 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Pretraining for Multilingual Acronym Extraction
Jun 30, 2022

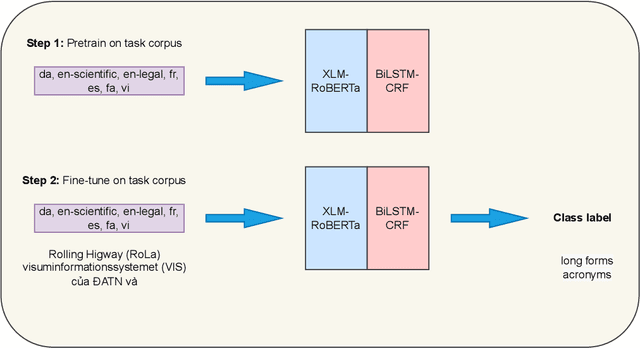
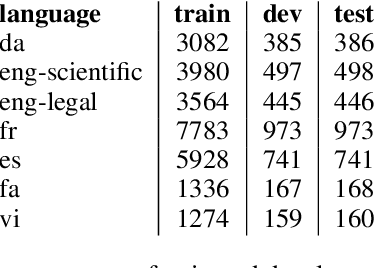
This paper presents our findings from participating in the multilingual acronym extraction shared task SDU@AAAI-22. The task consists of acronym extraction from documents in 6 languages within scientific and legal domains. To address multilingual acronym extraction we employed BiLSTM-CRF with multilingual XLM-RoBERTa embeddings. We pretrained the XLM-RoBERTa model on the shared task corpus to further adapt XLM-RoBERTa embeddings to the shared task domain(s). Our system (team: SMR-NLP) achieved competitive performance for acronym extraction across all the languages.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Data Augmentation for Low-Resource Named Entity Recognition Using Backtranslation
Aug 26, 2021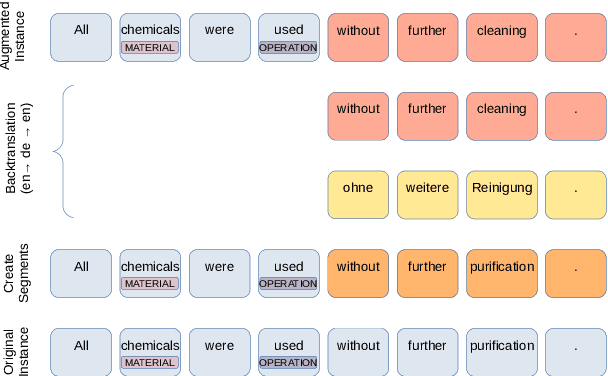
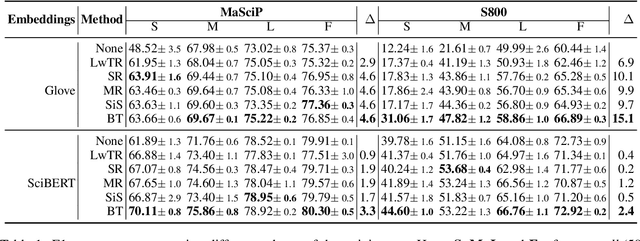
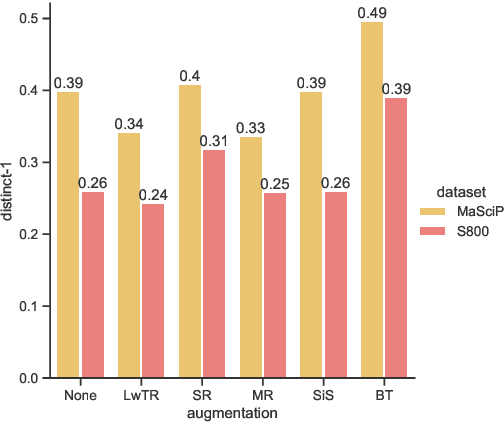
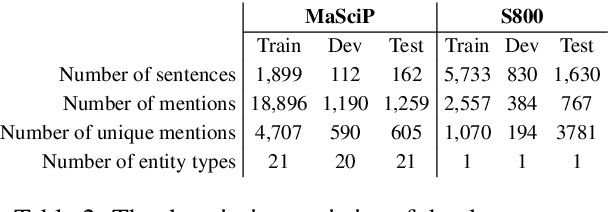
The state of art natural language processing systems relies on sizable training datasets to achieve high performance. Lack of such datasets in the specialized low resource domains lead to suboptimal performance. In this work, we adapt backtranslation to generate high quality and linguistically diverse synthetic data for low-resource named entity recognition. We perform experiments on two datasets from the materials science (MaSciP) and biomedical domains (S800). The empirical results demonstrate the effectiveness of our proposed augmentation strategy, particularly in the low-resource scenario.
