 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRESTOR: Knowledge Recovery through Machine Unlearning
Paper and Code
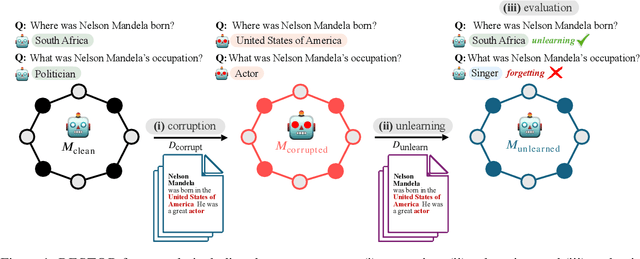

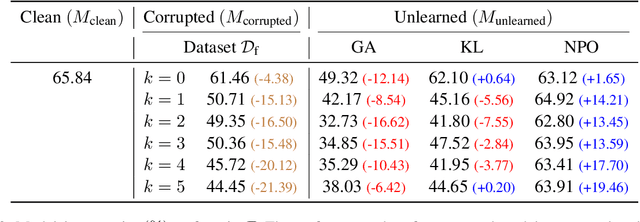
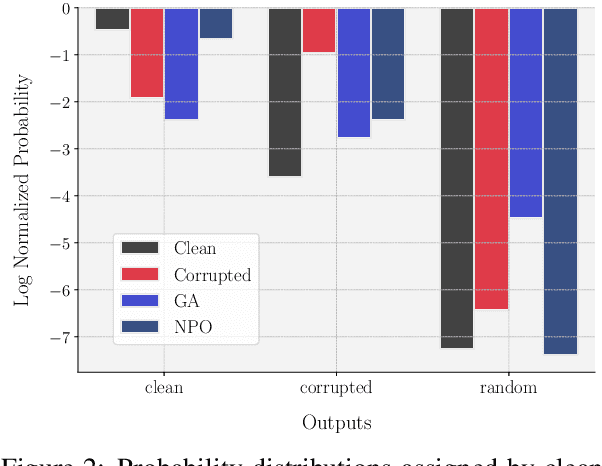
Large language models trained on web-scale corpora can memorize undesirable datapoints such as incorrect facts, copyrighted content or sensitive data. Recently, many machine unlearning methods have been proposed that aim to 'erase' these datapoints from trained models -- that is, revert model behavior to be similar to a model that had never been trained on these datapoints. However, evaluating the success of unlearning algorithms remains challenging. In this work, we propose the RESTOR framework for machine unlearning based on the following dimensions: (1) a task setting that focuses on real-world factual knowledge, (2) a variety of corruption scenarios that emulate different kinds of datapoints that might need to be unlearned, and (3) evaluation metrics that emphasize not just forgetting undesirable knowledge, but also recovering the model's original state before encountering these datapoints, or restorative unlearning. RESTOR helps uncover several novel insights about popular unlearning algorithms, and the mechanisms through which they operate -- for instance, identifying that some algorithms merely emphasize forgetting the knowledge to be unlearned, and that localizing unlearning targets can enhance unlearning performance. Code/data is available at github.com/k1rezaei/restor.