 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText and Causal Inference: A Review of Using Text to Remove Confounding from Causal Estimates
Paper and Code
May 01, 2020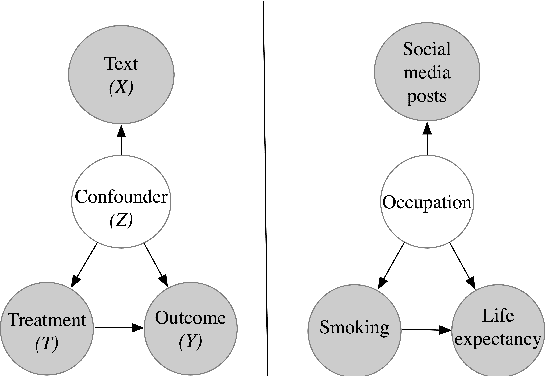
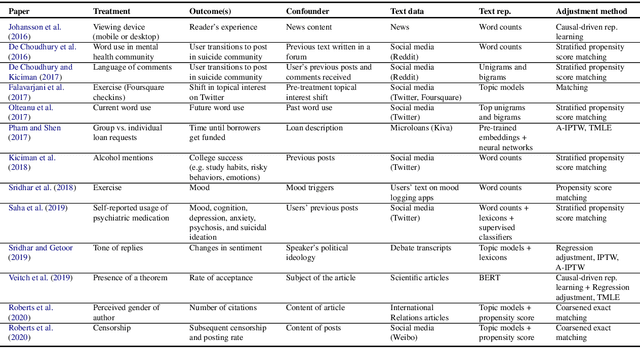
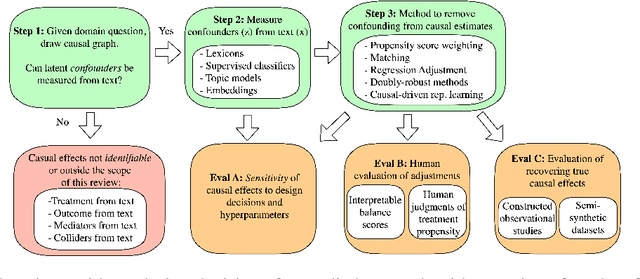

Many applications of computational social science aim to infer causal conclusions from non-experimental data. Such observational data often contains confounders, variables that influence both potential causes and potential effects. Unmeasured or latent confounders can bias causal estimates, and this has motivated interest in measuring potential confounders from observed text. For example, an individual's entire history of social media posts or the content of a news article could provide a rich measurement of multiple confounders. Yet, methods and applications for this problem are scattered across different communities and evaluation practices are inconsistent. This review is the first to gather and categorize these examples and provide a guide to data-processing and evaluation decisions. Despite increased attention on adjusting for confounding using text, there are still many open problems, which we highlight in this paper.