Neural Text Classification and Stacked Heterogeneous Embeddings for Named Entity Recognition in SMM4H 2021
Jun 11, 2021
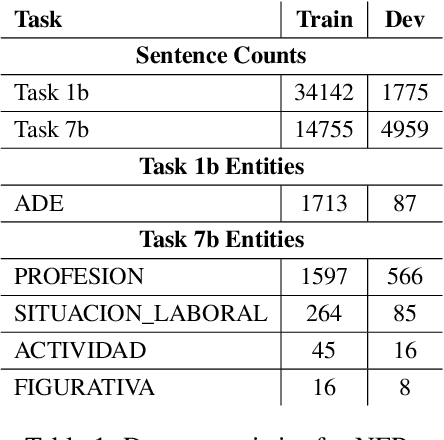
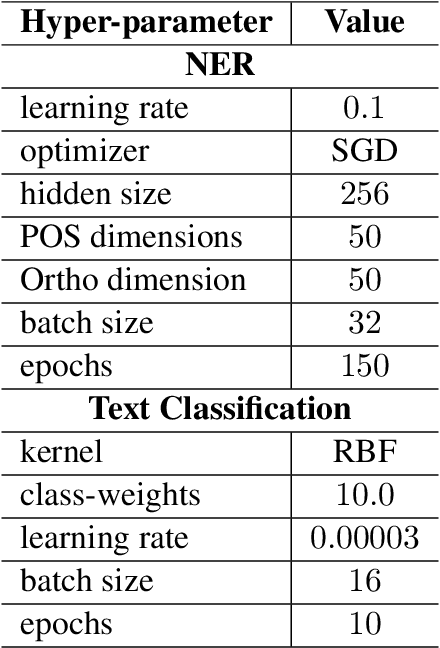
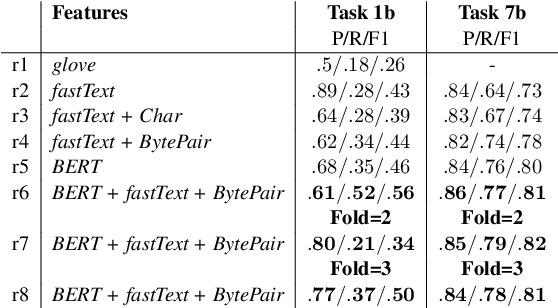
This paper presents our findings from participating in the SMM4H Shared Task 2021. We addressed Named Entity Recognition (NER) and Text Classification. To address NER we explored BiLSTM-CRF with Stacked Heterogeneous Embeddings and linguistic features. We investigated various machine learning algorithms (logistic regression, Support Vector Machine (SVM) and Neural Networks) to address text classification. Our proposed approaches can be generalized to different languages and we have shown its effectiveness for English and Spanish. Our text classification submissions (team:MIC-NLP) have achieved competitive performance with F1-score of $0.46$ and $0.90$ on ADE Classification (Task 1a) and Profession Classification (Task 7a) respectively. In the case of NER, our submissions scored F1-score of $0.50$ and $0.82$ on ADE Span Detection (Task 1b) and Profession Span detection (Task 7b) respectively.
Linguistically Informed Relation Extraction and Neural Architectures for Nested Named Entity Recognition in BioNLP-OST 2019
Oct 08, 2019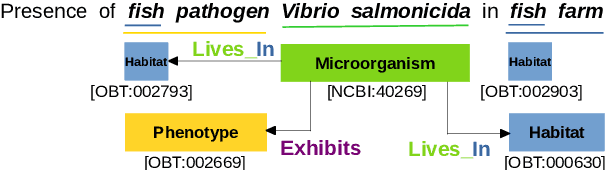
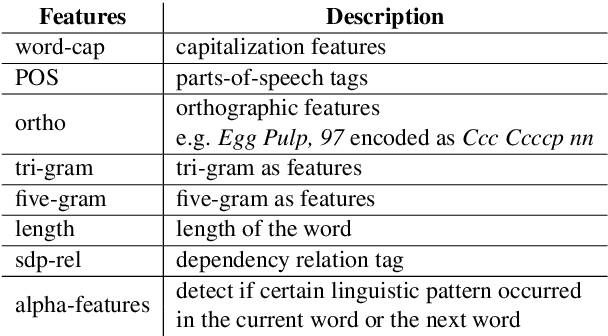
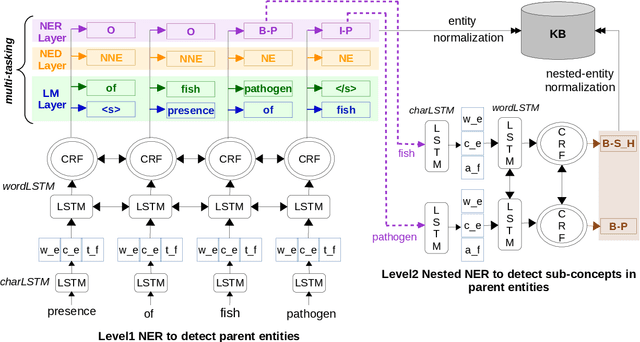
Named Entity Recognition (NER) and Relation Extraction (RE) are essential tools in distilling knowledge from biomedical literature. This paper presents our findings from participating in BioNLP Shared Tasks 2019. We addressed Named Entity Recognition including nested entities extraction, Entity Normalization and Relation Extraction. Our proposed approach of Named Entities can be generalized to different languages and we have shown it's effectiveness for English and Spanish text. We investigated linguistic features, hybrid loss including ranking and Conditional Random Fields (CRF), multi-task objective and token-level ensembling strategy to improve NER. We employed dictionary based fuzzy and semantic search to perform Entity Normalization. Finally, our RE system employed Support Vector Machine (SVM) with linguistic features. Our NER submission (team:MIC-CIS) ranked first in BB-2019 norm+NER task with standard error rate (SER) of 0.7159 and showed competitive performance on PharmaCo NER task with F1-score of 0.8662. Our RE system ranked first in the SeeDev-binary Relation Extraction Task with F1-score of 0.3738.
