 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistically Informed Relation Extraction and Neural Architectures for Nested Named Entity Recognition in BioNLP-OST 2019
Paper and Code
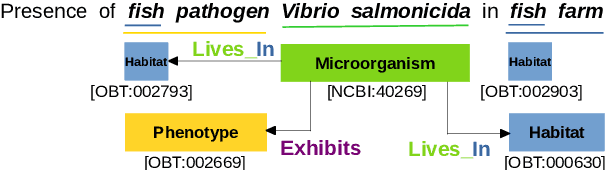
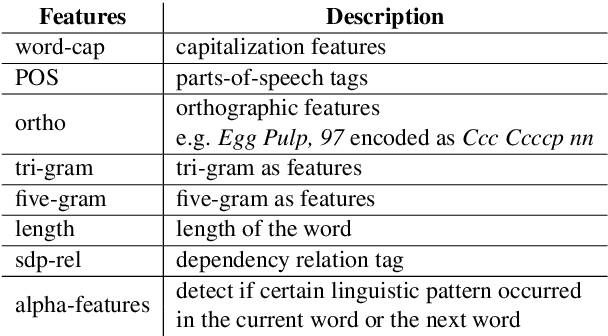
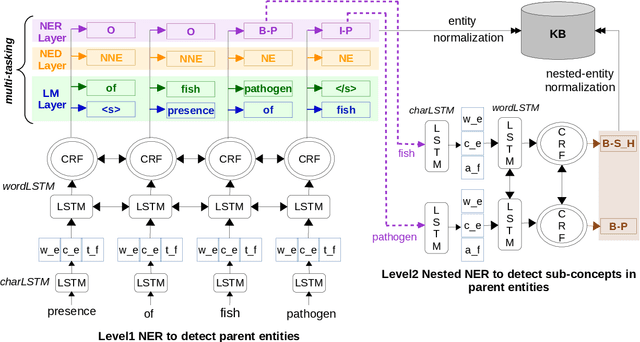
Named Entity Recognition (NER) and Relation Extraction (RE) are essential tools in distilling knowledge from biomedical literature. This paper presents our findings from participating in BioNLP Shared Tasks 2019. We addressed Named Entity Recognition including nested entities extraction, Entity Normalization and Relation Extraction. Our proposed approach of Named Entities can be generalized to different languages and we have shown it's effectiveness for English and Spanish text. We investigated linguistic features, hybrid loss including ranking and Conditional Random Fields (CRF), multi-task objective and token-level ensembling strategy to improve NER. We employed dictionary based fuzzy and semantic search to perform Entity Normalization. Finally, our RE system employed Support Vector Machine (SVM) with linguistic features. Our NER submission (team:MIC-CIS) ranked first in BB-2019 norm+NER task with standard error rate (SER) of 0.7159 and showed competitive performance on PharmaCo NER task with F1-score of 0.8662. Our RE system ranked first in the SeeDev-binary Relation Extraction Task with F1-score of 0.3738.