 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopicBERT for Energy Efficient Document Classification
Oct 15, 2020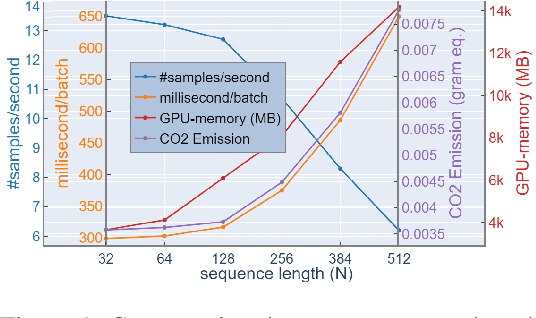


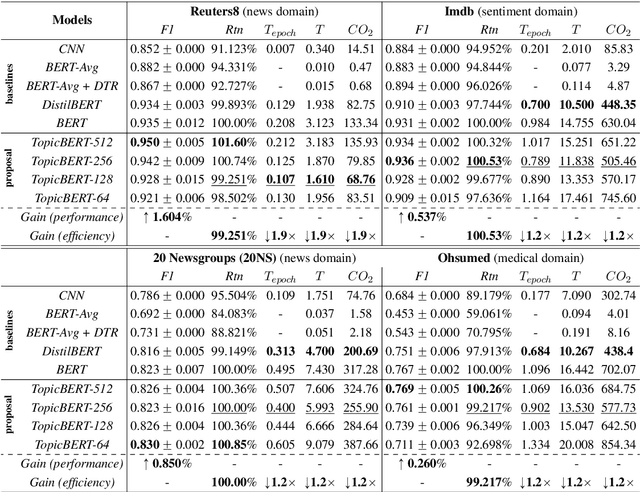
Prior research notes that BERT's computational cost grows quadratically with sequence length thus leading to longer training times, higher GPU memory constraints and carbon emissions. While recent work seeks to address these scalability issues at pre-training, these issues are also prominent in fine-tuning especially for long sequence tasks like document classification. Our work thus focuses on optimizing the computational cost of fine-tuning for document classification. We achieve this by complementary learning of both topic and language models in a unified framework, named TopicBERT. This significantly reduces the number of self-attention operations - a main performance bottleneck. Consequently, our model achieves a 1.4x ($\sim40\%$) speedup with $\sim40\%$ reduction in $CO_2$ emission while retaining $99.9\%$ performance over 5 datasets.
Neural Architectures for Fine-Grained Propaganda Detection in News
Sep 13, 2019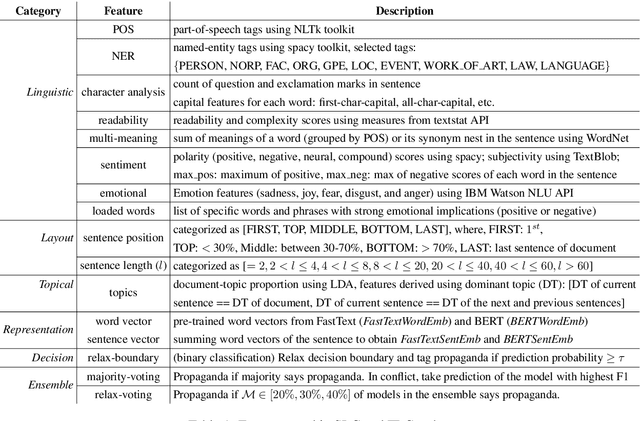
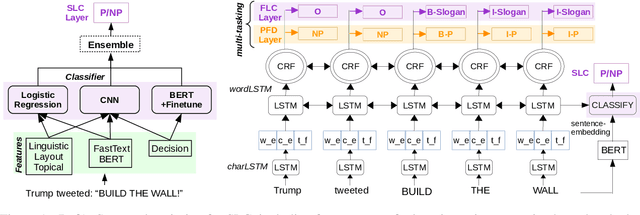
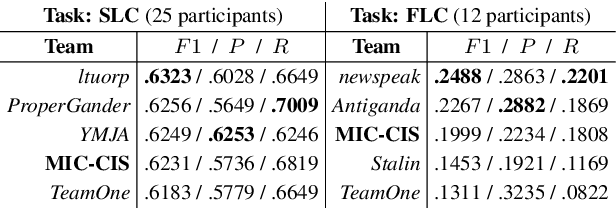
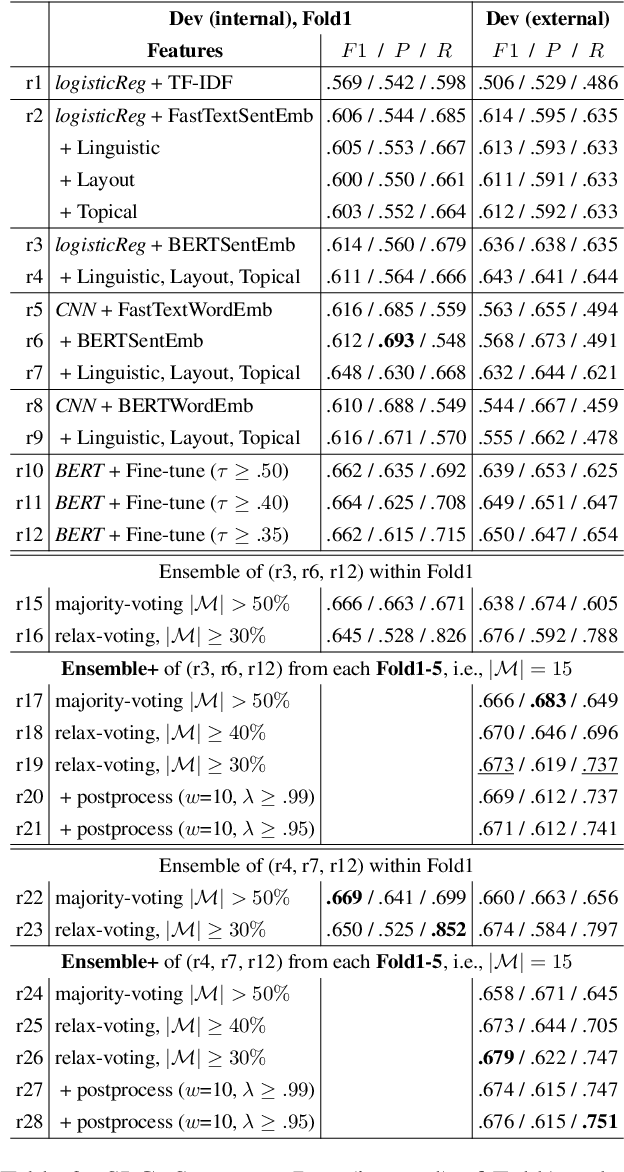
This paper describes our system (MIC-CIS) details and results of participation in the fine-grained propaganda detection shared task 2019. To address the tasks of sentence (SLC) and fragment level (FLC) propaganda detection, we explore different neural architectures (e.g., CNN, LSTM-CRF and BERT) and extract linguistic (e.g., part-of-speech, named entity, readability, sentiment, emotion, etc.), layout and topical features. Specifically, we have designed multi-granularity and multi-tasking neural architectures to jointly perform both the sentence and fragment level propaganda detection. Additionally, we investigate different ensemble schemes such as majority-voting, relax-voting, etc. to boost overall system performance. Compared to the other participating systems, our submissions are ranked 3rd and 4th in FLC and SLC tasks, respectively.