeled with the relations, significantly better than several unsupervised baselines. We further demonstrate that these mechanisms also improve supervised classifiers through representation learning.
Detecting Attackable Sentences in Arguments
Oct 06, 2020
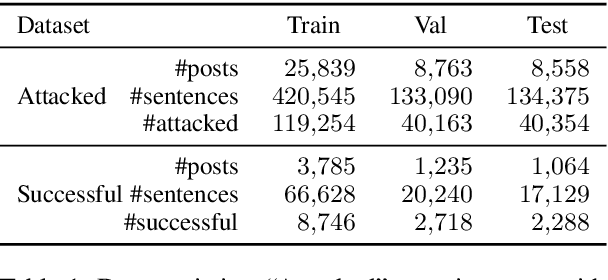


Finding attackable sentences in an argument is the first step toward successful refutation in argumentation. We present a first large-scale analysis of sentence attackability in online arguments. We analyze driving reasons for attacks in argumentation and identify relevant characteristics of sentences. We demonstrate that a sentence's attackability is associated with many of these characteristics regarding the sentence's content, proposition types, and tone, and that an external knowledge source can provide useful information about attackability. Building on these findings, we demonstrate that machine learning models can automatically detect attackable sentences in arguments, significantly better than several baselines and comparably well to laypeople.
Dropout Prediction over Weeks in MOOCs via Interpretable Multi-Layer Representation Learning
Feb 05, 2020
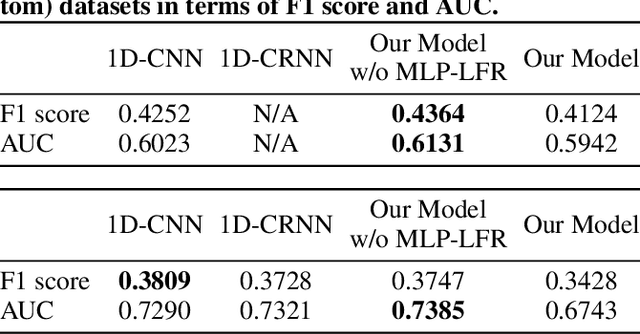
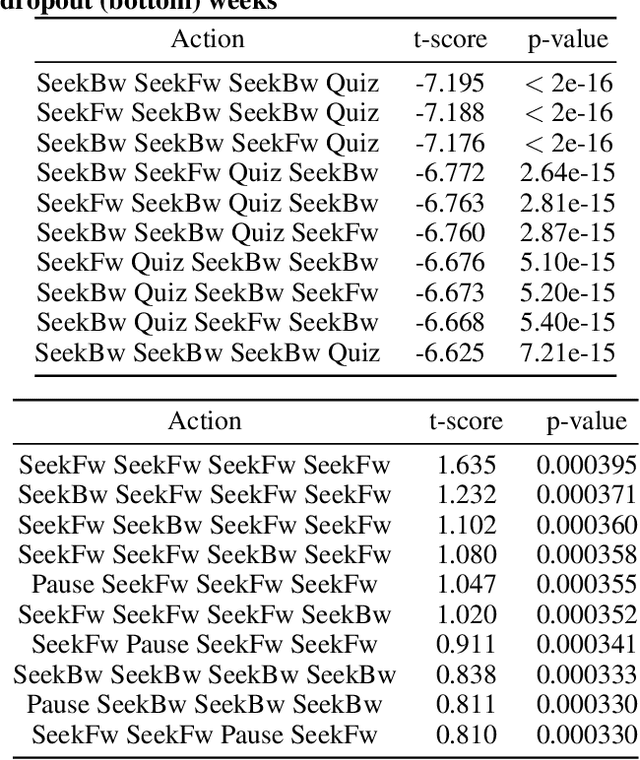
Massive Open Online Courses (MOOCs) have become popular platforms for online learning. While MOOCs enable students to study at their own pace, this flexibility makes it easy for students to drop out of class. In this paper, our goal is to predict if a learner is going to drop out within the next week, given clickstream data for the current week. To this end, we present a multi-layer representation learning solution based on branch and bound (BB) algorithm, which learns from low-level clickstreams in an unsupervised manner, produces interpretable results, and avoids manual feature engineering. In experiments on Coursera data, we show that our model learns a representation that allows a simple model to perform similarly well to more complex, task-specific models, and how the BB algorithm enables interpretable results. In our analysis of the observed limitations, we discuss promising future directions.