Neural Architectures for Fine-Grained Propaganda Detection in News
Sep 13, 2019
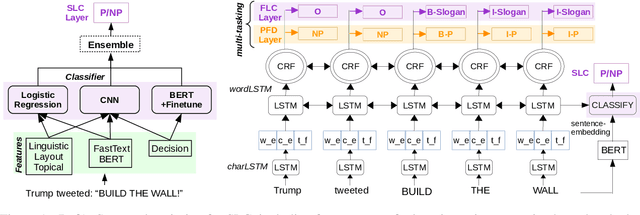
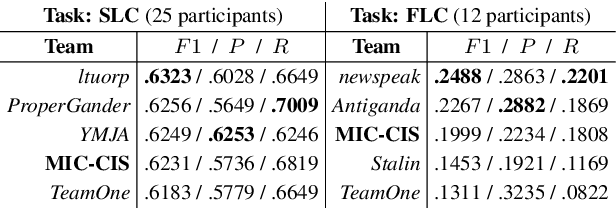
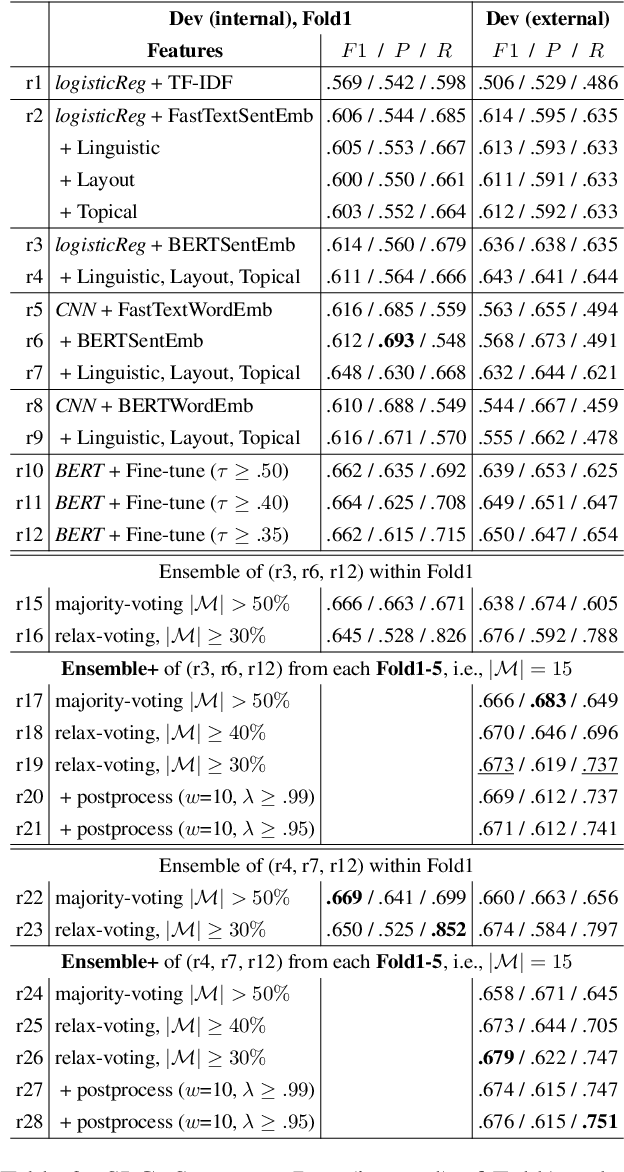
This paper describes our system (MIC-CIS) details and results of participation in the fine-grained propaganda detection shared task 2019. To address the tasks of sentence (SLC) and fragment level (FLC) propaganda detection, we explore different neural architectures (e.g., CNN, LSTM-CRF and BERT) and extract linguistic (e.g., part-of-speech, named entity, readability, sentiment, emotion, etc.), layout and topical features. Specifically, we have designed multi-granularity and multi-tasking neural architectures to jointly perform both the sentence and fragment level propaganda detection. Additionally, we investigate different ensemble schemes such as majority-voting, relax-voting, etc. to boost overall system performance. Compared to the other participating systems, our submissions are ranked 3rd and 4th in FLC and SLC tasks, respectively.