Explaining a black-box using Deep Variational Information Bottleneck Approach
Feb 19, 2019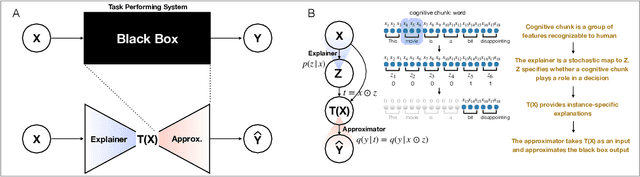
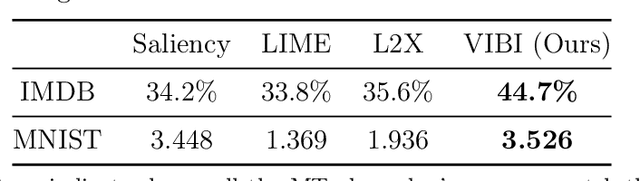

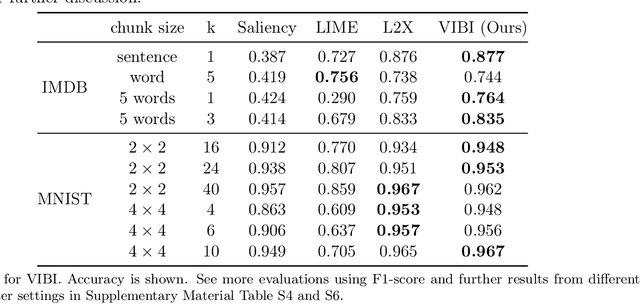
Briefness and comprehensiveness are necessary in order to give a lot of information concisely in explaining a black-box decision system. However, existing interpretable machine learning methods fail to consider briefness and comprehensiveness simultaneously, which may lead to redundant explanations. We propose a system-agnostic interpretable method that provides a brief but comprehensive explanation by adopting the inspiring information theoretic principle, information bottleneck principle. Using an information theoretic objective, VIBI selects instance-wise key features that are maximally compressed about an input (briefness), and informative about a decision made by a black-box on that input (comprehensive). The selected key features act as an information bottleneck that serves as a concise explanation for each black-box decision. We show that VIBI outperforms other interpretable machine learning methods in terms of both interpretability and fidelity evaluated by human and quantitative metrics.
Multiple Kernel $k$-means Clustering using Min-Max Optimization with $l_2$ Regularization
Mar 06, 2018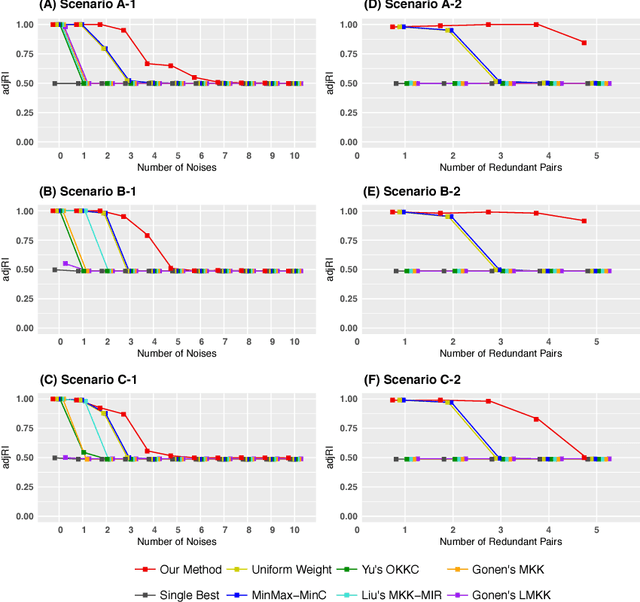
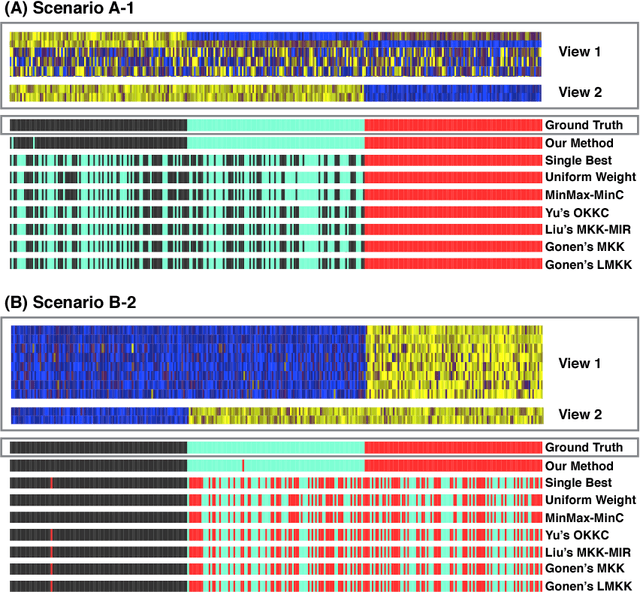
As various types of biomedical data become available, multiple kernel learning approaches have been proposed to incorporate abundant yet diverse information collected from multiple sources (or views) to facilitate disease prediction and pattern recognition. Although supervised multiple kernel learning has been extensively studied, until recently, only a few unsupervised approaches have been proposed. Moreover, the existing unsupervised approaches are unable to effectively utilize useful and complementary information especially when signals in some views are weak. We propose a novel multiple kernel $k$-means clustering method which aims to effectively use complementary information from multiple views to identify clusters. It is achieved by optimizing the unsupervised problem using a $\min_{\mathbf{H}}$-$\max_{\mathbf{\theta}}$ formulation, such that more weights can be assigned to views having weak signal for cluster identification. Moreover, our method avoids dismissing views with informative but weak signals by imposing $l_2$ constraint. Additionally, it allows to distill biological prior knowledge on the clustering by imposing a linear constraint on the kernel coefficients. To evaluate our method, we compare it with seven other clustering approaches on simulated multiview data. The simulation results show that our method outperforms existing clustering approaches especially when there is noise and redundancy in the data.